Hadoop—MapReduce练习(数据去重、数据排序、平均成绩、倒排索引)
1. wordcount程序
先以简单的wordcount为例。
Mapper:
package cn.nuc.hadoop.mapreduce.wordcount;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型
//map 和 reduce 的数据输入输出都是以 key-value对的形式封装的
//默认情况下,Map框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量(选用LongWritable),value是这一行的内容(VALUEIN选用Text)
//在wordcount中,经过mapper处理数据后,得到的是<单词,1>这样的结果,所以KEYOUT选用Text,VAULEOUT选用IntWritable
public class WCMapper extends Mapper {
// MapReduce框架每读一行数据就调用一次map方法
@Override
protected void map(LongWritable k1, Text v1,
Mapper.Context context)
throws IOException, InterruptedException {
// 将这一行的内容转换成string类型
String line = v1.toString();
// 对这一行的文本按特定分隔符切分
// String[] words = line.split(" ");
String[] words = StringUtils.split(line, " ");
// 遍历这个单词数组,输出为key-value形式 key:单词 value : 1
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
Reducer:
package cn.nuc.hadoop.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//经过mapper处理后的数据会被reducer拉取过来,所以reducer的KEYIN、VALUEIN和mapper的KEYOUT、VALUEOUT一致
//经过reducer处理后的数据格式为<单词,频数>,所以KEYOUT为Text,VALUEOUT为IntWritable
public class WCReducer extends Reducer {
// 当mapper框架将相同的key的数据处理完成后,reducer框架会将mapper框架输出的数据变成。
// 例如,在wordcount中会将mapper框架输出的所有变为,即这里的,然后将作为reduce函数的输入
@Override
protected void reduce(Text k2, Iterable v2s,
Reducer.Context context)
throws IOException, InterruptedException {
int count = 0;
// 遍历v2的list,进行累加求和
for (IntWritable v2 : v2s) {
count = v2.get();
}
// 输出这一个单词的统计结果
context.write(k2, new IntWritable(count));
}
}
驱动类:
package cn.nuc.hadoop.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 用来描述一个特定的作业 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce 还可以指定该作业要处理的数据所在的路径
* 还可以指定改作业输出的结果放到哪个路径
*
* @author Oner.wv
*
*/
public class WCRunner {
public static void main(String[] args) throws ClassNotFoundException,
InterruptedException, IOException {
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf);
// 设置job所在的类在哪个jar包
wcJob.setJarByClass(WCRunner.class);
// 指定job所用的mappe类和reducer类
wcJob.setMapperClass(WCMapper.class);
wcJob.setReducerClass(WCReducer.class);
// 指定mapper输出类型和reducer输出类型
// 由于在wordcount中mapper和reducer的输出类型一致,
// 所以使用setOutputKeyClass和setOutputValueClass方法可以同时设定mapper和reducer的输出类型
// 如果mapper和reducer的输出类型不一致时,可以使用setMapOutputKeyClass和setMapOutputValueClass单独设置mapper的输出类型
// wcJob.setMapOutputKeyClass(Text.class);
// wcJob.setMapOutputValueClass(IntWritable.class);
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(IntWritable.class);
// 指定job处理的数据路径
FileInputFormat.setInputPaths(wcJob, new Path(
"hdfs://master:9000/user/exe_mapreduce/wordcount/input"));
// 指定job处理数据输出结果的路径
FileOutputFormat.setOutputPath(wcJob, new Path(
"hdfs://master:9000/user/exe_mapreduce/wordcount/output"));
// 将job提交给集群运行
wcJob.waitForCompletion(true);
}
}
2. 统计手机流量信息
从下面的数据中的得到每个手机号的上行流量、下行流量、总流量。
源数据:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
数据格式为:
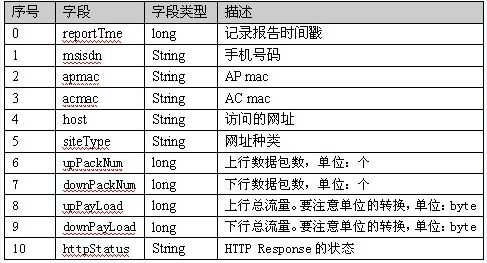
想要的到的数据格式为:
手机号 上行流量 下行流量 总流量
13726230503 2481 24681 27162
13826544101 264 0 264
13926435656 132 1512 1644
... ... ...
2.1 引入和Hadoop序列化机制相关的mapreduce
由于源数据中每一个手机号可能存在多条上网记录,最后要得到的输出格式是一个手机号的所有上行流量、下行流量和总流量。所以可以考虑利用MapReduce框架的特性,将每个手机号作为map的输出key,该手机号上网信息作为map的输出value,经过shuffle,则在reduce端接收到一个
由于数据需要在不同的节点间进行网络传输,所以Bean类必须实现序列化和反序列化,Hadoop提供了一套序列化机制(实现Writable接口)
FlowBean:
package cn.nuc.hadoop.mapreduce.flowsum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable {
private String phoneNB;
private long up_flow;
private long down_flow;
private long sum_flow;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long down_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.down_flow = down_flow;
this.sum_flow = up_flow + down_flow;
}
// 将对象的数据序列化到流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(down_flow);
out.writeLong(sum_flow);
}
// 从流中反序列化出对象的数据
// 从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException {
this.phoneNB = in.readUTF();
this.up_flow = in.readLong();
this.down_flow = in.readLong();
this.sum_flow = in.readLong();
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getDown_flow() {
return down_flow;
}
public void setDown_flow(long down_flow) {
this.down_flow = down_flow;
}
public long getSum_flow() {
return sum_flow;
}
public void setSum_flow(long sum_flow) {
this.sum_flow = sum_flow;
}
@Override
public String toString() {
return "" + up_flow + "\t" + down_flow + "\t" + sum_flow;
}
}
FlowSumMapper:
package cn.nuc.hadoop.mapreduce.flowsum;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowSumMapper extends Mapper {
@Override
protected void map(LongWritable k1, Text v1,
Mapper.Context context)
throws IOException, InterruptedException {
// 一行数据
String line = v1.toString();
// 切分数据
String[] fields = StringUtils.split(line, "\t");
// 得到想要的手机号、上行流量、下行流量
String phoneNB = fields[1];
long up_flow = Long.parseLong(fields[7]);
long down_flow = Long.parseLong(fields[8]);
// 封装数据为kv并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB, up_flow,
down_flow));
}
}
FlowSumReducer:
package cn.nuc.hadoop.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowSumReducer extends Reducer {
// 框架每传递一组数据<1387788654,{flowbean,flowbean,flowbean,flowbean.....}>调用一次我们的reduce方法
// reduce中的业务逻辑就是遍历values,然后进行累加求和再输出
@Override
protected void reduce(Text k2, Iterable v2s,
Reducer.Context context)
throws IOException, InterruptedException {
long up_flow = 0;
long down_flow = 0;
for (FlowBean v2 : v2s) {
up_flow += v2.getUp_flow();
down_flow += v2.getDown_flow();
}
context.write(k2, new FlowBean(k2.toString(), up_flow, down_flow));
}
}
FlowSumRunner:
Job描述和提交的规范写法如下:
package cn.nuc.hadoop.mapreduce.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
//这是job描述和提交类的规范写法
public class FlowSumRunner extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner
.run(new Configuration(), new FlowSumRunner(), args);
System.exit(res);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumRunner.class);
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 执行成功,返回0,否则返回1
return job.waitForCompletion(true) ? 0 : 1;
}
}
打成jar包后运行:
[hadoop@master ~]$ hadoop jar flowcount.jar cn.nuc.hadoop.mapreduce.flowsum.FlowSumRunner /user/exe_mapreduce/flowcount/input /user/exe_mapreduce/flowcount/output
查看结果:
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/output/part-r-00000
13480253104 180 200 380
13502468823 102 7335 7437
13560436666 954 200 1154
13560439658 5892 400 6292
13602846565 12 1938 1950
13660577991 9 6960 6969
13719199419 0 200 200
13726230503 2481 24681 27162
13726238888 2481 24681 27162
13760778710 120 200 320
13826544101 0 200 200
13922314466 3008 3720 6728
13925057413 63 11058 11121
13926251106 0 200 200
13926435656 1512 200 1712
15013685858 27 3659 3686
15920133257 20 3156 3176
15989002119 3 1938 1941
18211575961 12 1527 1539
18320173382 18 9531 9549
84138413 4116 1432 5548
2.2 引入hadoop自定义排序
从上面得到的结果可以看出来,hadoop默认将结果按照mapper的输出按照key来进行排序,如果我们想要自定义排序结果(比如按照总流量从高到低排序),该如何做呢?了解shuffle的都知道,shuffle过程中,会将map的输出结果按照key进行排序,所以只需要将FlowBean作为map输出的key值,前提是FlowBean实现了Comparable接口。在hadoop中既实现Writable接口,又实现Comparable接口,可以简写为实现了WritableComparable接口。
FlowBean:
package cn.nuc.hadoop.mapreduce.flowsort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable {
private String phoneNB;
private long up_flow;
private long down_flow;
private long sum_flow;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long down_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.down_flow = down_flow;
this.sum_flow = up_flow + down_flow;
}
// 将对象的数据序列化到流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(down_flow);
out.writeLong(sum_flow);
}
// 从流中反序列化出对象的数据
// 从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException {
this.phoneNB = in.readUTF();
this.up_flow = in.readLong();
this.down_flow = in.readLong();
this.sum_flow = in.readLong();
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getDown_flow() {
return down_flow;
}
public void setDown_flow(long down_flow) {
this.down_flow = down_flow;
}
public long getSum_flow() {
return sum_flow;
}
public void setSum_flow(long sum_flow) {
this.sum_flow = sum_flow;
}
@Override
public String toString() {
return "" + up_flow + "\t" + down_flow + "\t" + sum_flow;
}
// 实现Comparable接口,需要复写compareTo方法
@Override
public int compareTo(FlowBean o) {
return this.sum_flow > o.sum_flow ? -1 : 1;
}
}
SortMapReduce:
package cn.nuc.hadoop.mapreduce.flowsort;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SortMapReduce {
public static class SortMapper extends
Mapper {
@Override
protected void map(
LongWritable k1,
Text v1,
Mapper.Context context)
throws IOException, InterruptedException {
String line = v1.toString();
String[] fields = StringUtils.split(line, "\t");
String phoneNB = fields[0];
long up_flow = Long.parseLong(fields[1]);
long down_flow = Long.parseLong(fields[2]);
context.write(new FlowBean(phoneNB, up_flow, down_flow),
NullWritable.get());
}
}
public static class SortReducer extends
Reducer {
@Override
protected void reduce(FlowBean k2, Iterable v2s,
Reducer.Context context)
throws IOException, InterruptedException {
String phoneNB = k2.getPhoneNB();
context.write(new Text(phoneNB), k2);
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SortMapReduce.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打成jar包,运行:
[hadoop@master ~]$ hadoop jar flowcountsort.jar cn.nuc.hadoop.mapreduce.flowsort.SortMapReduce /user/exe_mapreduce/flowcount/output /user/exe_mapreduce/flowcount/sortout/
查看结果:
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/sortout/part-r-00000
13726238888 2481 24681 27162
13726230503 2481 24681 27162
13925057413 63 11058 11121
18320173382 18 9531 9549
13502468823 102 7335 7437
13660577991 9 6960 6969
13922314466 3008 3720 6728
13560439658 5892 400 6292
84138413 4116 1432 5548
15013685858 27 3659 3686
15920133257 20 3156 3176
13602846565 12 1938 1950
15989002119 3 1938 1941
13926435656 1512 200 1712
18211575961 12 1527 1539
13560436666 954 200 1154
13480253104 180 200 380
13760778710 120 200 320
13826544101 0 200 200
13926251106 0 200 200
13719199419 0 200 200
2.3 引入Hadoop分区功能
如果信息特别多,想要将最后的结果分别存放在不通过的文件中,该怎么办呢?可以使用Hadoop提供的Partitioner函数,hadoop默认使用HashPartitioner。可以查看下Hadoop源码:
public class HashPartitioner extends Partitioner {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner是处理Mapper任务输出的,getPartition()方法有三个形参,key、value分别指的是Mapper任务的输出,numReduceTasks指的是设置的Reducer任务数量,默认值是1。那么任何整数与1相除的余数肯定是0。也就是说getPartition(…)方法的返回值总是0。也就是Mapper任务的输出总是送给一个Reducer任务,最终只能输出到一个文件中。据此分析,如果想要最终输出到多个文件中,在Mapper任务中对数据应该划分到多个区中。
AreaPartitioner
package cn.nuc.hadoop.mapreduce.areapartition;
import java.util.HashMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class AreaPartitioner extends Partitioner {
private static HashMap areaMap = new HashMap<>();
static {
areaMap.put("135", 0);
areaMap.put("136", 1);
areaMap.put("137", 2);
areaMap.put("138", 3);
areaMap.put("139", 4);
}
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 从key中拿到手机号,查询手机归属地字典,不同的省份返回不同的组号
Integer areCoder = areaMap.get(key.toString().substring(0, 3));
if (areCoder == null) {
areCoder = 5;
}
return areCoder;
}
}
FlowBean
package cn.nuc.hadoop.mapreduce.areapartition;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable {
private String phoneNB;
private long up_flow;
private long down_flow;
private long sum_flow;
// 在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean() {
}
// 为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long down_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.down_flow = down_flow;
this.sum_flow = up_flow + down_flow;
}
// 将对象的数据序列化到流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(down_flow);
out.writeLong(sum_flow);
}
// 从流中反序列化出对象的数据
// 从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException {
this.phoneNB = in.readUTF();
this.up_flow = in.readLong();
this.down_flow = in.readLong();
this.sum_flow = in.readLong();
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getDown_flow() {
return down_flow;
}
public void setDown_flow(long down_flow) {
this.down_flow = down_flow;
}
public long getSum_flow() {
return sum_flow;
}
public void setSum_flow(long sum_flow) {
this.sum_flow = sum_flow;
}
@Override
public String toString() {
return "" + up_flow + "\t" + down_flow + "\t" + sum_flow;
}
// 实现Comparable接口,需要复写compareTo方法
@Override
public int compareTo(FlowBean o) {
return this.sum_flow > o.sum_flow ? -1 : 1;
}
}
FlowSumArea
package cn.nuc.hadoop.mapreduce.areapartition;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件 需要自定义改造两个机制: 1、改造分区的逻辑,自定义一个partitioner
* 2、自定义reduer task的并发任务数
*
* @author [email protected]
*
*/
public class FlowSumArea {
public static class FlowSumAreaMapper extends
Mapper {
@Override
protected void map(LongWritable k1, Text v1,
Mapper.Context context)
throws IOException, InterruptedException {
String line = v1.toString();
String[] fields = StringUtils.split(line, "\t");
String phoneNB = fields[1];
Long up_flow = Long.parseLong(fields[7]);
Long down_flow = Long.parseLong(fields[8]);
context.write(new Text(phoneNB), new FlowBean(phoneNB, up_flow,
down_flow));
}
}
public static class FlowSumAreaReducer extends
Reducer {
@Override
protected void reduce(Text k2, Iterable v2s,
Reducer.Context context)
throws IOException, InterruptedException {
long up_flow = 0;
long down_flow = 0;
for (FlowBean v2 : v2s) {
up_flow += v2.getUp_flow();
down_flow += v2.getDown_flow();
}
context.write(new Text(k2), new FlowBean(k2.toString(), up_flow,
down_flow));
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumArea.class);
job.setMapperClass(FlowSumAreaMapper.class);
job.setReducerClass(FlowSumAreaReducer.class);
// 定义分组逻辑类
job.setPartitionerClass(AreaPartitioner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设定reducer的任务并发数,应该跟分组的数量保持一致
job.setNumReduceTasks(6);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打包运行:
[hadoop@master ~]$ hadoop jar area.jar cn.nuc.hadoop.mapreduce.areapartition.FlowSumArea /user/exe_mapreduce/flowcount/input /user/exe_mapreduce/flowcount/areaout
查看结果:
[hadoop@master ~]$ hadoop fs -ls /user/exe_mapreduce/flowcount/areaout/
Found 7 items
-rw-r--r-- 3 hadoop supergroup 0 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 77 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00000
-rw-r--r-- 3 hadoop supergroup 49 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00001
-rw-r--r-- 3 hadoop supergroup 104 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00002
-rw-r--r-- 3 hadoop supergroup 22 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00003
-rw-r--r-- 3 hadoop supergroup 102 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00004
-rw-r--r-- 3 hadoop supergroup 172 2016-02-07 19:28 /user/exe_mapreduce/flowcount/areaout/part-r-00005
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00000
13502468823 102 7335 7437
13560436666 954 200 1154
13560439658 5892 400 6292
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00001
13602846565 12 1938 1950
13660577991 9 6960 6969
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00002
13719199419 0 200 200
13726230503 2481 24681 27162
13726238888 2481 24681 27162
13760778710 120 200 320
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00003
^[[A13826544101 0 200 200
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00004
^[[A13922314466 3008 3720 6728
13925057413 63 11058 11121
13926251106 0 200 200
13926435656 1512 200 1712
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/flowcount/areaout/part-r-00005
13480253104 180 200 380
15013685858 27 3659 3686
15920133257 20 3156 3176
15989002119 3 1938 1941
18211575961 12 1527 1539
18320173382 18 9531 9549
84138413 4116 1432 5548
3. 数据去重
“ 数据去重”主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。 统计大 数据集上的数据种类个数、 从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据 去重。下面就进入这个实例的 MapReduce 程序设计。
3.1 实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入如下所示:
file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
样例输出如下:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
3.2 设计思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台 reduce 机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是 reduce 的输入应该以数据作为 key,而对 value-list 则没有要求。当 reduce 接收到一个
在 MapReduce 流程中, map 的输出
3.3 程序代码
DedupMapper:
package cn.nuc.hadoop.mapreduce.dedup;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DedupMapper extends Mapper {
private static Text field = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
field = value;
context.write(field, NullWritable.get());
}
}
DedupReducer:
package cn.nuc.hadoop.mapreduce.dedup;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DedupReducer extends
Reducer {
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
DedupRunner:
package cn.nuc.hadoop.mapreduce.dedup;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DedupRunner {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DedupRunner.class);
job.setMapperClass(DedupMapper.class);
job.setReducerClass(DedupReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
打成jar包后运行:
[hadoop@master ~]$ hadoop jar dedup.jar cn.nuc.hadoop.mapreduce.dedup.DedupRunner /user/exe_mapreduce/dedup/input /user/exe_mapreduce/dedup/out
查看结果:
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/dedup/output/part-r-00000
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
4. 数据排序
“ 数据排序”是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据 操作打好基础。下面进入这个示例。
4.1 实例描述
对输入文件中数据进行排序。 输入文件中的每行内容均为一个数字, 即一个数据。要求在输出中每行有两个间隔的数字,其中, 第一个代表原始数据在原始数据集中的位次, 第 二个代表原始数据。
样例输入:
file1:
2
32
654
32
15
756
65223
file2:
5956
22
650
92
file3:
26
54
6
样例输出:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
4.2 设计思路
这个实例仅仅要求对输入数据进行排序,熟悉 MapReduce 过程的读者会很快想到在 MapReduce 过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的 排序呢?答案是肯定的。
但是在使用之前首先需要了解它的默认排序规则。它是按照 key 值进行排序的,如果 key 为封装 int 的 IntWritable 类型,那么 MapReduce 按照数字大小对 key 排序,如果 key 为封装为 String 的 Text 类型,那么 MapReduce 按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装 int 的 IntWritable 型数据结构了。也就是在 map 中将读入的数据转化成 IntWritable 型,然后作为 key 值输出( value 任意)。 reduce 拿到
4.3 程序代码
SortMapper:
package cn.nuc.hadoop.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//map将输入中的 value化成 IntWritable类型,作为输出的 key
public class SortMapper extends
Mapper {
private static IntWritable data = new IntWritable();
private static final IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, one);
}
}
SortReducer:
package cn.nuc.hadoop.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
//reduce 将输入中的 key 复制到输出数据的 key 上,
//然后根据输入的 value‐list 中元素的个数决定 key 的输出次数
//用全局linenumber来代表key的位次
public class SortReducer extends
Reducer {
private static IntWritable linenumber = new IntWritable(1);
@Override
protected void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
for (IntWritable value : values) {
context.write(linenumber, key);
linenumber.set(linenumber.get() + 1);
// linenumber=new IntWritable(linenumber.get()+1);
}
}
}
SotrRunner:
package cn.nuc.hadoop.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SortRunner {
public static void main(String[] args) throws IllegalArgumentException,
IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SortRunner.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
打成jar包运行:
[hadoop@master ~]$ hadoop jar sort.jar cn.nuc.hadoop.mapreduce.sort.SortRunner /user/exe_mapreduce/sort/input /user/exe_mapreduce/sort/output
查看结果:
[hadoop@master input]$ hadoop fs -cat /user/exe_mapreduce/sort/output/part-r-00000
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
5 平均成绩
“平均成绩”主要目的还是在重温经典“ WordCount”例子,可以说是在基础上的微变 化版,该实例主要就是实现一个计算学生平均成绩的例子。
5.1 实例描述
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名 和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔 的数据,其中, 第一个代表学生的姓名, 第二个代表其平均成绩。
样本输入:
math:
张三 88
李四 99
王五 66
赵六 77
china:
张三 78
李四 89
王五 96
赵六 67
english:
张三 80
李四 82
王五 84
赵六 86
样本输出:
张三 82
李四 90
王五 82
赵六 76
5.2 设计思路
计算学生平均成绩是一个仿“ WordCount”例子,用来重温一下开发 MapReduce 程序的 流程。程序包括两部分的内容: Map 部分和 Reduce 部分,分别实现了 map 和 reduce 的功能。
Map 处理的是一个纯文本文件,文件中存放的数据时每一行表示一个学生的姓名和他 相应一科成绩。 Mapper 处理的数据是由 InputFormat 分解过的数据集,其中 InputFormat 的 作用是将数据集切割成小数据集 InputSplit,每一个 InputSlit 将由一个 Mapper 负责处理。此 外,InputFormat 中还提供了一个 RecordReader 的实现,并将一个 InputSplit 解析成
Map 的结果会通过 partion 分发到 Reducer, Reducer 做完 Reduce 操作后,将通过以格 式 OutputFormat 输出。
Mapper 最终处理的结果对
5.3 程序代码
ScoreMapper:
package cn.nuc.hadoop.mapreduce.score;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class ScoreMapper extends Mapper {
private static Text name = new Text();
private static IntWritable score = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, " ");
String strName = fields[0];//学生姓名
int strScore = Integer.parseInt(fields[1]);//学生单科成绩
name.set(strName);
score.set(strScore);
context.write(name, score);
}
}
ScoreReducer:
package cn.nuc.hadoop.mapreduce.score;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ScoreReducer extends Reducer {
private static IntWritable avg_score = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum_score = 0;//统计总成绩
int count=0;//统计总的科目数
for (IntWritable score : values) {
count++;
sum_score += score.get();
}
avg_score.set(sum_score / count);
context.write(key, avg_score);
}
}
ScoreRunner:
package cn.nuc.hadoop.mapreduce.score;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ScoreRunner {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ScoreRunner.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
打成jar包执行:
[hadoop@master ~]$ hadoop jar score.jar cn.nuc.hadoop.mapreduce.score.ScoreRunner /user/exe_mapreduce/score/input /user/exe_mapreduce/score/output
查看结果:
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/score/output/part-r-00000
张三 82
李四 90
王五 82
赵六 76
6 倒排索引
“ 倒排索引”是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。 它主要是用来存储某个单词(或词组) 在一个文档或一组文档中的存储位置的映射,即提 供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进 行相反的操作,因而称为倒排索引( Inverted Index)。
6.1 实例描述
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的 文档或者是标识文档的 ID 号,或者是指文档所在位置的 URL,如图 6.1-1 所示。
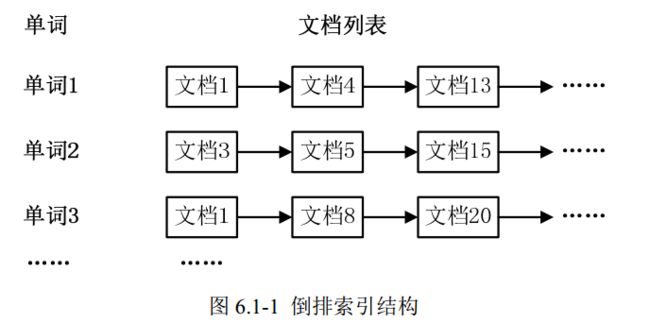
从图 6.1-1 可以看出,单词 1 出现在{文档 1,文档 4,文档 13, ……}中,单词 2 出现 在{文档 3,文档 5,文档 15, ……}中,而单词 3 出现在{文档 1,文档 8,文档 20, ……} 中。在实际应用中, 还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相 关度,如图 6.1-2 所示。

最常用的是使用词频作为权重,即记录单词在文档中出现的次数。以英文为例,如图 6.1-3 所示,索引文件中的“ MapReduce”一行表示:“ MapReduce”这个单词在文本 T0 中 出现过 1 次,T1 中出现过 1 次,T2 中出现过 2 次。当搜索条件为“ MapReduce”、“ is”、“ Simple” 时,对应的集合为: {T0, T1, T2}∩{T0, T1}∩{T0, T1}={T0, T1},即文档 T0 和 T1 包 含了所要索引的单词,而且只有 T0 是连续的。
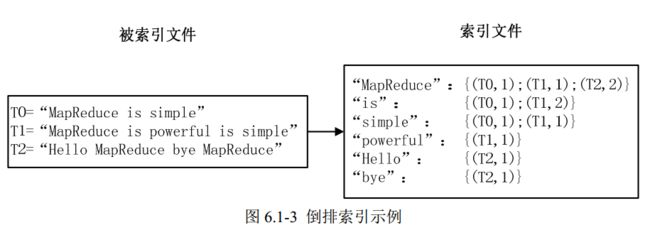
更复杂的权重还可能要记录单词在多少个文档中出现过,以实现 TF-IDF( Term Frequency-Inverse Document Frequency)算法,或者考虑单词在文档中的位置信息(单词是 否出现在标题中,反映了单词在文档中的重要性)等。
样例输入如下所示。
file1:
MapReduce is simple
file2:
MapReduce is powerful is simple
file3:
Hello MapReduce bye MapReduce
样例输出如下所示:
MapReduce file1.txt:1;file2.txt:1;file3.txt:2;
is file1.txt:1;file2.txt:2;
simple file1.txt:1;file2.txt:1;
powerful file2.txt:1;
Hello file3.txt:1;
bye file3.txt:1;
6.2 设计思路
实现“ 倒排索引”只要关注的信息为: 单词、 文档 URL 及词频,如图 3-11 所示。但是 在实现过程中,索引文件的格式与图 6.1-3 会略有所不同,以避免重写 OutPutFormat 类。下 面根据 MapReduce 的处理过程给出倒排索引的设计思路。
1)Map过程
首先使用默认的 TextInputFormat 类对输入文件进行处理,得到文本中每行的偏移量及 其内容。显然, Map 过程首先必须分析输入的
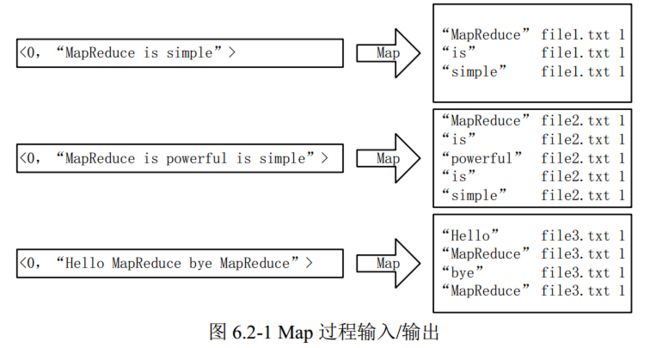
这里存在两个问题: 第一,
这里讲单词和 URL 组成 key 值(如“ MapReduce: file1.txt”),将词频作为 value,这样 做的好处是可以利用 MapReduce 框架自带的 Map 端排序,将同一文档的相同单词的词频组 成列表,传递给 Combine 过程,实现类似于 WordCount 的功能。
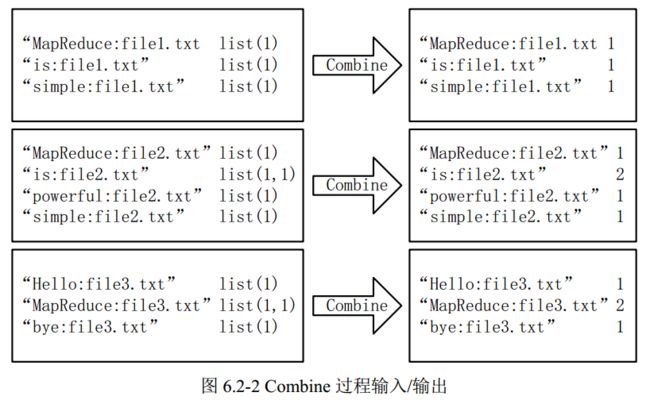
2)Combine过程
经过 map 方法处理后, Combine 过程将 key 值相同的 value 值累加,得到一个单词在文 档在文档中的词频,如图 6.2-2 所示。 如果直接将图 6.2-2 所示的输出作为 Reduce 过程的输 入,在 Shuffle 过程时将面临一个问题:所有具有相同单词的记录(由单词、 URL 和词频组 成) 应该交由同一个 Reducer 处理,但当前的 key 值无法保证这一点,所以必须修改 key 值 和 value 值。这次将单词作为 key 值, URL 和词频组成 value 值(如“ file1.txt: 1”)。这样 做的好处是可以利用 MapReduce 框架默认的 HashPartitioner 类完成 Shuffle 过程,将相同单 词的所有记录发送给同一个 Reducer 进行处理。
3)Reduce过程
经过上述两个过程后, Reduce 过程只需将相同 key 值的 value 值组合成倒排索引文件所 需的格式即可,剩下的事情就可以直接交给 MapReduce 框架进行处理了。如图 6.2-3 所示。 索引文件的内容除分隔符外与图 6.1-3 解释相同。
4)需要解决的问题
本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大(具体值与默 认 HDFS 块大小及相关配置有关),要保证每个文件对应一个 split。否则,由于 Reduce 过 程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。可以通过重写 InputFormat 类将每个文件为一个 split,避免上述情况。或者执行两次 MapReduce, 第一次 MapReduce 用于统计词频, 第二次 MapReduce 用于生成倒排索引。除此之外,还可以利用 复合键值对等实现包含更多信息的倒排索引。

6.3 程序代码
InvertedIndexMapper:
package cn.nuc.hadoop.mapreduce.invertedindex;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class InvertedIndexMapper extends Mapper {
private static Text keyInfo = new Text();// 存储单词和 URL 组合
private static final Text valueInfo = new Text("1");// 存储词频,初始化为1
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, " ");// 得到字段数组
FileSplit fileSplit = (FileSplit) context.getInputSplit();// 得到这行数据所在的文件切片
String fileName = fileSplit.getPath().getName();// 根据文件切片得到文件名
for (String field : fields) {
// key值由单词和URL组成,如“MapReduce:file1”
keyInfo.set(field + ":" + fileName);
context.write(keyInfo, valueInfo);
}
}
}
InvertedIndexCombiner:
package cn.nuc.hadoop.mapreduce.invertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class InvertedIndexCombiner extends Reducer {
private static Text info = new Text();
// 输入:
// 输出:
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;// 统计词频
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
// 重新设置 value 值由 URL 和词频组成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新设置 key 值为单词
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
}
InvertedIndexReducer:
package cn.nuc.hadoop.mapreduce.invertedindex;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class InvertedIndexReducer extends Reducer {
private static Text result = new Text();
// 输入:
// 输出:
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key, result);
}
}
InvertedIndexRunner:
package cn.nuc.hadoop.mapreduce.invertedindex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndexRunner {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedIndexRunner.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 检查参数所指定的输出路径是否存在,若存在,先删除
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打成jar包并执行:
hadoop jar invertedindex.jar cn.nuc.hadoop.mapreduce.invertedindex.InvertedIndexRunner /user/exe_mapreduce/invertedindex/input /user/exe_mapreduce/invertedindex/output
查看结果:
[hadoop@master ~]$ hadoop fs -cat /user/exe_mapreduce/invertedindex/output/part-r-00000
Hello file3:1;
MapReduce file3:2;file1:1;file2:1;
bye file3:1;
is file1:1;file2:2;
powerful file2:1;
simple file2:1;file1:1;
想学人工智能(Python、数据分析、机器学习、深度学习、推荐系统、强化学习),来公众号AI派看看吧!!