NAS论文笔记——Progressive Neural Architecture Search
文章目录
- 主要工作
- 搜索空间定义
- 预测模型
- 训练预测模型
- 数据集准备
- 模型训练
- 训练结果
- MLP ensemble
- RNN与MLP的对比
- 实验
- 运行速度比较
- 发现的Cell在CIFAR10与ImageNet上的表现
主要工作
目前来说,NAS的搜索方法包含有强化学习和进化算法,论文提出了一种新方法,利用SMBO策略,即通过不断增强网络的复杂度(深度)来探索整个搜索空间,同时利用surrogate函数(其实就是surrogate-based)来指引探索过程,从而发现性能优异的网络。
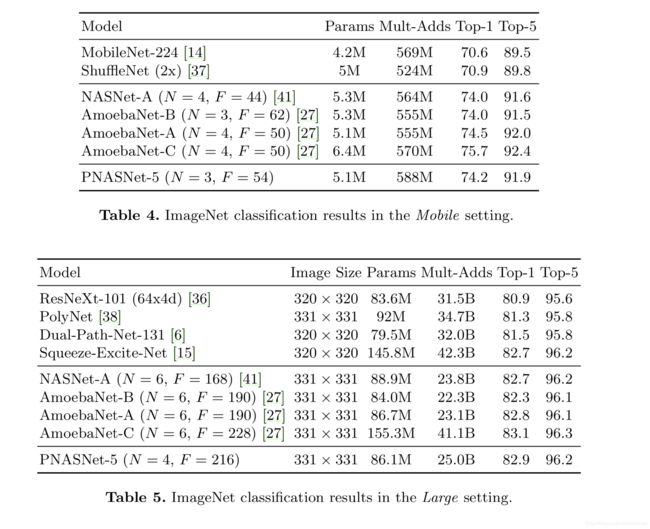
与之前基于NASNet Search Space的强化学习与进化算法相比,该算法所需的计算量少八倍,在CIFAR-10上达到同等精度所需训练的模型数量少五倍,同时搜索到的网络结构在ImageNet和CIFAR-10上达到了SOTA水准。
吐槽:是,是,是显卡燃烧的味道!本论文的作者们应该都是显卡战士,我试着跑了一下NAS相关的算法,真的好慢!!!用的单GPU…,没钱…,也可能是因为在自定义的100*100的数据集上跑的缘故,32*32大小的CIFAR-10简直是天使,相信训练速度一定会加快。
从主要工作出发,可以生出两个疑问
- 搜索空间如何定义?
- surrogate函数是啥模型,如何训练?
搜索空间定义
对NASNet Search Space进行一定的更改,就得到了本论文定义的搜索空间。
关于NASNet Search Space,可以查看我之前写过的两篇博客,在此不对其进行介绍
NAS论文笔记(使用RL进行NAS):Learning Transferable Architectures for Scalable Image Recognition
NAS论文笔记(aging evolution):Regularized Evolution for Image Classifier Architecture Search
NASNet Search Space中的Cell含有固定数目的pairwise,而本论文定义的搜索空间中Cell的pairwise数目是不固定的,并且是递增式的,直至增长至上限 B B B。举个例子,含有一个pairwise的Cell,含有两个pairwise的Cell,含有三个pairwise的Cell…含有 B B B个pairwise的Cell,整个搜索空间非常的大,作者使用了一种层次性的搜索算法,具体如下:
在第 b b b轮循环中,含有 K K K个候选Cell,每个Cell含有 b b b个 p a i r w i s e pairwise pairwise,这 K K K个候选Cell对应的网络将被训练和评估,接着这 K K K个候选Cell将派生出含有 b + 1 b+1 b+1个 p a i r w i s e pairwise pairwise的Cell,接着使用surrogate函数选出最有可能表现优异的 K K K个候选细胞,训练对应的网络并进行评估,不断重复上述过程,整个流程可以用下图来描述
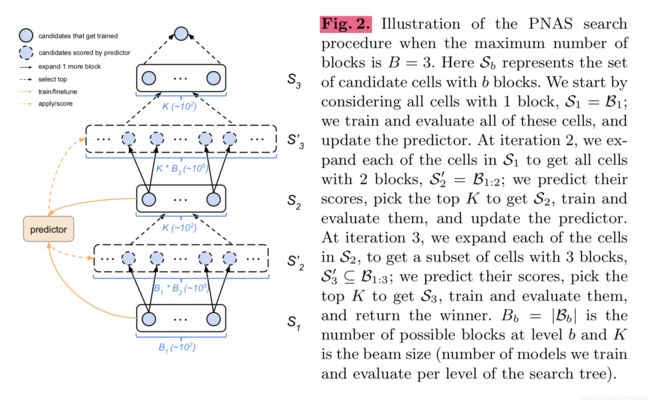
与NASNet Search Space不同的是,本论文没有区分NormalCell与ReductionCell,只是将NormalCell的stride设置为2来模拟ReductionCell,这会在一定程度上减少搜索空间的大小。
预测模型
预测模型用于预测某个cell组成的网络的性能,在NAS论文笔记——Peephole: Predicting Network Performance Before Training一文中,我解释了一下为什么可以使用LSTM、RNN等时序模型预测网络性能。这篇论文同样使用了序列模型,具体来说,需要解决的问题主要是如何对神经网络进行编码。
论文用一个四元组来 < I 1 , I 2 , O 1 , O 2 >
论文同时尝试了MLP预测网络性能,假设一个Cell有 B B B个pairwise,依据上述方法,我们可以得到 B B B个 4 D 4D 4D维的向量,接着对每一维上的数据进行平均,得到一个 4 D 4D 4D维的向量,作为MLP的输入。
训练预测模型
数据集准备
设b为Cell中pairwise的个数,b的取值为1~5,对于含有b(b>1)个pairwise的Cell,随机抽取10000个模型进行训练,b=1的所有Cell都会训练,在CIFAR10上一共训练了接近40000个模型。
模型训练
采用下列算法训练模型,K的取值为256

具体来说,模型训练的步骤如下:
- 从含有b个pairwise的cell数据集中随机抽取256个数据训练模型
- 训练好的模型会在训练数据(256个含有b个pairwise)以及测试数据(10000个含有b+1个pairwise)上进行测试
训练结果
MLP ensemble
论文给出了在训练数据以及测试数据上的线性相关系数,论文并没有解释使用了什么线性相关系数(例如皮尔逊相关系数等),可以看到,MLP-ensemble在训练数据集上的线性相关性还是不错的,但是在测试数据集上,线性相关性并不是很高,但是随着训练的进行,MLP-ensemble在测试数据集上的线性相关性逐渐上升。
RNN与MLP的对比
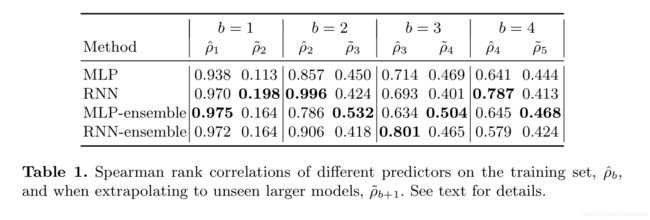
不论是否使用ensemble,RNN在训练数据上的表现都更为亮眼,而MLP在测试数据上的表现更为亮眼,这在一定程度上说明,RNN可能出现了过拟合。
实验
本部分不会过多细说实验的细节(例如优化参数等),只给出自认为比较有意思的结果
运行速度比较
在NASNet Search Space上使用强化学习的算法与PNAS(就是上面所述的算法)的性能对比结果如下:
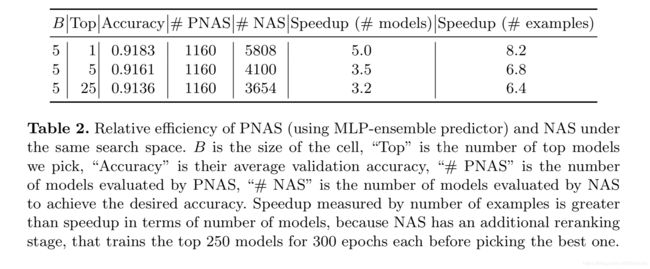
B B B表示PNAS中cell最多含有的pairwise个数,TOP表示选出N(N=1,5,25)个模型,Accuracy表示选出的N个模型的测试准确率平均值,实验从两种算法达到相同测试准确率平均值所需训练的模型数以及计算开销来比较两者的性能,PNAS的性能提升为表格中的Speedup(#models)以及Speedup(#examples)。
可以看到,PNAS能在短时间内得到较好的结果,但是这个结果不够严谨,没有把训练预测模型所需训练的模型数(约为40000个)计算在内,如果计算在内,可以看到PNAS运行所需的模型数将远比NAS多,这样的计算开销,普通实验室根本无法承担起。
论文对于计算性能的开销,即Speedup(#examples)的计算方式,是通过两个算法达到相同平均测试准确率所需的SGD步骤得出的,虽然数值很惊艳,但是同样没把训练预测模型的40000模型算进去。
以上结果不免让人有些失望,这篇论文提出的算法,任然需要耗费大量的计算资源。
发现的Cell在CIFAR10与ImageNet上的表现
具体表现如下,就不总结了,注意标为红色的语句。
CIFAR10
ImageNet