如何利用Kubernetes集群提升资源利用率?

导语 | 近日,云+社区技术沙龙“高效智能运维”圆满落幕。本期沙龙围绕运维展开了一场技术盛宴,从AIOps、Serverless DevOps、蓝鲸PaaS平台、K8S等分享关于业务运维的技术实践干货,同时带来腾讯海量业务自研上云实践,推动传统运维向云运维转型。本文是庄鹏锐老师关于腾讯云内部平台STKE是如何提升平台资源利用率的内容分享。
一、为什么集群资源利用率会不够高?
首先我们来分析一下,为什么集群资源利用率会不够高?其中大概会归纳为以下几个方向。
 第一个是Node节点资源的碎片。在我们那么多的集群里面会发现,往往分配比整个集群到90%多的时候,就会创建不了Pod了,其实每个Node都会有一些零碎的资源。
第一个是Node节点资源的碎片。在我们那么多的集群里面会发现,往往分配比整个集群到90%多的时候,就会创建不了Pod了,其实每个Node都会有一些零碎的资源。
第二点,Pod Resource配置不合理。业务在创建Pod的时候,都不清楚自己到底要设多少,所以往往会设很大,从而造成资源的浪费,而且他们的比例设置的requests和limits得也不太合适。
第三点,WorkLoad/HPA 副本数设置不合理。就是我们workload的副本数。很多人在上云的过程中,很多人不知道自己要设置多少的副本才合适,在这里面,也涉及到一个最小副本数设计多大才是合理的。
第四点,业务的空闲时间。我们会发现很多业务都是有它固定的特性,比如说游戏,我们会发现晚上会有一个使用高峰期,而在我们白天上班期间,资源使用率相对会低些。
二、解决方案
下图展示了我们在这些方面做的一些优化要点。

第一个是对Pod的压缩,这里主要是对Pod的resource资源中requests进行压缩。第二个是Node超卖,让Node可以调度进来跟多Pod。第三个是对HPA改造,我们称为HPAPlus组件,第四个是对VPA改造实践,我们称为VPAPlus,第五个是动态调度,动态调度根据实际的集群资源负载情况对Scheduler的优选环节得分进行调整,以得到实际最适合部署Pod的Node节点。这里最后一个是碎片处理,这个会讲为刚才说的存在的会浪费资源的问题。这一块主要是去检测整个集群资源分布的情况,然后进行重调度。下面重点介绍前4点。
1. Pod压缩
首先我们讲一下Pod的资源压缩。
这里有个前提条件,在于limits我们给用户保证的是一个资源值,就是单个Pod最多能够使用多少核CPU和多少G内存。Request会影响调度,调度时会scheduler组件会使用每一个node中的可分配资源和已分配的Pod Requests做来计算。当已分配requests等于或者接近于可分配资源的话,那就不会再调度Pod进来了。它主要解决的是Pod本身的一个资源的调整。
 这里我们主要做的是当创建一个Pod的时候,会设计一个ratio值,当用户有Pod创建请求过来的时候,我们会帮他篡改Pod的数据,然后按照我们设计的比例,用Pod的限制来设计Pod的request值,所以无论这个值设的多少,最后都会被我们改掉。这样子做的原因就是为了将requests和limits拉开一定的空间,从而达到超卖的效果。
这里我们主要做的是当创建一个Pod的时候,会设计一个ratio值,当用户有Pod创建请求过来的时候,我们会帮他篡改Pod的数据,然后按照我们设计的比例,用Pod的限制来设计Pod的request值,所以无论这个值设的多少,最后都会被我们改掉。这样子做的原因就是为了将requests和limits拉开一定的空间,从而达到超卖的效果。
实现原理我们可以看这张图的下角,最下的一条横的流程,这条流程其实就是kube-apiserver收到请求的时候,会经过什么样的处理流程。可以看到,首先是经过认证授权,然后进入到Mutating Admission Controller机制,这个机制去访问后端的一个服务,由这个服务来修改数据,再返回给它。然后再把修改完的数据保存到Etcd里面,所以最终创建Pod的数据是被我们篡改过的。流程中最后两点就是合法性校验了,和上面Mutating Admission Controller机制是差不多的,比如说我这个请求是否超过了nod的最大数或者是超过了所设计的值。
通过这样的方式,我们就把整个集群的资源的request给压缩下来,当request压缩下来之后,我们就可以创建跟多的Pod。这样子做有一个很大的原因是我们是将修改workload权限开放给了对应用户,所以有的用户会乱改workload资源配置。
2.Node超卖
然后是Node超卖,kubelet默认每隔10秒就会重新计算自身Node的可分配的资源并发生一个patch的请求给kube-apiserver,来上报自身的状态。

在这个过程中,我们主要做两个方面的实践,第一是由一个组件,通过Prometheus来获取Node历史使用数据,然后根据node当前的资源分配和使用情况来自动计算超卖比例。比如当Node资源已分配非常多,但是使用率又相对比较低的时候,我们认为这个Node的实际利用率很低,可以进行超卖。第二点就是跟上面Pod超卖类型,根据Mutating Admission Controller机制,在kubelet每隔10秒默认的周期发生Patch请求时,根据上述计算出来的超卖比例,对Node可分配资源进行修改。
3.HPAplus
第三个是HPAplus,实际上它是基于原本的HPA,我们把原生的controller-manager中HPA逻辑全部抽出来,做成一个独立的组件,并进行相应的改造。在K8s里面,需要controller-manager中HPA功能给关掉,因为两者会冲突。为什么将它抽出来呢?其实有两个原因。一个是它在HPA本身的性能不是很高,需要进行改造。第二个,我们并不想去大规模改动k8s的本身的代码,避免以后和社区方向偏差越来越大,不好升级。
 我们的HPAPlus做了哪些方面的工作呢?首先看图中左边这三栏:第一个监控数据还是来自metrics server,跟原生的没有区别。第二个监控的数据来源是通过Pormetheus获取,主要是除CPU、memory外的其它基础监控指标。第三个是由于我们自己公司内部有非常多的业务的监控系统,原本不是云原生的,而是存量就有的,所以这里我们需要去写一个adapt,然后将这些数据报上去,从而实现支持业务指标的HPA,比如说连接数、TPS等等。当然更多的还是一些基础数据,主要是扩展了CPU和memory之外的一些数据。所有的数据都通过一个类似Adater的组件去暴露给kube-apiserver,而HPAPlus-Controller会根据这些数据计算出workload所需要的副本数。
我们的HPAPlus做了哪些方面的工作呢?首先看图中左边这三栏:第一个监控数据还是来自metrics server,跟原生的没有区别。第二个监控的数据来源是通过Pormetheus获取,主要是除CPU、memory外的其它基础监控指标。第三个是由于我们自己公司内部有非常多的业务的监控系统,原本不是云原生的,而是存量就有的,所以这里我们需要去写一个adapt,然后将这些数据报上去,从而实现支持业务指标的HPA,比如说连接数、TPS等等。当然更多的还是一些基础数据,主要是扩展了CPU和memory之外的一些数据。所有的数据都通过一个类似Adater的组件去暴露给kube-apiserver,而HPAPlus-Controller会根据这些数据计算出workload所需要的副本数。
相关特性如下图所示,下面依次讲解。

第一个是一个HPA一个goroutine,当我们的集群规模非常非常大的时候,如果按原生HPA是一个单进程去处理完所有的HPA的话,相对来说,性能是很低的,所以这里是做到了一个HPA的一个goroutine。
第二点是刚才我们讲的,支持各种的跟进数据来做HPA这样的功能。第三点和第四点分别我们做到了HPA级别的同步时间,比如说A HPA是可以设置它每隔10秒同步一次,B HPA可以每隔15秒同步一次。
第三点是抑制时间,在HPA扩缩容后,我不想它在一定时间内太频繁地扩缩容。
第四点是我们之前的两种计算方式,在原有的HPA里面,是只支持request,然后在扩缩容的时候,原生HPA是根据整个workload对Pod的requests作为计算副本数的分母,而我们在这里同时支持了limits,因为我们给用户保障的是limits的值。而且我们在前面对Pod进行了压缩,如果使用requests做的扩容,而又将将request压缩之后,用户可能设了触发阈值为50%,这时到达原来的25%就扩容了,所以这一块我们是用limit来做的。
第五点就是CronHPA,可以再设定的时间段对workload进行扩缩容,这个主要是为了避免业务访问量大量增长时扩容速度更不上。最后一点是动态调整的最小副本数,这个在我们的整个提到集群利用率是很明显的效果,比如说我们之前是有发现有一些用户它的最小副本数就是设置了1000个,但是他的资源利用率就只有0.1%,这是一个很浪费资源的情况。我们在后台有一个服务,会根据历史的监控数据拿到我之前使用时间的合理值,然后根据资源的合理值去设置它的最小副本数。这时候如果我们发现那1000个最小副本数我们其实可以更新到2个。我们之前有一个集群已经分配满出去了,然后通过这个动态调整直接从90%可以降到60%。
4.VPAPlus
最后一个是VPAPlus。
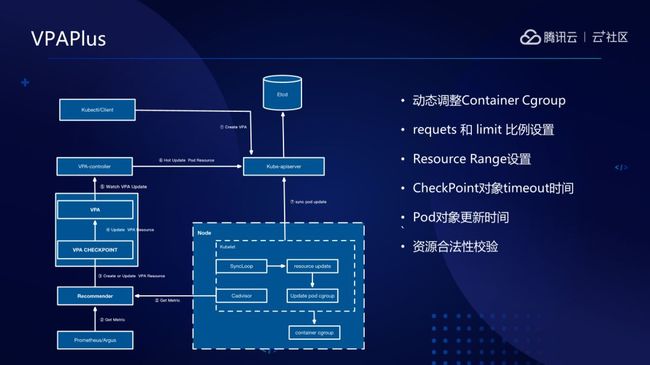
这里面我们和社区版本最大的不同的点是社区版本是通过驱除掉Pod的方式去完成垂直伸缩,这个时间是很长的。
这里面可以涉及到的一些点是什么?我们的业务为了保证他的无损升级,基本上我们每个Pod都会设置一个优雅结束时间,接下来就是等待调度,拉取镜像等,再者就是Pod拉起后等到进程能正常提供服务,服务ready时间也是可能会形成一个很长的时间,所以如果通过驱逐Pod这样的方式去做的话,那么整个伸缩的时间我们认为是很难以接受的,因为VPA的特性应该是快速地响应。
所以,第一点我们是改了K8S的代码,改K8S的代码分为两个方面,第一方面是修改kube-apiserver的代码,因为它有一个合法性校验的逻辑,默认是拒绝直接修改Pod resource。第二点,是修改kubelet组件,在原有的逻辑里面是没有针对Pod update资源做更新,主要是更新code的一个操作,在kubelet 的sync loop中,我们添加了update resource的逻辑,并且对接了runtime相应的update 接口。首先是update了Pod cgroup配置,然后Update了Container Cgroup配置。这里面有一个比较值得注意的点就是,如果使用了dockerd,会发现默认的情况下面,在创建的时候,K8S会把memory limit和memory swap limit是设置为一比一的,而update接口是不管swap limit的。当我们的memory limit往上升的时候,如果的swap limit值不变,这时候更新cgroup memory limit是不成功的,这个是linux内核限制的。所以这里面也是稍微改了一下,我们直接将memory swap limit改成了不限制,因为k8s建议就是关闭了swap分区。
这里面分为几个组件,刚才讲的是K8S如何去做热更新或者是配置,然后我们看VPA,VPA如何去将整个流程创起来呢?我们可以从最下面开始看,首先是有recommender组件,可以通过我们的监控组件拿历史数据,实时数据是通过kube-apiserver的metics接口来拿的,然后去把拿到相应资源存到一个资源对象CheckPoint,checkpoint是一个直方图,它是按区间划分的。比如说memory 0-5M他就划为一个区间,然后5-10M又划为一个区间,依次类推,然后把拿到的值按区间存放计数,并根据时间间隔更新权重。然后根据它的数据来确定VPA的对象推荐值。包括有三个值,这个其实是一个分布比,最大的是95%,中间的是90%,最小的是50%,我们根据它计算出来的值,将计算出来的建议值存到了VPA里面。接着就是update-controller组件做的工作,根据VPA对象中的推荐值来update pod。社区版本里面也有一个类似这样的东西,但是一个是功能不满足,另外一个是性能不够好。所以我们按照controller的方式重新写了一个controller,这两面主要是两个逻辑,一个是实时监控VPA和Pod的更新,另外一个是update pod。首先我们会去实时watchVPA的情况,当watch到更新了VPA的时候,我们会根据VPA里面的值经过我们的逻辑计算,得出最终推荐值,然后再去update pod。
这里面我们还做了一些特性,一是上面讲过的动态调整Cgroup。二是requests 和limit比例设置,可以为每个VPA设定比例,然后limits是可以设置相应的比例乘以requests去设置的。第三是resource限制,因为调节的时候不可能无限调小也不可能无限调大,调得太大会导致超过整个node的资源的限制,或者是说占用了太多的资源导致难以接受。在计算的时候也会过滤一遍看看你更新的时候会不会超过Node。还有一个,对于VPA和checkpoint更新的时间,比如说我有一些业务想根据他非常短的时间内的监控值去计算。那有一些用户可能就想根据几天的数据值去计算。gc逻辑可以获取到对应VPA个性化配置,超过这个时间的,我就可以把所有的数据全部丢掉,重新生成新的数据。
另外一个是Pod对象的更新时间,我们会设置某一个Pod在多久内可以允许去更新一次,并且默认更新的比例超过0.1。最后一点是适配我们自身的资源分配、资源管理的方案去做,比如某个业务有多少核资源可以申请,但是你要是超过这个业务的配额,我也会直接把它拒绝掉,另外一个也是不能超过Node本身的可分配资源。
讲师介绍
 庄鹏锐,腾讯云高级工程师。先后在唯品会,vivo,腾讯等公司从事Kubernetes云平台建设的工作。目前主要负责内部业务上Kubernets平台的相关方案设计和开发。
庄鹏锐,腾讯云高级工程师。先后在唯品会,vivo,腾讯等公司从事Kubernetes云平台建设的工作。目前主要负责内部业务上Kubernets平台的相关方案设计和开发。
Q:您好,我想问一下K8S中间好多模块做了调整,后期升级的话是自动跳过还是怎么样呢?
A:对于我们来说,我们能够把它拿出来当做插件的话就会拿出来,因为这样就不会影响到以后核心组件的升级。另外一个是比如说我更新了kubelet代码,这一块是直接更新在kubelet代码里面的。这种情况我们腾讯云内部是有一个统一维护的版本,会合到这个版本里面,后期版本都会带有这方面的特性。
---------下方更多精彩----------
文章推荐

点击图片即可了解详情
最近 Serverless 又火了,有不少业务上云实装了 Serverless 云函数,取得了不错的落地效果,业界也在不断探索 Serverless 更多的落地场景。
那么对于前端来说,Serverless 意味着什么?对于 Node 服务来说,哪里可以落地 Serverless?
答:Serverless 同构直出渲染
——《NGW,前端新技术赛场:Serverless SSR 技术内幕》

关注云加社区,回复 加群 加读者群
点在看,和朋友一起关注未来