spark的初步学习知识点
2019.05.07
什么是SPARK
Apache Spark is a fast and general for large-scala data processing
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎 。现在形成一个高速发展应用广泛的生态系统。
SPARK核心组件
spark包括四大组件:Spark Streaming(类似于Storm,进行流式计算,处理的是实时数据(流式数据))
Spark SQL(Spark处理结构化数据的引擎,类似Hive,支持SQL)
Spark Graphx(图计算)
Spark MLlib(机器学习)
Spark Core:Spark的核心组件,其操作的数据对象是RDD(弹性分布式数据集)
图中在Spark Core上面的四个组件都依赖于Spark Core

SPARK特征
快:基于内存
易用性:Spark 提供了80多个高级运算符。一方面,Spark提供了支持多种语言的API,如Scala、Java、Python、R等,使得用户开发Spark程序十分方便。另一方面,Spark是基于Scala语言开发的,由于Scala是一种面向对象的、函数式的静态编程语言,其强大的类型推断、模式匹配、隐式转换等一系列功能结合丰富的描述能力使得Spark应用程序代码非常简洁。
通用性:Spark 提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
多种运行模式:Spark支持多种运行模式:本地local运行模式、分布式运行模式。Spark集群的底层资源可以借助于外部的框架进行管理,目前Spark对Mesos和Yarn提供了相对稳定的支持。
和hadoop的区别
Spark基于SCALA语言、Hadoop基于Java语言
Spark只有计算,没有存储:MapReduce使用持久存储,而Spark使用弹性分布式数据集(RDDS)
spark基于内存,性能比hadoop快
执行SPARK任务
spark任务提交的方式:
1、Spark Submit工具:提交Spark的任务(jar文件)
spark提供的用于提交Spark任务工具
spark-submit 任务提交参数 --class 程序的main方法 jar包 main的参数列表
(*)example:/root/training/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar
SparkPi.scala 例子:蒙特卡罗求PI:
spark-submit --master spark://bigdata11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-example_2.11-2.1.0. jar 100
2、Spark Shell 工具:交互式命令行工具、作为一个Application运行
(1)本地模式 :bin/spark-shell
日志:
Spark context available as 'sc' (master = local[*], app id = local-1518181597235).
(2)集群模式:bin/spark-shell --master spark://bigdata11:7077
日志:
Spark context available as 'sc' (master = spark://bigdata11:7077, app id = app-20180209210815-0002).
(3)Idea中开发Spark的任务
SPARK对象
声明方式:
//SparkContext是Spark的入口,相当于应用程序的main函数。目前在一个JVM进程中可以创建多个SparkContext,但是只能有一个active级别的。
Spark context available as 'sc'
//SparkSession 是 Spark SQL 的入口。
Spark session available as 'spark'
说明: 在Spark 2.0后新提供一个统一的访问接口:Spark Core、Spark SQL、Spark Streaming
| sc.textFile(“hdfs://bigdata11:9000/input/data.txt”) | 通过sc对象读取HDFS的文件 |
| .flatMap(_.split(" ")) | 分词操作、压平 |
| .map((_,1)) | 每个单词记一次数 |
| .reduceByKey(_ + _) | 按照key进行reduce,再将value进行累加 |
| . saveAsTextFile(“hdfs://bigdata11:9000/output/spark/day0209/wc”) | 保存到文件 |
| .reduceByKey(a,b) | reduceByKey会寻找相同key的数据,当找到这样的两条记录时会对其value(分别记为x,y)做(x,y) => x+y的处理,即只保留求和之后的数据作为value。 |
| .reduceByKey(_ + _) | 简洁的方式,需要导入scalaz |
什么是RDD
RDD(Resilient Distributed Datasets):弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。
rdd类型
spark中的RDD操作类型可以分为四类:
创建操作(creation Operation)
创建RDD的两种方法:
一种是parallelize或者makeRDD一个已存在的集合
一种是在外部存储系统(比如HDFS、HBASE)中引用一个数据集
转换操作(transformation Operation)
将RDD通过一定的操作变换成新的RDD,比如HadoopRDD可以使用map操作变换成MappedRDD,RDD的转换操作是惰性操作,它只定义了一个新的RDDs,并没有立即执行
行为操作(action Operation)
进行RDD持久化,可以让RDD按照不用的存储策略保存在磁盘或者内存中,主要有persist、cache两个方法,实际上cache是使用persist的快捷方法,使用了默认的存储级别MEMORY_ONLY将RDD缓存在内存中
控制操作(control Operation)
主要是一些能够触发spark运行的操作,比如对RDD进行collect。spark中action操作主要分为两类,一类的操作结果变成scala的集合或者变量,另一类将RDD保存到外部文件或者数据库中
RDD的创建
1、使用sc.parallelize方法
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8),3)
//将数据分为三份
2、通过使用外部的数据源创建RDD
val rdd2 = sc.textFile("hdfs://bigdata11:9000/input/data.txt")
val rdd2 = sc.textFile(“/root/temp/input/data.txt”)//本地目录下的文件
RDD算子
1、Transformation算子(函数/操作)类:不会触发计算、延时加载(lazy值)
| Transformation算子 | ||
|---|---|---|
| map(func) | 该操作是对原来的RDD进行操作后,返回一个新的RDD | 例:进行+1的操作 例:进行+1的操作 例:进行+1的操作 |
| filter | 过滤操作、返回一个新的RDD |  过滤输入RDD中的元素,将f返回true的元素留下 过滤输入RDD中的元素,将f返回true的元素留下 |
| flatMap | 类似map | 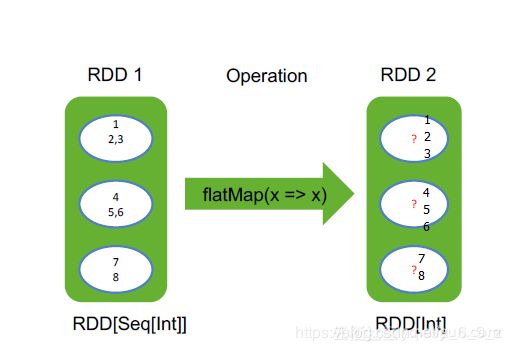 |
| mapPartitions | 对每个分区进行操作 | 无 |
| mapPartitionsWithIndex | 对每个分区进行操作,带分区的下标 | 无 |
| union | 并集 |  rdd1.union(rdd2) rdd1.union(rdd2) |
| intersection | 交集 | 无 |
| distinct | 去重 | 无 |
| groupByKey | 按照key进行分组 |  |
| reduceByKey | 按照Key进行分组、会有一个本地操作(相当于:Combiner操作 | 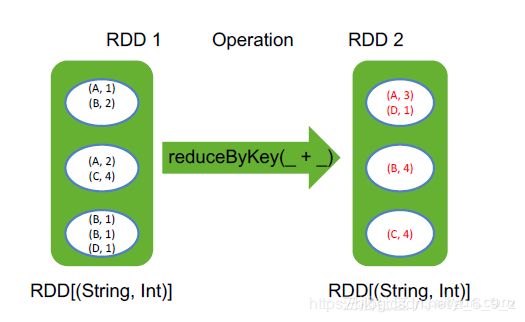 对Key相同的value做计算 对Key相同的value做计算 |
2 Action算子:会触发计算
| Action算子 | ||
|---|---|---|
| collect | 触发计算、打印屏幕上。以数组形式返回 |  将RDD转化为数组 将RDD转化为数组 |
| count | 求个数 |  统计RDD中元素个数,并返回Long类型 统计RDD中元素个数,并返回Long类型 |
| first | 第一个元素 | 无 |
| take(n) | 取第几个 |  其中k是整数,T是RDD中元素类型,返回RDD中前k个元素,并保存成数组 其中k是整数,T是RDD中元素类型,返回RDD中前k个元素,并保存成数组 |
| savaAsTextFile | 会转换成String的形式,会调用toString()方法 | |
| foreach | 在RDD的每个元素上进行某个操作 | 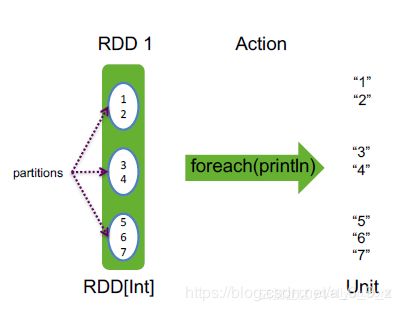 对RDD中每个元素,调用函数f 对RDD中每个元素,调用函数f |
缓存机制
RDD通过cache方法或者persist方法可以将前面的计算结果缓存,但并不是立即缓存,而是在接下来调用Action类的算子的时候,该RDD将会被缓存在计算节点的内存中,并供后面使用。它既不是transformation也不是action类的算子。
RDD默认缓存在内存中(提高效率)
<–cache方法其实是persist方法的一个特例:调用的是无参数的persist();代表缓存级别是仅内存的情况–>
rdd.cache() 是 rdd.persist(StorageLevel.MEMORY_ONLY) 的简写
注意:缓存结束后,不会产生新的RDD
Spark缓存主要有cache()和persist()两种,当缓存一个rdd时,每一个节点上都会存放这个rdd的partition,当要使用rdd的时候可以直接从内存读出。
val rdd = sc.textFile("~")
rdd.cache()//现在没有缓存
rdd.collect//遇到action开始缓存
StorageLevel定义
@DeveloperApi
class StorageLevel private(
private var _useDisk: Boolean, //是否使用磁盘
private var _useMemory: Boolean, //是否使用内存
private var _useOffHeap: Boolean, //是否使用堆外内存
private var _deserialized: Boolean, //是否反序列化
private var _replication: Int = 1) //备份因子,默认为1
extends Externalizable {
缓存级别
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val NONE = new StorageLevel(false, false, false, false)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)

容错机制
一般来说:分布式数据集的容错性有两种方式:数据检查点和记录数据的更新
checkpoint检查点为主
两种类型:(1)本地目录 :需要将spark-shell运行在本地模式上
(2)HDFS目录:需要将spark-shell运行在集群模式上
//使用很简单, 就是设置一下 checkpoint 目录,然后再rdd上调用 checkpoint 方法, action 的时候就对数据进行了 checkpoint
scala> sc.setCheckpointDir("hdfs://bigdata11:9000/spark/checkpoint")
scala> val rdd1 = sc.textFile("hdfs://bigdata11:9000/input/sales")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://bigdata11:9000/input/sales MapPartitionsRDD[41] at textFile at <console>:24
scala> rdd1.checkpoint
scala> rdd1.count
**Lineage(血统)**为辅
当这个RDD的部分分区数据丢失时,它能够通过Lineage获取足够的信息来又一次运算和恢复丢失的数据分区。由于这样的粗颗粒的数据模型,限制了Spark的运用场合,所以Spark并不适用于全部高性能要求的场景,但同一时候相比细颗粒度的数据模型,也带来了性能的提升。
RDD在Lineage依赖方面分为两种:
//DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
//在宽依赖上做Checkpoint获得的收益更大。
窄依赖(Narrow Dependencies)与宽依赖(Wide Dependencies,源代码中称为Shuffle Dependencies),用来解决数据容错的高效性。
| 依赖关系 | |
|---|---|
| 窄依赖 | 父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区相应于一个子RDD的分区 |
| 宽依赖 | 子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。 |

RDD高级算子
1、mapPartitionsWithIndex: 对RDD中的每个分区进行操作
1、mapPartitionsWithIndex: 对RDD中的每个分区进行操作,带有分区号
定义:def mapPartitionsWithIndex[U](f: (Int, Iterator[T])=>Iterator[U], preservesPartitioning: Boolean = false)
(implicit arg0: ClassTag[U]): RDD[U]
参数说明:
f: (Int, Iterator[T])=>Iterator[U]
(*)Int: 分区号
(*)Iterator[T]: 该分区中的每个元素
(*)返回值:Iterator[U]
例子:
举例:
(1)创建一个RDD:val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9),2)
(2)创建一个函数,作为f的值
def func1(index:Int,iter:Iterator[Int]):Iterator[String] ={
iter.toList.map(x=>"[PartID:" + index +",value="+x+"]").iterator
}
(3)调用
rdd1.mapPartitionsWithIndex(func1).collect
(4)结果:
Array([PartID:0,value=1], [PartID:0,value=2], [PartID:0,value=3], [PartID:0,value=4], [PartID:1,value=5], [PartID:1,value=6], [PartID:1,value=7], [PartID:1,value=8], [PartID:1,value=9])
2、aggregate:聚合操作
定义:def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
作用:先对局部进行操作,再对全局进行操作
举例:
val rdd1 = sc.parallelize(List(1,2,3,4,5),2)
(1)求每个分区最大值的和
先查看每个分区中的元素:
rdd1.mapPartitionsWithIndex(func1).collect
rdd1.aggregate(0)(math.max(_,_),_+_)
(2)改一下:
rdd1.aggregate(0)(_+_,_+_) ====> 15
rdd1.aggregate(10)(math.max(_,_),_+_) ===> 30
3、aggregateByKey
3、aggregateByKey
(1)类似aggregate,也是先对局部,再对全局
(2)区别:aggregateByKey操作<key,value>
(3)测试数据:
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
每个分区中的元素(key,value)
def func3(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
[partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)],
[partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)]
(4)把每个笼子中,每种动物最多的个数进行求和
pairRDD.aggregateByKey(0)(math.max(_,_),_+_).collect
4、coalesce和repartition
4、coalesce和repartition
(*)都是将RDD中的分区进行重分区
(*)区别:coalesce 默认:不会进行shuffle(false)
repartition 会进行shuffle
(*)举例:
创建一个RDD
val rdd4 = sc.parallelize(List(1,2,3,4,5,6,7,8,9),2)
进行重分区
val rdd5 = rdd4.repartition(3)
val rdd6 = rdd4.coalesce(3,false) ---> 分区的长度: 2
val rdd6 = rdd4.coalesce(3,true) ---> 分区的长度: 2
SPARK SQL
怎样创建数据集
//方式一:通过case class定义表
//定义一个case class来代表emp表的schema结构
case class Emp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
//导入emp.csv文件
val lines = sc.textFile("/root/temp/emp.csv").map(_.split(","))
//生成一个表:DataFrame
//将case class和RDD(lines)关联起来
Array(7369, SMITH, CLERK, 7902, 1980/12/17, 800, "", 20)
val allEmp = lines.map(x=>Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
//生成表:
val empDF = allEmp.toDF
//操作:
empDF.show
empDF.printSchema
//方式二:通过SparkSession.createDataFrame()
//什么是Spark Session?
//日志:Spark session available as 'spark'.
//从spark 2.0后,新的访问接口(统一的访问方式),通过SparkSession对象可以访问Spark的各个模块
//数据:
val empCSV = sc.textFile("/root/temp/emp.csv").map(_.split(","))
// 结构:Schema ----> 类:StructType
import org.apache.spark.sql._
import org.apache.spark.sql.types._
//参考讲义:
val myschema = StructType(List(StructField("empno", DataTypes.IntegerType),
StructField("ename",DataTypes.StringType),
StructField("job", DataTypes.StringType),
StructField("mgr", DataTypes.StringType),
StructField("hiredate", DataTypes.StringType),
StructField("sal", DataTypes.IntegerType),
StructField("comm", DataTypes.StringType),
StructField("deptno", DataTypes.IntegerType)))
//把读入的数据empCSV映射一行Row:注意这里没有带结构
import org.apache.spark.sql._
val rowRDD = empCSV.map(x=>Row(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
//通过SparkSession.createDataFrame(数据,schema结构)创建表
val df = spark.createDataFrame(rowRDD,myschema)
(3)方式三:直接读取一个具有格式的数据文件(例如:json文件)
前提:数据文件本身具有格式
Example数据文件:
/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json
示例:
val peopleDF = spark.read.json("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
创建视图
5、临时视图view:2种
1)只在当前会话中有效:
df.createOrReplaceTempView("emp")
2)Global Temporay View 在全局范围都有效(不同的会话中
df.createGlobalTempView("empG") ----> 相当于:在Spark SQL的"全局数据库"上创建的: 前缀: global_temp
3)示例
在当前会话中:
spark.sql("select * from emp").show
spark.sql("select * from global_temp.empG").show
//开启一个新的会话,重新查询
spark.newSession.sql("select * from emp").show ----> 出错
spark.newSession.sql("select * from global_temp.empG").show
提供怎样的数据源
7 选择数据源
1、load和save函数: 默认都是Parquet文件
(*)使用load函数加载数据,自动生成表(DataFrame)
(*)注意:load函数默认的数据源是Parquet文件
val usersDF = spark.read.load("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/users.parquet")
对比:
spark.read.json("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
查询:usersDF.show
(*)使用save函数保存结果
需求:查询用户的名字和喜欢的颜色,并保存
scala> usersDF.select($"name",$"favorite_color").write.save("/root/temp/result")
scala> val testResult = spark.read.load("/root/temp/result/part-00000-1dfafff2-25d3-4d5f-83c0-c3330f85c8b1.snappy.parquet")
**2、Parquet文件:是Spark SQL的Load函数默认的数据源 **
(*)特点:列式存储文件
(*)把其他文件格式转成Parquet文件 json文件 ----> parquet文件
val empJSON = spark.read.json("/root/temp/emp.json")
empJSON.write.mode("overwrite").parquet("/root/temp/result")
(*)功能:支持Schema的合并
第一个文件
val df1 = sc.makeRDD(1 to 5).map(i=>(i,i*2)).toDF("single","double")
df1.write.parquet("/root/temp/test_table/key=1")
第二个文件
val dfmakeRDD2 = sc.(6 to 10).map(i=>(i,i*3)).toDF("single","triple")
df2.write.parquet("/root/temp/test_table/key=2")
合并上面的文件
val df3 = spark.read.option("mergeSchema","true").parquet("/root/temp/test_table")
scala> df3.printSchem
root
|-- single: integer (nullable = true)
|-- double: integer (nullable = true)
|-- triple: integer (nullable = true)
|-- key: integer (nullable = true)
3、JSON文件
示例:
spark.read.json("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
另一种写法:
val df4 = spark.read.format("json").load("/root/training/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/people.json")
4、JDBC方式: 读取关系型数据库中的数据(Oracle)
(*)需要把JDBC的驱动加入
bin/spark-shell --master spark://bigdata11:7077 --jars /root/temp/ojdbc6.jar --driver-class-path /root/temp/ojdbc6.jar
(*)读取Oracle
val oracleEmp = spark.read.format("jdbc").option("url","jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com").option("dbtable","scott.emp").option("user","scott").option("password","tiger").load
使用Properties类
scala> import java.util.Properties
import java.util.Properties
scala> val prop = new Properties()
prop: java.util.Properties = {}
scala> prop.setProperty("user","scott")
res1: Object = null
scala> prop.setProperty("password","tiger")
res2: Object = null
scala> val oracleDF1 = spark.read.jdbc("jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com","scott.emp",prop)
oracleDF1: org.apache.spark.sql.DataFrame = [EMPNO: decimal(4,0), ENAME: string ... 6 more fields]
5、操作Hive的表(需要配置)
//复习Hive
(1)基于HDFS之上的数据仓a库
表(分区) ---> HDFS目录
数据 ---> HDFS文件
(2)是一个数据分析引擎,支持SQL
(3)翻译器:SQL ---> MapReduce程序
注意:从Hive 2.x开始,推荐使用Spark作为执行引擎(目前不成熟,还在开发)
参考资料:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
如何使用Spark SQL加载Hive的数据?
文档:http://spark.apache.org/docs/latest/sql-programming-guide.html#hive-tables
步骤:
(1)把Hive的配置文件和Hadoop的配置文件 ----> $SPARK_HOME/conf
hive-site.xml
core-site.xml
hdfs-site.xml
cp hadoop-2.7.3/etc/hadoop/core-site.xml spark-2.1.0-bin-hadoop2.7/conf/
cp hadoop-2.7.3/etc/hadoop/hdfs-site.xml spark-2.1.0-bin-hadoop2.7/conf/
cp apache-hive-2.3.0-bin/conf/hive-site.xml spark-2.1.0-bin-hadoop2.7/conf/
(2)启动spark-shell的时候,加入mysql的驱动
bin/spark-shell --master spark://bigdata11:7077 --jars /root/temp/mysql-connector-java-5.1.43-bin.jar
(3)参考讲义上的例子:
json是否支持
sql支持
SPARK STREAMING
四大组件:
广播变量、哪些端口、scala表达式元组怎么提出来、计算结果、内继承、抛出异常、spark的默认存储级别、
字符串和数字相乘结果是什么循环输出字符串

迭代器用法、获取集合中的元素、
3 任务提交
spark-submit
spark-shell
本地
local
直接启动就是:spark-shell
UI: localhost:4040
集群
IDE
word count 开发
SparkContext:
Spark功能的主要入口点。代表到Spark集群的连接,可以创建RDD、累加器和广播变量.
每个JVM只能激活一个SparkContext对象,在创建sc之前需要stop掉active的sc。
SparkConf:
spark配置对象,设置Spark应用各种参数,kv形式。
RDD
resilient distributed dataset,弹性分布式数据集。等价于集合。
作业提交
1.导出jar包
IDEA :快捷键 Ctrl+Alt+Shift+S
2.spark-submit提交命令运行job
提交格式:
$>spark-submit --master 集群模式 --name MyWordCount --class 类名 jar包名 [可选输入文件]
例如:
spark-submit --master local --name WordCount --class WordCount wordcount.jar
没有包名
默认本地提交
spark-submit --master spark://hadoop001:7077 --name WordCount --class WordCount wordcount.jar
集群提交
注意集群正常启动
转载:https://blog.csdn.net/wlk_328909605/article/details/82790841
https://blog.csdn.net/do_yourself_go_on/article/details/74739260
https://www.cnblogs.com/wuweikongjian/articles/8309245.html
https://blog.csdn.net/dengxing1234/article/details/73613484