手写数字识别模型识别自己的图片
本文旨在说明如何将训练好的模型运用到自己的图片中。
1、全连接层神经网络模型搭建、训练等代码如下:
// An highlighted block
var foo = 'bar';
#MNIST数据集是一个手写字体数据集,包含0-9这10个数字,
#其中有55000张训练集,10000张测试集,5000张验证集,图片大小是28x28灰度图
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import net
import numpy as np
import deal_handwritten_numeral as dhn
#定义一些超参数,
batch_size = 64
learning_rate = 1e-2
num_epoches = 20
#先定义数据预处理
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
# x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
#下载训练集
train_dataset = datasets.MNIST(root='data',train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size= batch_size, shuffle=False)
#导入网络,定义损失函数和优化方法,模型已在net.py里面定义过了
model = net.simple_Batch_active_Net(28*28, 300, 100, 10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
#注意这里是导入之前训练的模型参数,如果第一次训练请注释掉
model.load_state_dict(torch.load('model_mnist.pth'))
# 开始训练
for n in range(10):
train_loss = 0
train_acc = 0
eval_loss = 0
eval_acc = 0
model.train()
for im, label in train_loader:#每次取出64个数据,在之前就定义好了
im = Variable(im)
label = Variable(label)
# 前向传播
out = model(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()#对张量对象可以用item得到元素值
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()#对张量对象可以用item得到元素值
acc = num_correct / im.shape[0]#预测正确数/总数,对于这个程序由于小批量设置的是64,所以总数为64
train_acc += acc#计算总的正确率,以便求平均值
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}'
.format(n, train_loss / len(train_loader), train_acc / len(train_loader)))
torch.save(model.state_dict(), 'model_mnist.pth')
#进入测试阶段
model.eval()
for im, label in test_loader:
# print(im.shape, im.size)
im = Variable(im)
label = Variable(label)
out = model(im)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.item()
# 记录准确率
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
print('epoch: {}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(n, eval_loss / len(test_loader), eval_acc / len(test_loader)))
2、处理自己的图片
以上是模型的搭建训练不在赘述,下面主要是如何利用自己的图片识别,首先我们要将自己的图片做成数据集的格式。也就是每个数字是28x28的像素点,并转成灰度,这些可以用cv库来实现也可以用其他的来实现,最主要是要使图片与数据集里的图片一样。此过程参考博客链接: link.
首先贴一张我的原图: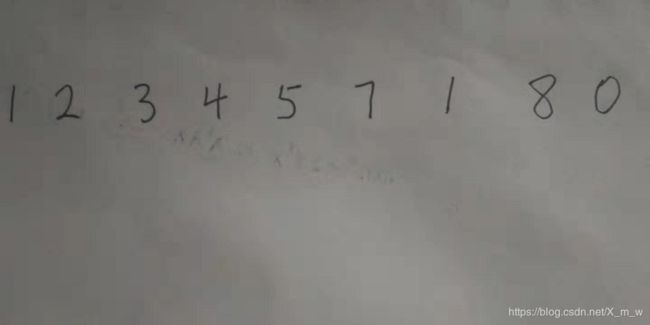
2.1、按灰度图像处理
import cv2
import numpy as np
import matplotlib.pyplot as plt
"""由于imread函数自带可以灰度图像读入,所以不需要再转灰度
img_path = "test1.png"
#将图像转换为灰度图像
def change_gray(img):
# img = cv2.imread(img_path)
# 获取图片的宽和高
width, height = img.shape[:2][::-1]
# 将图片缩小便于显示观看
img_resize = cv2.resize(img, (int(width * 0.5), int(height * 0.5)), interpolation=cv2.INTER_CUBIC)
# cv2.imshow("img", img_resize)
# print("img_reisze shape:{}".format(np.shape(img_resize)))
# 将图片转为灰度图
img_gray = cv2.cvtColor(img_resize, cv2.COLOR_RGB2GRAY)
# cv2.imshow("img_gray", img_gray)
# print("img_gray shape:{}".format(np.shape(img_gray)))
# cv2.waitKey()
return img_gray
"""
"""###############################图像预处理###############################################"""
# 反相灰度图,将黑白阈值颠倒,挨个像素处理
def accessPiexl(img):
# change_gray(img)
height = img.shape[0]
width = img.shape[1]
for i in range(height):
for j in range(width):
img[i][j] = 255 - img[i][j]
return img
# 反相二值化图像
# test1使用170,test2使用165
def accessBinary(img, threshold=170):
img = accessPiexl(img)#反色
kernel = np.ones((3, 3), np.uint8)
#滤波
# img = cv2.medianBlur(img, 3)#均值滤波 即当对一个值进行滤波时,使用当前值与周围8个值之和,取平均做为当前值
img = cv2.GaussianBlur(img, (3, 3), 0)#高斯滤波 根据高斯的距离对周围的点进行加权,求平均值1,0.8, 0.6, 0.8
# img = cv2.medianBlur(img, 3)#中值滤波 将9个数据从小到大排列,取中间值作为当前值
# 进行腐蚀操作,去除边缘毛躁
# img = cv2.erode(img, kernel, iterations=1)
#利用阈值函数,二值化
# _, img = cv2.threshold(img, threshold, 0, cv2.THRESH_TOZERO)#简单二值化,阈值固定
img = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 7, -9)#自适应滤波 这个效果还行
# 边缘膨胀,不加也可以
img = cv2.dilate(img, kernel, iterations=1)#被执行的次数
return img
# path = 'test7.png'
# img = cv2.imread(path, 0)
# # #以灰度模式读入图片,可以用0表示;读入一副彩色图片,可以用1表示;读入一幅图片,并包括其alpha通道,可以用2表示
# # img = accessPiexl(img)
# img = accessBinary(img)
# cv2.imshow('accessBinary', img)
# cv2.waitKey(0)
2.2、识别数字位置
"""#########################################字符分割#####################################################"""
#接下来我们就要进行行列扫描了,首先了解一个概念,黑色背景的像素是0,白色(其实是灰度图是1-255的)是非0,
# 那么从行开始,我们计算将每一行的像素值加起来,如果都是黑色的那么和为0(当然可能有噪点,我们可以设置个阈值将噪点过滤),
# 有字体的行就非0,依次类推,我们再根据这个图来筛选边界就可以得出行边界值
# 有了上面的概念,我们就可以通过行列扫描,根据0 , 非0,非0 … 非0,0这样的规律来确定行列所在的点来找出数字的边框了
# 根据长向量找出顶点
def extractPeek(array_vals, min_vals=10, min_rect=20):#以下注释适用于行,也适用于列
extrackPoints = []
startPoint = None
endPoint = None
for i, point in enumerate(array_vals):#i是下标,point是遍历array_vals数据
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
if point > min_vals and startPoint == None:#如果该行的白点大于下限,且之前的行没有过,那么这是起始行
startPoint = i
elif point < min_vals and startPoint != None:#如果该行的白点小于下限,且之前的行有过,那么这是结束行
endPoint = i
if startPoint != None and endPoint != None:#如果检测到是上下界都有,存储起来
extrackPoints.append((startPoint, endPoint))
startPoint = None
endPoint = None
# 剔除一些噪点
for point in extrackPoints:
if point[1] - point[0] < min_rect:#如果上下界小于距离限制,剔除
extrackPoints.remove(point)
return extrackPoints#返回所有的起始行结束行,两个为一组(起始、结束)
# 寻找边缘,返回边框的左上角和右下角(利用直方图寻找边缘算法(需行对齐))
def findBorderHistogram(path):
borders = []
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)#以灰度图像读入
img = accessBinary(img) #反相二值化图像
# 行扫描
hori_vals = np.sum(img, axis=1)
# 进行加法运算的向量 / 数组 / 矩阵
# 当axis为0时, 是压缩行, 即将每一列的元素相加, 将矩阵压缩为一行
# 当axis为1时, 是压缩列, 即将每一行的元素相加, 将矩阵压缩为一列
hori_points = extractPeek(hori_vals)
# 根据每一行来扫描列
for hori_point in hori_points:#取已经确定的行
extractImg = img[hori_point[0]:hori_point[1], :]#上面已经说检测的起始、结束是成对出现的,那么再选取两者之前的行做列分析
vec_vals = np.sum(extractImg, axis=0)# 进行加法运算的向量 / 数组 / 矩阵, 压缩列成一行
vec_points = extractPeek(vec_vals, min_rect=10)#这里取距离限制为10
#hori_points是所有行界的集合,vect_point是所有列界的集合
for vect_point in vec_points:#添加边界
border = [(vect_point[0], hori_point[0]), (vect_point[1], hori_point[1])]
#vect_point[0]代表一个数字的左边界,vect_point[1]代表一个数字的右边界
# hori_point[0]代表一个数字的上边界,hori_point[1]代表一个数字的下边界
borders.append(border)
return borders
# 显示结果及边框
def showResults(path, borders, results=None):
img = cv2.imread(path)
# 绘制
print(img.shape)
for i, border in enumerate(borders):
cv2.rectangle(img, border[0], border[1], (0, 0, 255))
# cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 画出矩形,各参数依次是:img是原图,第二个参数是矩阵的左上点坐标,
# 第三个参数是矩阵的右下点坐标,第四个参数是画线对应的rgb颜色,第五个参数是所画的线的宽度。
# print(type(results[0]))
if results != None:
cv2.putText(img, str(results[i]), border[0], cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 0), 1)
# img – 想要打印上文字的图像 text – 想要打印的文字 org – 文字的左下角坐标
# fontFace – 字体,可选的有:FONT_HERSHEY_SIMPLEX,
# cv2.circle(img, border[0], 1, (0, 255, 0), 0)
cv2.imshow('test', img)
cv2.waitKey(0)
#####################################################################
# for i in range(1, 5):
# path = r'test' + str(i) + '.png' #获取图像地址
# borders = findBorderHistogram(path)
# showResults(path, borders)
# findContours模式
# 对于手写不齐的情况上述方法不太实用
# 针对于行列式这种扫描方式的局限性我们来介绍第二种方法,基于opencv的一个寻找轮廓的方法
# talk is cheap,show you code
# 就是利用OpenCV里面的findContours函数将边缘找出来,
# 然后通过boundingRect将边缘拟合成一个矩形输出边框的左上角和右下角,然后执行这个代码就可以得到以下的效果了
# 寻找边缘,返回边框的左上角和右下角(利用cv2.findContours)
def findBorderContours(path, maxArea=100):
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
img = accessBinary(img)
#这里关于返回值是几个网上不太确定,但是本工程是2个
contours, _ = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
borders = []
for contour in contours:
# 将边缘拟合成一个边框
x, y, w, h = cv2.boundingRect(contour)
if w * h > maxArea:
if h > 20:
border = [(x, y), (x + w, y + h)]
borders.append(border)
return borders
测试识别位置结果
for i in range(1, 5):
path = r'test' + str(i) + '.png' #获取图像地址
borders = findBorderContours(path)
# print(borders)
showResults(path, borders)

2.3、切割分离处理
# 通过上面两种方法,我们已经可以找出图中一个个的数字了,那么我们怎么转换为MNIST那种形式呢?
# 如下所示,我们首先将边框转为28*28的正方形,因为背景是黑色的,我们可以通过边界填充的形式,
# 将边界扩充成黑色即可,其中值得注意的是MNIST那种数据集的格式是字符相对于居中的,我们得出的又是比较准的边框
# 所以为了和数据集相对一致,我们要上下填充一点像素
# 根据边框转换为MNIST格式
def transMNIST(path, borders, size=(28, 28)):
imgData = np.zeros((len(borders), size[0], size[0], 1), dtype='uint8')
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
img = accessBinary(img)
for i, border in enumerate(borders):
borderImg = img[border[0][1]:border[1][1], border[0][0]:border[1][0]]
h = abs(border[0][1] - border[1][1])#高度
# w = abs(border[0][0] - border[1][0])#宽度
# # 根据最大边缘拓展像素
extendPiexl = (max(borderImg.shape) - min(borderImg.shape)) // 2
h_extend = h // 5
# print(h_extend)
targetImg = cv2.copyMakeBorder(borderImg, h_extend, h_extend, int(extendPiexl*1.1), int(extendPiexl*1.1), cv2.BORDER_CONSTANT)
# targetImg = cv2.copyMakeBorder(borderImg, 20, 20, h_extend, h_extend,cv2.BORDER_CONSTANT)
# targetImg = cv2.resize(borderImg, size)#先把图像变成28x28,
#拓展边界,但是1比较特殊,所以对1特殊处理先判断出1
# if w < (h//3):#如果宽度小于高的1/5,那估计是1
# targetImg = cv2.copyMakeBorder(targetImg, 4, 4, 20, 20, cv2.BORDER_CONSTANT)#左右多扩展一些
# print("1")
# else:
# targetImg = cv2.copyMakeBorder(targetImg, 4, 4, 6, 6, cv2.BORDER_CONSTANT)
targetImg = cv2.resize(targetImg, size)
# cv2.imshow('test', targetImg)
# cv2.waitKey(0)
targetImg = np.expand_dims(targetImg, axis=-1)
imgData[i] = targetImg
return imgData
可以在函数中试着输出切割好的小数字图片。
至此,自己的图像已经处理好了,等待被传入训练好的模型中。
3、传入模型,输出结果
在不同的框架中,对传入的特征形式要求不同,像在本例的pytorch框架。
这里有一些数据的变形要注意,可以先观察原始数据从开始到结束的形状,然后根据他们的更改,但要注意,data_tf函数处理的是一张图片一个数字,而我们图片有很多数字所以先去掉了拉直。形状对了之后还要注意转换成Variable变量,这是全连接层神经网络,若是卷积层会更麻烦,但是原理是一样的,观察训练时的图片形状,再将自己图片转换成即可,这里不再赘述,贴上全连接层的输出图片与结果
# 预测手写数字
def predict(imgData):
result_number = []
model.eval()
img = data_tf(imgData)
img = img.reshape(-1,784)
print(img.shape)
test_xmw = DataLoader(img)
for a in test_xmw:
img = Variable(a)
out = model(img)
_,n = out.max(1)
result_number.append(n.numpy())
# result_number = result_number.numpy()
print(result_number)
return result_number
path = 'test1.png' #获取图像地址
print(path)
borders = dhn.findBorderContours(path) #获取数字边界并截取成单个数字图像
imgData = dhn.transMNIST(path, borders) #转变成mnist格式图像
results = predict(imgData) #进行预测
dhn.showResults(path, borders, results) #图像展示

另外:这里显示图像地方法是参考动手学深度学习里面的方法,方法有很多,这里识别的正确率没有很高,跟自己图像的预处理,模型训练都有关系。