Mybatis源码学习-缓存模块分析
Mybatis源码学习-缓存模块
- 装饰器模式
- 装饰器在Mybatis缓存模块的使用
- Cache:Cache 接口是缓存模块的核心接口,定义了缓存的基本操作
- PerpetualCache:在缓存模块中扮演ConcreteComponent 角色,使用 HashMap来实现 cache 的相关操作
- BlockingCache:阻塞版本的缓存装饰器,保证只有一个线程到数据库去查找指定的 key 对应的数据
- LoggingCache:日志能力的缓存 --- 当使用缓存查询的时候,打印相关日志
- ScheduledCache:定时清空的缓存
- SerializedCache:序列化缓存。用于保证线程安全
- SynchronizedCache:进行同步控制的缓存 相关方法都加了synchronized 关键字
- LruCache:LRU回收策略的缓存
- FifoCache :FIFO回收策略的缓存
- CacheKey--- 用来标识是否存在缓存
- Mybatis 缓存的使用
- 一级缓存
- 缓存失效原因
- 二级缓存
使用的设计模式:
- 装饰器模式
为什么要用装饰器模式?
Mybatis缓存的核心模块就是在缓存中读写数据,但是除了在缓存中读写数据wait,还有其他的附加功能,这些附加功能可以任意的加在缓存这个核心功能上。
加载附加功能可以有很多种方法,动态代理或者继承都可以实现,但是附加功能存在多种组合,用这两种方法,会导致生成大量的子类,所以mybatis选择使用装饰器模式.(灵活性、扩展性)
装饰器模式
装饰器模式是一种用于代替继承的技术,无需通过继承增加子类就能扩展对象的新功能。使
用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。
类图:

Component:组件。组件接口定义了全部组件类和装饰器实现的行为。
ConcreteComponent:组件实现类。实现Component接口,被装饰器装饰的原始对象(增强的对象),新功能(附加功能)都是通过装饰器添加到该类的对象上的。
Decorator:装饰器抽象类。实现Component接口的抽象类,包含一个被装饰的对象
ConreteDecorator1: 具体装饰器类。实现了附加功能的装饰器类
IO输入输出流就是明显的一个装饰器模式的使用
装饰器在Mybatis缓存模块的使用
Cache:Cache 接口是缓存模块的核心接口,定义了缓存的基本操作
public interface Cache {
String getId();//缓存实现类的id
void putObject(Object key, Object value);//往缓存中添加数据,key一般是CacheKey对象
Object getObject(Object key);//根据指定的key从缓存获取数据
Object removeObject(Object key);//根据指定的key从缓存删除数据
void clear();//清空缓存
int getSize();//获取缓存的个数
ReadWriteLock getReadWriteLock();//获取读写锁
}
PerpetualCache:在缓存模块中扮演ConcreteComponent 角色,使用 HashMap来实现 cache 的相关操作
public class PerpetualCache implements Cache {
private final String id;
private Map<Object, Object> cache = new HashMap<>(); // 存储数据
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
BlockingCache:阻塞版本的缓存装饰器,保证只有一个线程到数据库去查找指定的 key 对应的数据
防止缓存雪崩,用ConcurrentHashMap来进行细粒度加锁,其相关源码如下
public class BlockingCache implements Cache {
//阻塞的超时时长
private long timeout;
//被装饰的底层对象,一般是PerpetualCache
private final Cache delegate;
//锁对象集,粒度到key值
private final ConcurrentHashMap<Object, ReentrantLock> locks;
public BlockingCache(Cache delegate) {
this.delegate = delegate;
this.locks = new ConcurrentHashMap<>();
}
@Override
public void putObject(Object key, Object value) {
try {
delegate.putObject(key, value);
} finally {
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
acquireLock(key);//根据key获得锁对象,获取锁成功加锁,获取锁失败阻塞一段时间重试
Object value = delegate.getObject(key);
if (value != null) {//获取数据成功的,要释放锁
releaseLock(key);
}
return value;
}
@Override
public Object removeObject(Object key) {
// despite of its name, this method is called only to release locks
releaseLock(key);
return null;
}
private ReentrantLock getLockForKey(Object key) {
ReentrantLock lock = new ReentrantLock();//创建锁
ReentrantLock previous = locks.putIfAbsent(key, lock);//把新锁添加到locks集合中,如果添加成功使用新锁,如果添加失败则使用locks集合中的锁
return previous == null ? lock : previous;
}
//根据key获得锁对象,获取锁成功加锁,获取锁失败阻塞一段时间重试
private void acquireLock(Object key) {
//获得锁对象
Lock lock = getLockForKey(key);
if (timeout > 0) {//使用带超时时间的锁
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {//如果超时抛出异常
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {//使用不带超时时间的锁
lock.lock();
}
}
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
// 此处有省略代码......
}
LoggingCache:日志能力的缓存 — 当使用缓存查询的时候,打印相关日志
public class LoggingCache implements Cache {
private final Log log;
private final Cache delegate;
protected int requests = 0; // 请求次数
protected int hits = 0; // 命中次数
public LoggingCache(Cache delegate) {
this.delegate = delegate;
this.log = LogFactory.getLog(getId());
}
@Override
public Object getObject(Object key) {
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
hits++; // 命中
}
if (log.isDebugEnabled()) {
// 如果开启了DEBUG模式,则输出命中率
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
// 获取命中率
private double getHitRatio() {
return (double) hits / (double) requests;
}
// 此处有省略代码......
}
ScheduledCache:定时清空的缓存
public class ScheduledCache implements Cache {
private final Cache delegate;
protected long clearInterval; // 清除的时间间隔
protected long lastClear; // 上一次清除的时间
public ScheduledCache(Cache delegate) {
this.delegate = delegate;
this.clearInterval = 60 * 60 * 1000; // 1 hour
this.lastClear = System.currentTimeMillis();
}
public void setClearInterval(long clearInterval) {
this.clearInterval = clearInterval;
}
@Override
public int getSize() {
clearWhenStale();
return delegate.getSize();
}
@Override
public void putObject(Object key, Object object) {
clearWhenStale();
delegate.putObject(key, object);
}
@Override
public Object removeObject(Object key) {
clearWhenStale();
return delegate.removeObject(key);
}
@Override
public void clear() {
// 更新清空时间
lastClear = System.currentTimeMillis();
delegate.clear();
}
private boolean clearWhenStale() {
// 判断是否到清空时间
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
// 此处有省略代码......
}
SerializedCache:序列化缓存。用于保证线程安全
为什么会线程不安全?
因为在取出数据的时候,并不是真正的将对象取出,而是取出对象的引用,当多个线程同时操作这个数据对象时,就会出现线程不安全的状态 (一个线程修改后,其他线程拿到的都是修改后的对象)
而字节在反序列化时,会创建一个新的对象,所以每个线程拿到反序列化后的对象都是唯一的。
public class SerializedCache implements Cache {
private final Cache delegate;
public SerializedCache(Cache delegate) {
this.delegate = delegate;
}
@Override
public void putObject(Object key, Object object) {
if (object == null || object instanceof Serializable) {
// 先序列化后再存放到缓存中
delegate.putObject(key, serialize((Serializable) object));
} else {
throw new CacheException("SharedCache failed to make a copy of a non-serializable object: " + object);
}
}
@Override
public Object getObject(Object key) {
Object object = delegate.getObject(key);
// 不为空,则反序列化,生成一份Copy
return object == null ? null : deserialize((byte[]) object);
}
private byte[] serialize(Serializable value) {
try (
// 序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos)) {
oos.writeObject(value);
oos.flush();
return bos.toByteArray();
} catch (Exception e) {
throw new CacheException("Error serializing object. Cause: " + e, e);
}
}
private Serializable deserialize(byte[] value) {
Serializable result;
try (
// 反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(value);
ObjectInputStream ois = new CustomObjectInputStream(bis)) {
result = (Serializable) ois.readObject();
} catch (Exception e) {
throw new CacheException("Error deserializing object. Cause: " + e, e);
}
return result;
}
public static class CustomObjectInputStream extends ObjectInputStream {
public CustomObjectInputStream(InputStream in) throws IOException {
super(in);
}
@Override
protected Class<?> resolveClass(ObjectStreamClass desc) throws IOException, ClassNotFoundException {
// 此方法只有在待序列化的类第一次序列化的时候才会被调用
// 遍历所支持的ClassLoader,加载对应的Class
return Resources.classForName(desc.getName());
}
}
// 此处有省略代码......
}
SynchronizedCache:进行同步控制的缓存 相关方法都加了synchronized 关键字
ps:Mybatis中的二级缓存使用了HashMap,却不会引起线程不安全就是因为添加了这个装饰器
public class SynchronizedCache implements Cache {
private final Cache delegate;
public SynchronizedCache(Cache delegate) {
this.delegate = delegate;
}
@Override
public synchronized int getSize() {
return delegate.getSize();
}
@Override
public synchronized void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
@Override
public synchronized Object getObject(Object key) {
return delegate.getObject(key);
}
@Override
public synchronized Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public synchronized void clear() {
delegate.clear();
}
// 此处有省略代码......
}
LruCache:LRU回收策略的缓存
public class LruCache implements Cache {
private final Cache delegate;
private Map<Object, Object> keyMap;
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
// 初始化设置LRU回收的边界容量
setSize(1024);
}
public void setSize(final int size) {
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
// 键值移除策略,当大于指定容量时则移除最近最少使用的key/value
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 保存需要移除的键,因为在被包装的类中并不知道什么键需要移除
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
// 将当前Key放到LRU的Map中,如果大于指定容量,则移除筛选的键值对
cycleKeyList(key);
}
@Override
public Object getObject(Object key) {
// 让当前LRU的Map知道使用过
keyMap.get(key); //touch
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
// 这里没有移除当前维护的key,不过在后续也会被回收,可以忽略
return delegate.removeObject(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
// 从Cache中移除掉LRU筛选出的键值对
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
// 省略部分代码...
}
FifoCache :FIFO回收策略的缓存
public class FifoCache implements Cache {
// 被包装的类
private final Cache delegate;
// 队列,用来维持FIFO
private LinkedList<Object> keyList;
// 最大可容纳的大小
private int size;
public FifoCache(Cache delegate) {
this.delegate = delegate;
this.keyList = new LinkedList<Object>();
this.size = 1024;
}
@Override
public void putObject(Object key, Object value) {
// 将Key放入队列中,并且检查一遍,如果满了则移除队列头部的元素
cycleKeyList(key);
// 执行真正的操作
delegate.putObject(key, value);
}
private void cycleKeyList(Object key) {
// 将Key放入队列
keyList.addLast(key);
if (keyList.size() > size) {
// 超出指定容量,移除队列头部Key
Object oldestKey = keyList.removeFirst();
// 从缓存中移除Key对应的值
delegate.removeObject(oldestKey);
}
}
// 此处有省略代码......
}
CacheKey— 用来标识是否存在缓存
为什么不能通过String类型的key来当做缓存的key值?
因为Mybatis存在动态sql的缘故,所以不能单单用String来作为缓存的key (如果用String作为key,因为条件不同,sql不同,此时查询会有问题)
CacheKey构成:
1.mappedStatement的id
2.指定查询结果集的范围(分页信息)
3.查询所使用的的sql语句
4.用户传递给sql语句的实际参数值
CacheKey源码:
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
private static final int DEFAULT_MULTIPLYER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;//参与hash计算的乘数
private int hashcode;//CacheKey的hash值,在update函数中实时运算出来的
private long checksum;//校验和,hash值的和
private int count;//updateList的中元素个数
// 8/21/2017 - Sonarlint flags this as needing to be marked transient. While true if content is not serializable, this is not always true and thus should not be marked transient.
//该集合中的元素觉得两个CacheKey是否相等
private List<Object> updateList;
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLYER;
this.count = 0;
this.updateList = new ArrayList<>();
}
public CacheKey(Object[] objects) {
this();
updateAll(objects);
}
public int getUpdateCount() {
return updateList.size();
}
public void update(Object object) {
//获取object的hash值
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
//更新count、checksum以及hashcode的值
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
//将对象添加到updateList中
updateList.add(object);
}
public void updateAll(Object[] objects) {
for (Object o : objects) {
update(o);
}
}
@Override
public boolean equals(Object object) {
if (this == object) {//比较是不是同一个对象
return true;
}
if (!(object instanceof CacheKey)) {//是否类型相同
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {//hashcode是否相同
return false;
}
if (checksum != cacheKey.checksum) {//checksum是否相同
return false;
}
if (count != cacheKey.count) {//count是否相同
return false;
}
//以上都不相同,才按顺序比较updateList中元素的hash值是否一致
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
@Override
public String toString() {
StringBuilder returnValue = new StringBuilder().append(hashcode).append(':').append(checksum);
for (Object object : updateList) {
returnValue.append(':').append(ArrayUtil.toString(object));
}
return returnValue.toString();
}
@Override
public CacheKey clone() throws CloneNotSupportedException {
CacheKey clonedCacheKey = (CacheKey) super.clone();
clonedCacheKey.updateList = new ArrayList<>(updateList);
return clonedCacheKey;
}
}
Mybatis 缓存的使用
分为一级缓存跟二级缓存
– 一级缓存默认开启
– 二级缓存开启要在mapper.xml 文件中 配置
ps:二级缓存建议不要开启 因为生命周期过长,而且是根据namespace走的,所以如果有两个namespace,查询相同的sql,缓存相同的数据。其中一个namespace对该对象进行增、删、改, 就会让改缓存失效,但是另一个缓存依旧存在。
结果会导致两个查询结果出现不一致的情况
一级缓存
默认开启,生命周期是sqlSession级别,方法级别

2019-09-04 22:00:58.673 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@222114ba]
2019-09-04 22:00:58.679 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Preparing: select id, userName, realName, sex, mobile, email, note, position_id from t_user a where a.email like CONCAT('%', ?, '%') and a.sex = ?
2019-09-04 22:00:58.713 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Parameters: qq.com(String), 1(Byte)
2019-09-04 22:00:58.728 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - <== Total: 1
第一次查询:[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
2019-09-04 22:00:58.730 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Opening JDBC Connection
2019-09-04 22:00:58.741 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@43301423]
2019-09-04 22:00:58.742 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Preparing: select id, userName, realName, sex, mobile, email, note, position_id from t_user a where a.email like CONCAT('%', ?, '%') and a.sex = ?
2019-09-04 22:00:58.743 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Parameters: qq.com(String), 1(Byte)
2019-09-04 22:00:58.744 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - <== Total: 1
第二次查询:[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
可以看出,就算是相同的方法,不同sqlSession来调用,是不会走缓存的
缓存失效原因
- 增删改操作会清空缓存
(因为在Executor方法中的 update、commit等方法,会清空缓存 调用的是 clearLocalCache();这个方法)
直接查询,未进行增删改操作
代码:

控制台:

可以发现控制台只打印一次sql相关的日志,证明第二次查询是从缓存中取得值
进行了增删改操作,第二次查询缓存已经失效了,所以重新从数据库中查询
代码:
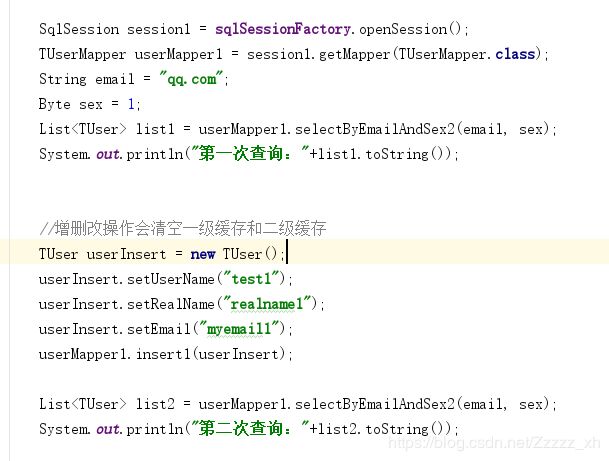
控制台:
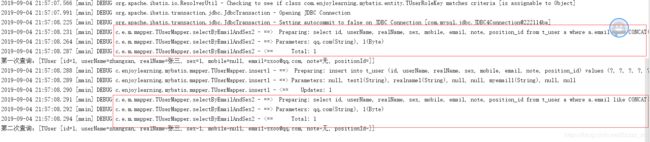
从控制台中,可以看出,插入一条数据后,改缓存就已经失效了
- 关闭sqlSession — 一级缓存失效
代码:

控制台:

可以看出,当关闭sqlSession后,在开启,缓存也失效了
二级缓存
默认不开启,生命周期是SqlSessionFactory级别,类级别,但是每个二级缓存都是跟着namespace的
同一个namespaces
代码:

控制台
2019-09-04 22:13:39.998 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Opening JDBC Connection
2019-09-04 22:13:40.224 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@29176cc1]
2019-09-04 22:13:40.230 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Preparing: select id, userName, realName, sex, mobile, email, note, position_id from t_user a where a.email like CONCAT('%', ?, '%') and a.sex = ?
2019-09-04 22:13:40.262 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Parameters: qq.com(String), 1(Byte)
2019-09-04 22:13:40.281 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - <== Total: 1
[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
2019-09-04 22:13:40.288 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@29176cc1]
2019-09-04 22:13:40.288 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@29176cc1]
2019-09-04 22:13:40.339 [main] DEBUG com.enjoylearning.mybatis.mapper.TUserMapper - Cache Hit Ratio [com.enjoylearning.mybatis.mapper.TUserMapper]: 0.5
[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
上图能看到,虽然不在同一个sqlSession中,但是因为开启了二级缓存。所以第二次查询,走的是缓存,没有在数据库中查询
不同namespaces
代码:

控制台:
2019-09-04 22:16:37.415 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Opening JDBC Connection
2019-09-04 22:16:37.672 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@29176cc1]
2019-09-04 22:16:37.677 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Preparing: select id, userName, realName, sex, mobile, email, note, position_id from t_user a where a.email like CONCAT('%', ?, '%') and a.sex = ?
2019-09-04 22:16:37.711 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - ==> Parameters: qq.com(String), 1(Byte)
2019-09-04 22:16:37.736 [main] DEBUG c.e.m.mapper.TUserMapper.selectByEmailAndSex2 - <== Total: 1
[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
2019-09-04 22:16:37.740 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Opening JDBC Connection
2019-09-04 22:16:37.750 [main] DEBUG org.apache.ibatis.transaction.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@51e5fc98]
2019-09-04 22:16:37.750 [main] DEBUG c.e.m.m.TJobHistoryMapper.selectByEmailAndSex2 - ==> Preparing: select id, userName, realName, sex, mobile, email, note, position_id from t_user a where a.email like CONCAT('%', ?, '%') and a.sex = ?
2019-09-04 22:16:37.751 [main] DEBUG c.e.m.m.TJobHistoryMapper.selectByEmailAndSex2 - ==> Parameters: qq.com(String), 1(Byte)
2019-09-04 22:16:37.753 [main] DEBUG c.e.m.m.TJobHistoryMapper.selectByEmailAndSex2 - <== Total: 1
[TUser [id=1, userName=zhangsan, realName=张三, sex=1, mobile=null, email=xxoo@qq.com, note=无, positionId=]]
上图可以看出 虽然是相同sql,参数,但是因为namespace不同,所以不会走缓存,还是查询数据库