GPU的并行运算能力远超CPU,有时候我们会需要用到超大数据并行运算,可以考虑用GPU实现,这是一篇C#调用GPU进行运算的入门教程.
1: 下载相关的库:
https://sourceforge.net/projects/openclnet/
看起来已经N久没更新了, 不过没关系,这只是API声明和参数,opencl本身是有在更新的.
里面有源码也有DLL,可以引用DLL,也可以直接把源码添加到工程使用.(建议直接添加代码...)
*** 需要注意的是 ***:自己建立的工程有个默认的Program类,要改成别的名字,不然会和这里面一个同名的类冲突....
2:建立工程
打开VS建立一个C#控制台工程,Program类改名为MainProgram,添加OpenCL.Net源码引用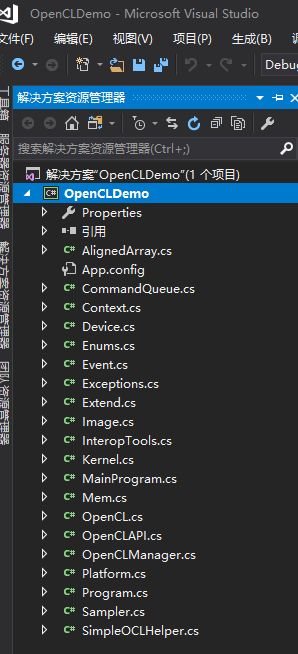
项目属性里改为[允许不安全代码]: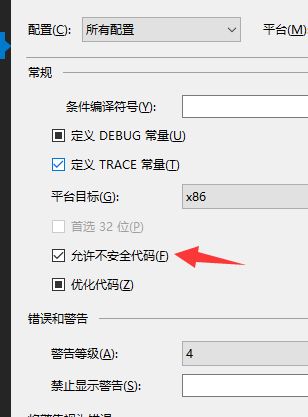
3:在MainProgram里声明引用:
using OpenCLNet;
using CL = OpenCLNet;4:在项目里添加一个Extend类,内容如下
public static class Extend
{
///
/// 取指针
///
///
/// 5:在MainProgram把一段运行在GPU的代码放在C#的字符串里:
#region OpenCL代码
private static string CLCode = @"
__kernel void vector_add_gpu(__global int* src_a, __global int* src_b, __global int* res)
{
const int idx = get_global_id(0);
res[idx] =src_a[idx] + src_b[idx];
}
__kernel void vector_inc_gpu(__global int* src_a, __global int* res)
{
const int idx = get_global_id(0);
res[idx] =src_a[idx] + 1;
}
";
#endregion6:选中一个设备
在大多数电脑上有1个CPU和2个GPU(集显,独显),有的电脑会有更多或者更少,这里需要选中一个
//获取平台数量
OpenCL.GetPlatformIDs(32, new IntPtr[32], out uint num_platforms);
var devs = new List();
//枚举所有平台下面的设备(CPU和GPU)
for (int i = 0; i < num_platforms; i++)
{
//这里后面有个参数,是Enum,这里选择GPU,表示只枚举GPU,在没有GPU的电脑上可以选CPU,也可以传ALL,会把所有设备枚举出来供选择
devs.AddRange(OpenCL.GetPlatform(i).QueryDevices(DeviceType.GPU));
}
//选中运算设备,这里选第一个其它的释放掉
var oclDevice = devs[0]; 7:配置上下文
上下文用来描述CPU与运算设备之间的主从关系.
//根据配置建立上下文
var oclContext = oclDevice.Platform.CreateContext(
new[] { (IntPtr)ContextProperties.PLATFORM, oclDevice.Platform.PlatformID, IntPtr.Zero, IntPtr.Zero },
new[] { oclDevice },
(errInfo, privateInfo, cb, userData) => { },
IntPtr.Zero
);8:创建命令队列
opencl的命令要放到队列里,然后一次性调用执行方法等待执行完毕,它可以乱序执行,也可以顺序执行.如果你想等某命令执行完再继续,可以在中间加上栅栏(下面会讲)
//创建命令队列
var oclCQ = oclContext.CreateCommandQueue(oclDevice, CommandQueueProperties.PROFILING_ENABLE);9:编译OpenCL代码,并引出两个Kernel
//定义一个字典用来存放所有核
var Kernels = new Dictionary();
#region 编译代码并导出核
var oclProgram = oclContext.CreateProgramWithSource(CLCode);
try
{
oclProgram.Build();
}
catch (OpenCLBuildException EEE)
{
Console.WriteLine(EEE.BuildLogs[0]);
Console.ReadKey(true);
throw EEE;
//return null;
}
foreach (var item in new[] { "vector_add_gpu", "vector_inc_gpu" })
{
Kernels.Add(item, oclProgram.CreateKernel(item));
}
oclProgram.Dispose();
#endregion 10:调用Kernel示例:
#region 调用vector_add_gpu核
{
var A = new int[] { 1, 2, 3, 1722 };
var B = new int[] { 456, 2, 1, 56 };
var C = new int[4];
//在显存创建缓冲区并把HOST的数据拷贝过去
var n1 = oclContext.CreateBuffer(MemFlags.READ_WRITE | MemFlags.COPY_HOST_PTR, A.Length * sizeof(int), A.ToIntPtr());
var n2 = oclContext.CreateBuffer(MemFlags.READ_WRITE | MemFlags.COPY_HOST_PTR, B.Length * sizeof(int), B.ToIntPtr());
//还有一个缓冲区用来接收回参
var n3 = oclContext.CreateBuffer(MemFlags.READ_WRITE, B.Length * sizeof(int), IntPtr.Zero);
//把参数填进Kernel里
Kernels["vector_add_gpu"].SetArg(0, n1);
Kernels["vector_add_gpu"].SetArg(1, n2);
Kernels["vector_add_gpu"].SetArg(2, n3);
//把调用请求添加到队列里,参数分别是:Kernel,数据的维度,每个维度的全局工作项ID偏移,每个维度工作项数量(我们这里有4个数据,所以设为4),每个维度的工作组长度(这里设为每4个一组)
oclCQ.EnqueueNDRangeKernel(Kernels["vector_add_gpu"], 1, new[] { 0 }, new[] { 4 }, new[] { 4 });
//设置栅栏强制要求上面的命令执行完才继续下面的命令.
oclCQ.EnqueueBarrier();
//添加一个读取数据命令到队列里,用来读取运算结果
oclCQ.EnqueueReadBuffer(n3, true, 0, C.Length * sizeof(int), C.ToIntPtr());
//开始执行
oclCQ.Finish();
n1.Dispose();
n2.Dispose();
n3.Dispose();
C = C;//在这里打断点,查看返回值
}
// */
#endregion11:释放资源
//按顺序释放之前构造的对象
oclCQ.Dispose();
oclContext.Dispose();
oclDevice.Dispose();MainProgram所有代码:
class MainProgram
{
#region OpenCL代码
private static string CLCode = @"
__kernel void vector_add_gpu(__global int* src_a, __global int* src_b, __global int* res)
{
const int idx = get_global_id(0);
res[idx] =src_a[idx] + src_b[idx];
}
__kernel void vector_inc_gpu(__global int* src_a, __global int* res)
{
const int idx = get_global_id(0);
res[idx] =src_a[idx] + 1;
}
";
#endregion
static void Main(string[] args)
{
//获取平台数量
OpenCL.GetPlatformIDs(32, new IntPtr[32], out uint num_platforms);
var devs = new List();
//枚举所有平台下面的设备(CPU和GPU)
for (int i = 0; i < num_platforms; i++)
{
//这里后面有个参数,是Enum,这里选择GPU,表示只枚举GPU,在没有GPU的电脑上可以选CPU,也可以传ALL,会把所有设备枚举出来供选择
devs.AddRange(OpenCL.GetPlatform(i).QueryDevices(DeviceType.GPU));
}
//选中运算设备,这里选第一个其它的释放掉
var oclDevice = devs[0];
for (int i = 1; i < devs.Count; i++) devs[i].Dispose();
//根据配置建立上下文
var oclContext = oclDevice.Platform.CreateContext(
new[] { (IntPtr)ContextProperties.PLATFORM, oclDevice.Platform.PlatformID, IntPtr.Zero, IntPtr.Zero },
new[] { oclDevice },
(errInfo, privateInfo, cb, userData) => { },
IntPtr.Zero
);
//创建命令队列
var oclCQ = oclContext.CreateCommandQueue(oclDevice, CommandQueueProperties.PROFILING_ENABLE);
//定义一个字典用来存放所有核
var Kernels = new Dictionary();
#region 编译代码并导出核
var oclProgram = oclContext.CreateProgramWithSource(CLCode);
try
{
oclProgram.Build();
}
catch (OpenCLBuildException EEE)
{
Console.WriteLine(EEE.BuildLogs[0]);
Console.ReadKey(true);
throw EEE;
//return null;
}
foreach (var item in new[] { "vector_add_gpu", "vector_inc_gpu" })
{
Kernels.Add(item, oclProgram.CreateKernel(item));
}
oclProgram.Dispose();
#endregion
#region 调用vector_add_gpu核
{
var A = new int[] { 1, 2, 3, 1722 };
var B = new int[] { 456, 2, 1, 56 };
var C = new int[4];
//在显存创建缓冲区并把HOST的数据拷贝过去
var n1 = oclContext.CreateBuffer(MemFlags.READ_WRITE | MemFlags.COPY_HOST_PTR, A.Length * sizeof(int), A.ToIntPtr());
var n2 = oclContext.CreateBuffer(MemFlags.READ_WRITE | MemFlags.COPY_HOST_PTR, B.Length * sizeof(int), B.ToIntPtr());
//还有一个缓冲区用来接收回参
var n3 = oclContext.CreateBuffer(MemFlags.READ_WRITE, B.Length * sizeof(int), IntPtr.Zero);
//把参数填进Kernel里
Kernels["vector_add_gpu"].SetArg(0, n1);
Kernels["vector_add_gpu"].SetArg(1, n2);
Kernels["vector_add_gpu"].SetArg(2, n3);
//把调用请求添加到队列里,参数分别是:Kernel,数据的维度,每个维度的全局工作项ID偏移,每个维度工作项数量(我们这里有4个数据,所以设为4),每个维度的工作组长度(这里设为每4个一组)
oclCQ.EnqueueNDRangeKernel(Kernels["vector_add_gpu"], 1, new[] { 0 }, new[] { 4 }, new[] { 4 });
//设置栅栏强制要求上面的命令执行完才继续下面的命令.
oclCQ.EnqueueBarrier();
//添加一个读取数据命令到队列里,用来读取运算结果
oclCQ.EnqueueReadBuffer(n3, true, 0, C.Length * sizeof(int), C.ToIntPtr());
//开始执行
oclCQ.Finish();
n1.Dispose();
n2.Dispose();
n3.Dispose();
C = C;//在这里打断点,查看返回值
}
// */
#endregion
//按顺序释放之前构造的对象
oclCQ.Dispose();
oclContext.Dispose();
oclDevice.Dispose();
}
}//End Class
运行效果:
至此,操作完成~
我在文中留了一个Kernel,你可以尝试调用看看.
相关代码git:
https://gitee.com/ASMTeam/CSharpOpenCLDemo