常见分布及其概率分布图
概率分布有两种类型:离散(discrete)概率分布和连续(continuous)概率分布。
离散概率分布也称为概率质量函数(probability mass function)。离散概率分布包括:
- 伯努利分布(Bernoulli distribution)
- 二项分布(binomial distribution)
- 几何分布(geometric distribution)
- 泊松分布(Poisson distribution)等。
连续概率分布也称为概率密度函数(probability density function),它们是具有连续取值(例如一条实线上的值)的函数。连续概率分布包括:
- 正态分布(normal distribution)
- 指数分布(exponential distribution)
- β分布(beta distribution)等。
1. 两点分布(伯努利分布)
伯努利试验:
伯努利试验是在同样的条件下重复地、各次之间相互独立地进行的一种试验。
即只先进行一次伯努利试验,该事件发生的概率为p,不发生的概率为1-p。这是一个最简单的分布,任何一个只有两种结果的随机现象都服从0-1分布。
最常见的例子为抛硬币
其中,期望 E = p E = p E=p ,方差 D = p ( 1 − p ) 2 + ( 1 − p ) ( 0 − p ) 2 = p ( 1 − p ) D = p(1-p)^2+(1-p)(0-p)^2 = p(1-p) D=p(1−p)2+(1−p)(0−p)2=p(1−p)
2. 二项分布(n重伯努利分布)
用数学符号 X~B(n,p) 来表示二项分布。即做n个两点分布的实验,其中, E = n p E = np E=np, D = n p ( 1 − p ) D = np(1-p) D=np(1−p)。而它的概率分布函数为: P ( k ) = C n k p k ( 1 − p ) n − k P(k)=C_n^kp^k(1-p)^{n-k} P(k)=Cnkpk(1−p)n−k。
对于抛硬币的问题,做100次实验,正反面概率都为0.5,观察其概率分布函数:
from scipy.stats import binom
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
# Binomial distribution
n = 100
p = 0.5
k = np.arange(20,80)
binomial = binom.pmf(k,n,p)
plt.plot(k, binomial, 'o-')
plt.title('binomial:n=%i,p=%.2f'%(n,p))
plt.xlabel('number of success') #正面向上的次数
plt.ylabel('probalility of success')
plt.grid(True)
plt.show()
结果显示如下:
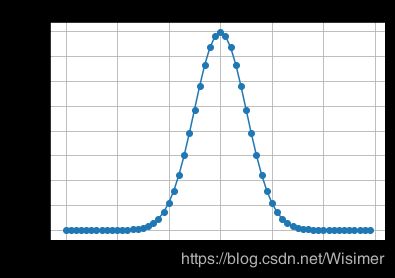
观察概率分布图,可以看到,对于n = 100次实验中,有50次成功的概率(正面向上)的概率最大。
3. 几何分布
用数学符号 X~GE(p) 来表示几何分布。即在n次伯努利实验中,第k次实验才得到第一次成功的概率分布。其中: P ( k ) = ( 1 − p ) ( k − 1 ) p P(k) = (1-p)^{(k-1)}p P(k)=(1−p)(k−1)p。期望值 E = 1 / p E = 1/p E=1/p 推导方法就是利用利用错位相减法然后求lim - k ->无穷 。方差 D = ( 1 − p ) / p 2 D = (1-p)/p^2 D=(1−p)/p2 推导方法利用了 D ( x ) = E ( x ) 2 − E ( x 2 ) D(x) = E(x)^2-E(x^2) D(x)=E(x)2−E(x2),其中 E ( x 2 ) E(x^2) E(x2)求解同上。
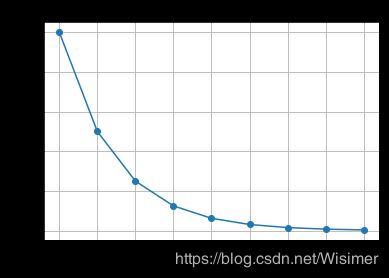
对于抛硬币的问题,正反面概率都为0.5,观察第k次实验才得到第一次成功的概率分布函数:
from scipy.stats import geom
# 几何分布(geometric distribution)
n = 10
p = 0.5
k = np.arange(1,10)
geom_dis = geom.pmf(k,p)
plt.plot(k, geom_dis, 'o-')
plt.title('geometric distribution')
plt.xlabel('i-st item success')
plt.ylabel('probalility of i-st item success')
plt.grid(True)
plt.show()
显示结果如下:
4. 泊松分布
用数学符号X~P(λ) 表示泊松分布。描述单位时间/面积内,随机事件发生的次数。 P ( x = k ) = λ k k ! e ( − λ ) , k = 0 , 1 , 2 , . . . λ > 0 P(x = k) = \frac{λ^k}{k!}e^{(-λ) } ,k = 0,1,2, ... λ >0 P(x=k)=k!λke(−λ),k=0,1,2,...λ>0。泊松分布可作为二项分布的极限而得到。
一般的说,若X~B(n,p),其中n很大,p很小,因而 np=λ 不太大时,X的分布接近于泊松分布 P(λ)。λ:单位时间/面积下,随机事件的平均发生率。期望值E = λ,方差D = λ。譬如:某一服务设施一定时间内到达的人数、一个月内机器损坏的次数等。
假设某地区,一年中发生枪击案的平均次数为2。考察一下不同次数的概率分布:
from scipy.stats import poisson
# 泊松分布(poisson distribution)
mu = 2
x = np.arange(10)
plt.plot(x, poisson.pmf(x, mu),'o')
plt.title(u'poisson distribution')
plt.xlabel('shot case count')
plt.ylabel('probalility of shot case count')
plt.grid(True)
plt.show()
结果显示如下:
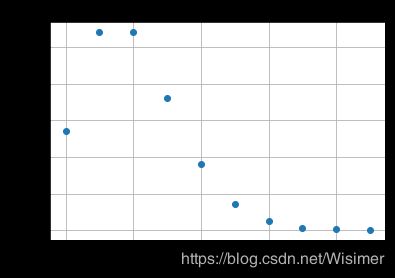
一年内的枪击案发生次数的分布如上所示。可以看到1次和2次的枪击案发生概率最高。
与二项分布对比:
# 二项分布和泊松分布对比
fig,ax = plt.subplots(1,1)
n = 1000
p = 0.1
x = np.arange(80,120)
p1, = ax.plot(x, binom.pmf(x, n, p),'b*',label = 'binom')
mu = n*p
p2, = ax.plot(x, poisson.pmf(x, mu),'ro',label = 'poisson')
plt.legend(handles = [p1, p2])
plt.title(u'possion and binomial')
plt.show()

可以看到这里当n=1000,p=0.1时, λ=100,泊松分布和二项分布已经很接近了。
5. 指数分布
用数学符号 X~E(λ) 表示指数分布。
指数分布的特性:无记忆性。比如灯泡的使用寿命服从指数分布,无论他已经使用多长一段时间,假设为s,只要还没有损坏,它能再使用一段时间t 的概率与一件新产品使用时间t 的概率一样。
这个证明过程简单表示: P ( s + t ∣ s ) = P ( s + t , s ) / P ( s ) = F ( s + t ) / F ( s ) = P ( t ) P(s+t| s) = P(s+t , s)/P(s) = F(s+t)/F(s)=P(t) P(s+t∣s)=P(s+t,s)/P(s)=F(s+t)/F(s)=P(t)
它的概率密度函数为:
f ( x ) = { λ e − λ x x > 0 , λ > 0 0 x ≤ 0 f(x)=\begin{cases} \lambda e^{-\lambda x} & x>0,\lambda > 0\\ 0 & x\le0 \end{cases} f(x)={λe−λx0x>0,λ>0x≤0
期望值 E = 1 / λ E=1/λ E=1/λ,方差 D = 1 / λ 2 D=1/λ^2 D=1/λ2。
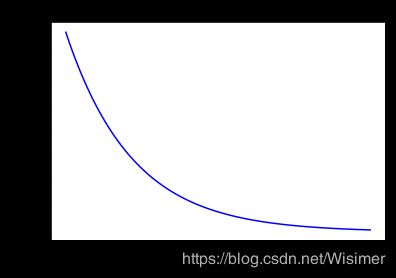
from scipy.stats import expon
# 指数分布
fig,ax = plt.subplots(1,1)
lambdaUse = 2
loc = 0
scale = 1.0/lambdaUse
#ppf:累积分布函数的反函数。q=0.01时,ppf就是p(X
x = np.linspace(expon.ppf(0.01,loc,scale),expon.ppf(0.99,loc,scale),100)
ax.plot(x, expon.pdf(x,loc,scale),'b-',label = 'expon')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title(u'expon distribution')
plt.show()
显示结果如下:
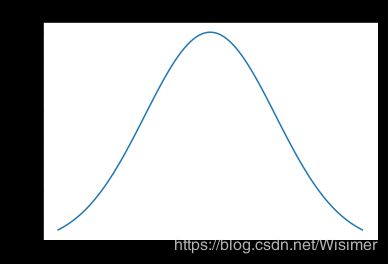
6. 正态分布(高斯分布)
用数学符号 X~N(μ,σ^2) 表示正态分布。期望值 E = μ E = μ E=μ,方差 D = σ 2 D = σ^2 D=σ2。
正态分布是比较常见的,譬如学生考试成绩的人数分布、身高分布等。
它的概率密度函数是:
f ( x ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) f(x)=\frac{1}{\sqrt{2\pi} \sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2}) f(x)=2πσ1exp(−2σ2(x−μ)2)
from scipy.stats import norm
# 正态分布(normal distribution)
fig,ax = plt.subplots(1,1)
loc = 1
scale = 2.0
#ppf:累积分布函数的反函数。q=0.01时,ppf就是p(X
x = np.linspace(norm.ppf(0.01,loc,scale),norm.ppf(0.99,loc,scale),100)
ax.plot(x, norm.pdf(x,loc,scale),'-',label = 'norm')
plt.title(u'normal distribution')
plt.show()
附:
code
参考:
- 概率论中常见分布总结以及python的scipy库使用:两点分布、二项分布、几何分布、泊松分布、均匀分布、指数分布、正态分布
THE END.