Scrapy简明教程(四)——爬取CSDN博客专家所有博文并存入MongoDB
首先,我们来看一下CSDN博客专家的链接: http://blog.csdn.net/experts.html
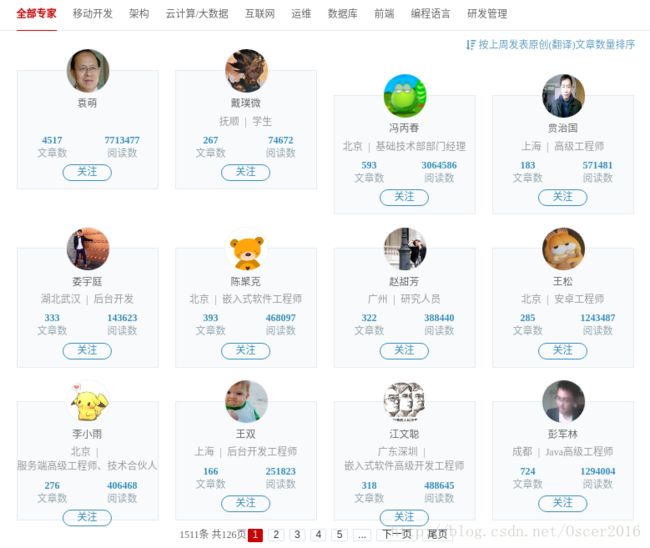
上图为 CSDN 所有博客专家页面,点击下一页后发现每次 url 都不会改变,但是已经翻页了,检查网页元素如下图:
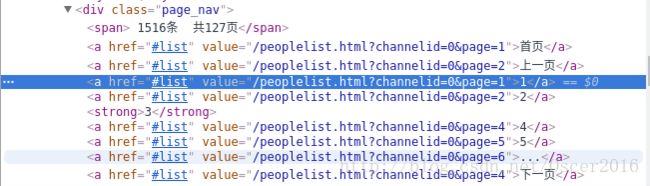
我们发现可以通过 value 值来构造 url 实现翻页,&page=1代表第一页,先来看一下构造的 CSDN 博客专家首页: http://blog.csdn.net/peoplelist.html?channelid=0&page=1,没有了刚才炫酷的样式,但是并不影响我们爬取数据。

这里,我们随机访问一位博主的首页,然后点击下一页:
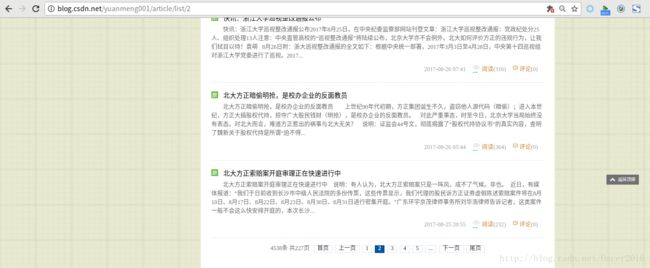
可以发现 list 后面的数字就是页码,通过它可以构造博主所有文章翻页 url,然后爬取每页博文 url,最后爬取博文详情页信息。下面开始编写爬虫,创建项目请参考:Scrapy简明教程(二)——开启Scrapy爬虫项目之旅,下面直接讲编写其他组件:
1. 编写 settings.py :
设置用户代理,解除 ITEM_PIPELINES 注释,用户代理可在审查元素中查看:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
ITEM_PIPELINES = {
'csdnblog.pipelines.CsdnblogPipeline': 300,
}
2. 编写要抽取的数据域 (items.py) :
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnblogItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
url = scrapy.Field()
releaseTime = scrapy.Field()
readnum = scrapy.Field()
article = scrapy.Field()
keywords = scrapy.Field()3. 编写 piplines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines heremZ#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
from pymongo import MongoClient
class CsdnblogPipeline(object):
def __init__(self):
self.client = MongoClient('localhost', 27017)
mdb = self.client['csdnblog']
self.collection = mdb['csdnblog']
def process_item(self, item, spider):
data = dict(item)
self.collection.insert(data)
return item
def close_spider(self, spider):
self.client.close()4. 编写爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import re
import urllib2
import lxml.html
import math
import jieba
import jieba.analyse
from optparse import OptionParser
from docopt import docopt
from scrapy.http import Request
from csdnblog.items import CsdnblogItem
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class SpiderCsdnblogSpider(scrapy.Spider):
name = "spider_csdnblog"
allowed_domains = ["csdn.net"]
start_urls = ['http://blog.csdn.net/peoplelist.html?channelid=0&page=1']
def parse(self, response):
# 从所有博客专家首页开始抓取
data = response.xpath('/html/body/div/span/text()').extract()[0]
# 抓取页码
pages = re.findall('共(.*?)页', str(data))[0]
for i in range(0, int(pages)):
# 构造博客专家翻页url
purl = 'http://blog.csdn.net/peoplelist.html?channelid=0&page=' + str(i+1)
yield Request(url=purl, callback=self.blogger)
def blogger(self, response):
# 爬取当前页博客专家url
bloggers = response.xpath('/html/body/dl/dd/a/@href').extract()
for burl in bloggers:
yield Request(url=burl, callback=self.total)
def total(self, response):
data = response.xpath('//*[@id="papelist"]/span/text()').extract()[0]
pages = re.findall('共(.*?)页',str(data))
for i in range(0, int(pages[0])):
# 构造博客专家所有博文翻页url
purl = str(response.url) + '/article/list/' + str(i+1)
yield Request(url= purl, callback=self.article)
def article(self, response):
# 爬取博主当前页所有文章url
articles = response.xpath('//span[@class="link_title"]/a/@href').extract()
for aurl in articles:
url = "http://blog.csdn.net" + aurl
yield Request(url=url, callback=self.detail)
def detail(self, response):
item = CsdnblogItem()
# 爬取博文详情页信息
item['url'] = response.url
# 新版主题CSDN和旧版主题CSDN按照不同抓取规则抓取
title = response.xpath('//span[@class="link_title"]/a/text()').extract()
if not title:
item['title'] = response.xpath('//h1[@class="csdn_top"]/text()').extract()[0].encode('utf-8')
item['releaseTime'] = response.xpath('//span[@class="time"]/text()').extract()[0].encode('utf-8')
item['readnum'] = response.xpath('//button[@class="btn-noborder"]/span/text()').extract()[0]
else:
item['title'] = title[0].encode('utf-8').strip()
item['releaseTime'] = response.xpath('//span[@class="link_postdate"]/text()').extract()[0]
item['readnum'] = response.xpath('//span[@class="link_view"]/text()').extract()[0].encode('utf-8')[:-9]
# 抓取正文
data = response.xpath('//div[@class="markdown_views"]|//div[@id="article_content"]')
item['article'] = data.xpath('string(.)').extract()[0]
# 用python jieba模块提取正文关键字,topK=2表示提取词频最高的两个
tags = jieba.analyse.extract_tags(item['article'], topK=2)
item['keywords'] = (','.join(tags))
print "博文标题: ", item['title']
print "博文链接: ", item['url']
yield item5. 运行项目:
scrapy crawl spider_csdnblog --nolog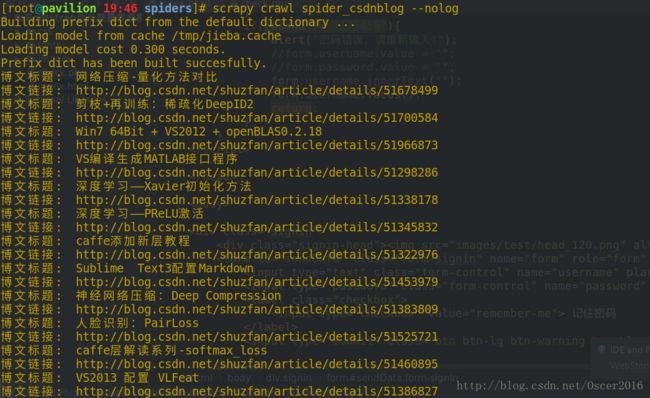
6. 在 MongoDB 客户端中查看数据:
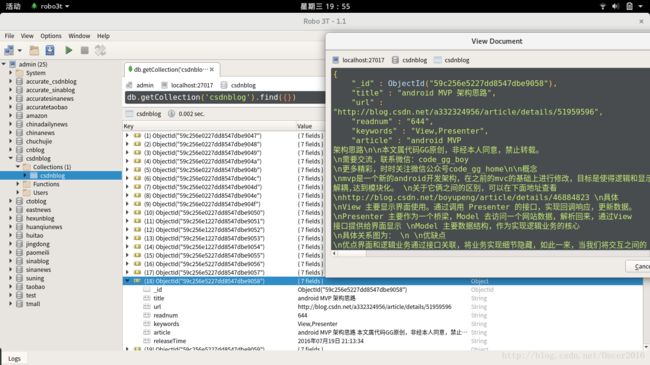
Note: 如果要爬取指定博主的所有博文,只需要简单修改爬虫文件即可(保留 total 函数及其下面函数)。
至此,CSDN 博客专家的所有博文已成功爬取并存入了 MongoDB 数据库中。