全面理解python面向对象编程
有待更新。。。
1、python中全局变量、局部变量、类变量、实例变量简析
因为python为动态语言,处理变量的方式与一些静态语言(比如C++)不大一样,在这里对这些变量进行小小的总结
python中全局变量与C语言中类似,也就是在的那个单页面所有函数外头定义的变量
局部变量为函数内定义的变量,函数执行完后会被回收
实例变量是类中前面有self的变量,每个实例变量都不同
类变量是所有实例共享的一个变量,所有实例占同一个内存
来看个程序就懂了!
>>> big_temp = '123456788' # 全局变量
>>> class Test:
global_temp = '123' # 类变量
def __init__(self):
self.temp = '321' # 实例变量
mytemp = '345' # 局部变量
def print_something(self,a):
print(self.temp)
print(a)
结果:
>>> test = Test()
>>> test.__dict__
>>> Out[10]: {'temp': '321'}
>>> test.global_temp = '123456'
>>> test.__dict__
Out[12]: {'global_temp': '123456', 'temp': '321'}
>>> Test.global_temp
Out[13]: '123'
>>> test.print_something(big_temp)
321
123456788
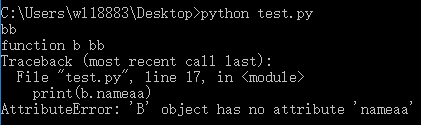
2、python 方法重写,以及子类调用父类的方法(包括构造函数)
当子类继承父类后,需要调用父类的方法和属性时,需要调用父类的初始化函数。
class A(object):
def __init__(self):
self.nameaa = 'aa'
def funca(self):
print('function a %s' % self.nameaa)
class B(A):
def __init__(self):
self.namebb = 'bb'
def funcb(self):
print('function b %s' % self.namebb)
b = B()
print(b.namebb)
b.funcb()
print(b.nameaa)
b.funca()
在子类中重写了构造函数,但新的构造函数没有初始化父类,当没有初始化父类的构造函数时,就会报错。
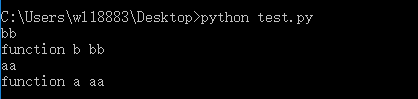
(1)调用超类的构造方法
class A(object):
def __init__(self):
self.nameaa = 'aa'
def funca(self):
print('function a %s' % self.nameaa)
class B(A):
def __init__(self):
self.namebb = 'bb'
A.__init__(self) #添加
def funcb(self):
print('function b %s' % self.namebb)
b = B()
print(b.namebb)
b.funcb()
print(b.nameaa)
b.funca()
(2)使用super函数
class A(object):
def __init__(self):
self.nameaa = 'aa'
def funca(self):
print('function a %s' % self.nameaa)
class B(A):
def __init__(self):
self.namebb = 'bb'
super(B,self).__init__()
def funcb(self):
print('function b %s' % self.namebb)
b = B()
print(b.namebb)
b.funcb()
print(b.nameaa)
b.funca()
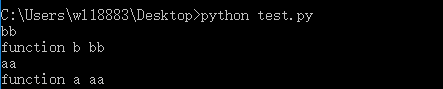
super函数返回一个super对象,解析过程自动查找所有的父类和父类的父类,当前类和对象可以作为super函数的参数使用,调用函数返回的方法是超类的方法。使用super函数如果子类继承多个父类只许一次继承,使用一次super函数即可。
以上可参考:http://www.cnblogs.com/homle/p/8724125.html
#########################插播更多的内容###############################
其实这里的第二种super方法是可以有两种风格可选的,具体见下面,可以看到更多示例:
一、 方法重写
当父类中的方法不符合我们的需求时,可以通过重写,实现我们的需求
方法重写后,默认调用子类的方法
1. 方法重写
class Foo(object):
def __init__(self):
self.name = 'Foo'
def hi(self):
print('hi,Foo')
class Foo2(Foo):
def hi(self):
print('hi,Foo2')
if __name__ == '__main__':
f = Foo2()
f.hi() #默认调用子类方法
结果:
hi,Foo2
二、调用父类的普通方法
3种方法详见代码注释
class Foo(object):
def __init__(self):
self.name = 'Foo'
def hi(self):
print('hi,Foo')
class Foo2(Foo):
def hi(self):
#Foo.hi(self) #方法1:在重写的方法内强制调用 父类名.父类方法名() 如果需要参数,则需要传参
super(Foo2,self).hi() #方法2: super(子类名,子类对象).父类方法() 如果需要参数,则需要传参
#super().hi() #方法3:仅支持python3
print('hi,Foo2')
if __name__ == '__main__':
f = Foo2()
f.hi() #调用父类方法
结果:
hi,Foo
hi,Foo2
三、调用父类的——属性
同调用父类的普通方法一样
class Foo(object):
def __init__(self):
self.name = 'Foo'
def hi(self):
print('hi,Foo')
class Foo2(Foo):
def __init__(self):
#Foo.__init__(self) #方法1:在重写的方法内强制调用 父类名.父类方法名() 如果需要参数,则需要传参
#super(Foo2,self).__init__() #方法2: super(子类名,子类对象).父类方法() 如果需要参数,则需要传参
super().__init__() #方法3: 仅python3支持
def hi(self):
print('hi,Foo2')
if __name__ == '__main__':
f = Foo2()
f.hi() #调用父类方法
结果:
hi,Foo2
Foo
总结如下:
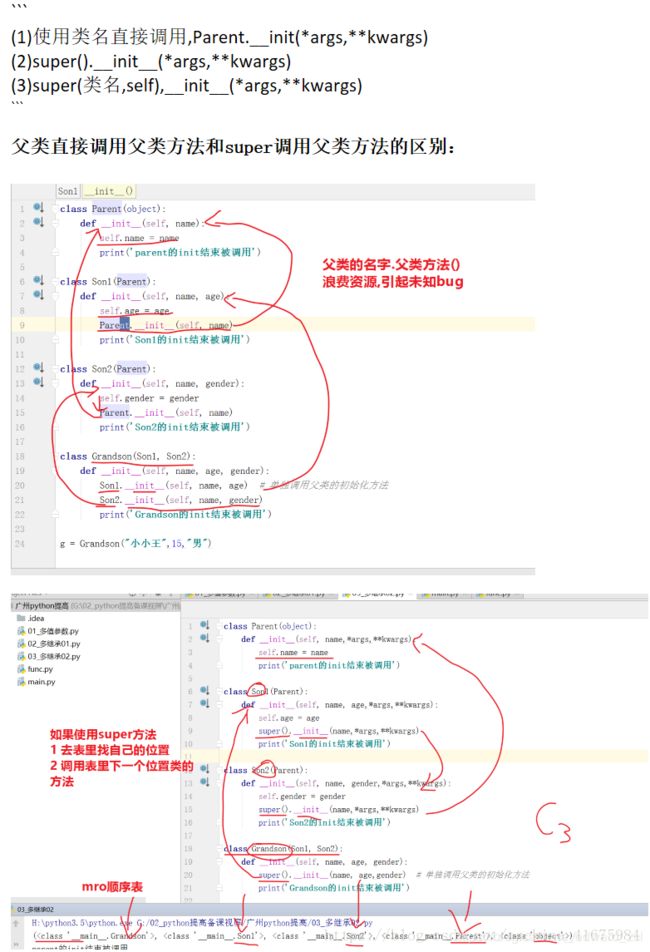
以上可参考:https://blog.csdn.net/hou_angela/article/details/82420583
###################################插播结束###################################
Python中子类调用父类的初始化方法
python中进行面向对象编程,当在子类的实例中调用父类的属性时,由于子类的__init__方法重写了父类的__init__方法,如果在子类中这些属性未经过初始化,使用时就会出错。例如以下的代码:
class A(object):
def __init__(self):
self.a = 5
def function_a(self):
print('I am from A, my value is %d' % self.a)
class B(A):
def __init__(self):
self.b = 10
def function_b(self):
print('I am from B, my value is %d' % self.b)
self.function_a() # 调用类A的方法,出错
if __name__ == '__main__':
b = B()
b.function_b()
执行结果如下:
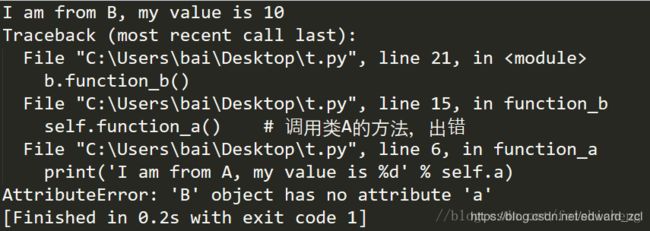
这时候就需要在类B的__init__方法中先执行类A的__init__方法,脚本才可以正确执行。Python提供了两种方法来完成这个任务。
方法一: 调用未绑定的父类__init__方法
- 在类的方法定义时,首个参数均为self。当实例化这个类时,self就被自动绑定到当前的实例。绑定也就意味着这个实例的属性,方法都可以通过‘self.***的方式进行调用。但是如果通过类名直接调用类的方法,self参数就不会被自动绑定到实例上,可以绑定到我们指定的实例上。也就是子类的实例上,在这里就是类B了。
- 所以这里所说的未绑定的父类__init__方法 就是指未绑定父类实例的父类__init__方法。
- 具体的代码如下:
class A(object):
def __init__(self):
self.a = 5
def function_a(self):
print('I am from A, my value is %d' % self.a)
class B(A):
def __init__(self):
A.__init__(self) # 此处修改了。如果类A的__init__方法需要传参,也需要传入对应的参数
self.b = 10
def function_b(self):
print('I am from B, my value is %d' % self.b)
self.function_a()
if __name__ == '__main__':
b = B()
b.function_b()
执行结果如下:
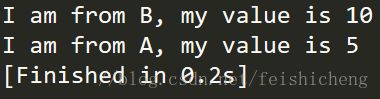
方法二:调用super函数
super函数是用于调用父类的一个方法,主要是用于解决多继承问题,避免多继承带来的一些问题,当然也可以用来解决单继承问题,调用父类的__init__方法了。
具体代码如下:
class A(object):
def __init__(self):
self.a = 5
def function_a(self):
print('I am from A, my value is %d' % self.a)
class B(A):
def __init__(self):
super(B, self).__init__() # 此处修改了
self.b = 10
def function_b(self):
print('I am from B, my value is %d' % self.b)
self.function_a()
if __name__ == '__main__':
b = B()
b.function_b()
执行结果如下:
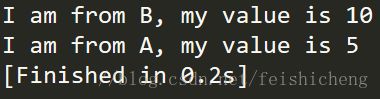
总结
两种方法各有优缺点,但都可以解决问题。
- 方法一简单直观,但面对多继承问题,只能多次调用每个父类的__init__方法
- 方法二不太直观,但可以解决多继承问题,会一次性的执行所有的父类的对应方法
所以实际使用时,按照自己的需要选择一个就行了。
以上转载自:https://blog.csdn.net/feishicheng/article/details/79596000
另外,如果没有重写子类的构造函数,是可以直接使用父类的属性和方法的。
class A(object):
def __init__(self):
self.nameaa = 'aa'
def funca(self):
print('function a %s' % self.nameaa)
class C(A):
pass
c = C()
c.funca()
print(c.nameaa)

关于以上内容,其实可以看看下面的描述理解更深:
使用父类方法一定要用super吗(写给新人)
答案,不一定。只有当子类重写了父类的方法时,如果需要用到父类的方法时,才要用super,表明这个方法时父类的方法不是子类的方法。不理解?上代码(虽然是用java写的,但是仍然具有借鉴意义):
Father类
public class Father {
public String str = "父类变量";
public String strOnly = "父类变量,子类没有同名变量";
public void printf(String str){
System.out.println(str+"这是父类的方法");
}
public void printfOnly(String str){
System.out.println("这是父类的方法,子类没有重写的方法====>"+str);
}
}
Son类
public class Son extends Father{
public String str = "子类变量";
public void printf(String str){
System.out.println(str+"这是子类的方法");
}
public void test() {
printf("什么都不使用=======>");
this.printf("使用this=======>");
super.printf("使用super=======>");
printfOnly("子类没重写,就会调用父类的方法");
System.out.println("str is ===========>"+str);
System.out.println("super.str is ===========>"+super.str);
System.out.println("子类没有同名变量,就会去找父类的变量 ===========>"+strOnly);
}
public static void main(String[] args) {
Son son = new Son();
son.test();
}
}
运行结果:
1. 什么都不使用=======>这是子类的方法
2. 使用this=======>这是子类的方法
3. 使用super=======>这是父类的方法
4. 这是父类的方法,子类没有重写的方法====>子类没重写,就会调用父类的方法
5. str is ===========>子类变量
6. super.str is ===========>父类变量
7. 子类没有同名变量,就会去找父类的变量super.str is ===========>父类变量 子类没有同名变量
子类重写printf方法,如果需要调用父类的方法就要加super,否则,默认调用子类的方法。对于变量也是一样。
以上可参考:https://blog.csdn.net/doye_chen/article/details/78887382
另外一个java示例,其实也是说明了,子类如果想继承父类的方法(不重写),就必须按照父类的格式来,否则会报错。
1.子类会默认调用父类的无参构造方法
举例来看:
public class Derived extends Base {
public Derived (String s) {
System.out.println("这是子类的构造方法");
}
public static void main(String [] args) {
new Derived ("C");
}
}
class Base {
public Base() {
System.out.println("这是父类的构造方法");
}
}
上面这段代码结果如下图所示:

这证明了 子类的构造方法默认首先调用了父类的构造方法。
2.当父类中没有无参构造函数时,子类必须调用父类有参的构造函数,因为1已经证明了 子类默认调用父类的构造方法,如果父类中没有无参的构造函数,就会出现编译错误
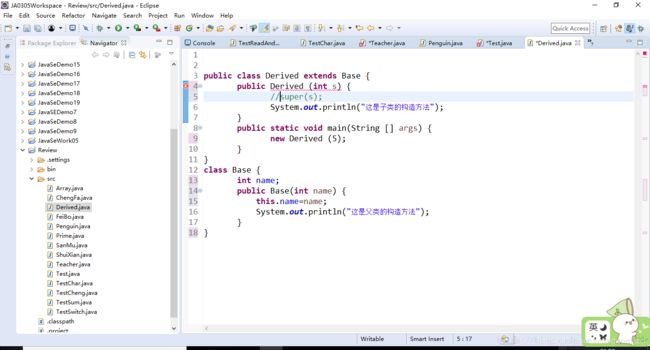
但是如果调用了父类的有参构造函数就没有错误了。
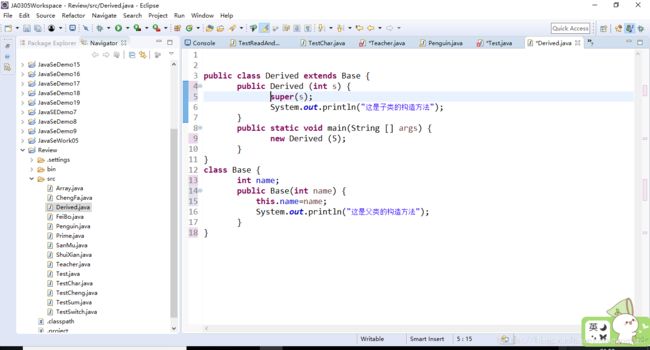
以上参考自:https://blog.csdn.net/dragon901/article/details/79749859
##################联想:突然想看看python空对象,以及c里面的对象怎么给哈哈#####################
python空对象:
示例1:
def read_cifar10(filename_queue):
# 定义一个空的类对象,类似于c语言里面的结构体定义
class Image(object):
pass
image = Image()
image.height=32
image.width=32
image.depth=3
label_bytes = 1
image_bytes = image.height*image.width*image.depth
Bytes_to_read = label_bytes+image_bytes
# 定义一个Reader,它每次能从文件中读取固定字节数
reader = tf.FixedLengthRecordReader(record_bytes=Bytes_to_read)
# 返回从filename_queue中读取的(key, value)对,key和value都是字符串类型的tensor,并且当队列中的某一个文件读完成时,该文件名会dequeue
image.key, value_str = reader.read(filename_queue)
# 解码操作可以看作读二进制文件,把字符串中的字节转换为数值向量,每一个数值占用一个字节,在[0, 255]区间内,因此out_type要取uint8类型
value = tf.decode_raw(bytes=value_str, out_type=tf.uint8)
# 从一维tensor对象中截取一个slice,类似于从一维向量中
示例2:
def read_cifar10(filename_queue):
class cifar10recode(object):
pass
result=cifar10recode()
label_bytes = 1
result.height=32
result.width=32
result.depth=3
image_bytes=result.height * result.width * result.depth
recode_bytes=label_bytes+image_bytes
reader=tf.FixedLengthReader(recode_bytes=recode_bytes)
#每次从文件中读取固定字节数
示例3:
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# Dimensions of the images in the CIFAR-10 dataset.
# See http://www.cs.toronto.edu/~kriz/cifar.html for a description of the
# input format.
label_bytes = 1 # 2 for CIFAR-100
result.height = 32
result.width = 32
result.depth = 3
image_bytes = result.height * result.width * result.depth
# Every record consists of a label followed by the image, with a
# fixed number of bytes for each.
record_bytes = label_bytes + image_bytes
# Read a record, getting filenames from the filename_queue. No
# header or footer in the CIFAR-10 format, so we leave header_bytes
# and footer_bytes at their default of 0.
# 下面的FixedLengthRecordReader与reader.read,tf.decode_raw配合起来,是以固定长度读取文件名队列中数据的一个常用方法
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(filename_queue)
# Convert from a string to a vector of uint8 that is record_bytes long.
record_bytes = tf.decode_raw(value, tf.uint8)
想起来了,c语言,matlab中的结构体以及c++中,以及其他编译型语言中的声明型数据类型,好像都是先定义数据类型,在实例化,如同,int a,struct b ...这种方式完成的。。
说起这个,该套到下一个话题了。
3、python 的类变量和对象变量
python是一种解释性的语言,任何变量可以在使用的时候才声明以及定义,也可以在程序运行的任何位置进行声明和定义新的变量。
#########################以下为某博主的原文,不太靠谱(有错),但举个了很好的例子#####################
class Man(object):
#直接定义的类的变量,属于类
#其中 gender, avg_height为基本数据类型,immutable
#lis为列表类型,为mutable的
gender = 'male'
avg_height = 1.75
lis = ['hello', 'world']
def __init__(self, name):
self.name = name #name在类的构造函数中定义,是属于对象的变量
a = Man('jason')
b = Man('tom')
#通过一个对象a访问一个变量x,变量的查找过程是这样的:
#先在对象自身的__dict__中查找是否有x,如果有则返回,否则进入对象a所属的类A的
#__dict__中进行查找
#对象a试图修改一个属于类的 immutable的变量,则python会在内存中为对象a
#新建一个gender变量,此时a就具有了属于自己的gender变量
a.gender = 'female'
#对象b试图修改一个mutable的变量,则python找到类Man的__dict__中的变量lis,
#由于lis是可以修改的,因此直接进行修改,而不会给b新生成一个变量。类Man以及类Man
#的所有对象都公用这一个lis
b.lis = ['fuck', 'world']
print a.__dict__ #属于a的变量,有 name, gender
print b.__dict__ #属于b的变量,只有name
print Man.__dict__ #属于类Man的变量,有 gender,avg_height,lis,但是不包括 name
#name是属于对象的变量
Man.t = 'test' #此时Man的变量又多了t,但是对象a和b中没有变量t。
#(这里可以看出,对象的变量和类的变量是分开的)
print a.gender #female
print b.gender #male
print a.lis #['fuck', 'world']
print b.lis #['fuck', 'world']
print(a.t)
print(b.t)
a.addr = '182.109.23.1' #给对象a定义一个变量,对象b和类Man中都不会出现(解释性语言好随性。。
需要注意,类的变量(属性)和对象的变量(属性)是“独立”的,但在通过一个对象查找一个变量的时候,会现在改对象自身的__dict__中查找,如果找不到,则进入该对象代表的类的__dict__中进行查找。
注意 mutable, immutable变量的区别!这会导致python是否会在内存中为某对象新申请内存定义该变量。
可以在程序的任何位置给类或者对象定义新的变量
##########################原文结束###################################
以上参考自:https://www.cnblogs.com/gtarcoder/p/5005897.html, 原文代码可能有错,也可能是在python2下面就是这种情况,我用python3.5实验结果与他给的不一致,详见下面我的代码。
############### 警告:不要看后面的注释,是错的 ##################
class Man(object):
#直接定义的类的变量,属于类
#其中 gender, avg_height为基本数据类型,immutable
#lis为列表类型,为mutable的
gender = 'male'
avg_height = 1.75
lis = ['hello', 'world']
def __init__(self, name):
self.name = name #name在类的构造函数中定义,是属于对象的变量
a = Man('jason')
b = Man('tom')
#通过一个对象a访问一个变量x,变量的查找过程是这样的:
#先在对象自身的__dict__中查找是否有x,如果有则返回,否则进入对象a所属的类A的
#__dict__中进行查找
#对象a试图修改一个属于类的 immutable的变量,则python会在内存中为对象a
#新建一个gender变量,此时a就具有了属于自己的gender变量
a.gender = 'female'
#对象b试图修改一个mutable的变量,则python找到类Man的__dict__中的变量lis,
#由于lis是可以修改的,因此直接进行修改,而不会给b新生成一个变量。类Man以及类Man
#的所有对象都公用这一个lis
b.lis = ['fuck', 'world']
print (a.__dict__) #属于a的变量,有 name, gender
print (b.__dict__) #属于b的变量,只有name
print (Man.__dict__) #属于类Man的变量,有 gender,avg_height,lis,但是不包括 name
#name是属于对象的变量
Man.t = 'test' #此时Man的变量又多了t,但是对象a和b中没有变量t。
#(这里可以看出,对象的变量和类的变量是分开的)
print (a.gender) #female
print (b.gender) #male
print (a.lis) #['fuck', 'world']
print (b.lis) #['fuck', 'world']
print(Man.lis)
a.addr = '182.109.23.1' #给对象a定义一个变量,对象b和类Man中都不会出现(解释性语言好随性。。)
输出如下:

我的分析如下:
1、这里关于可变对象与不可变对象的例子不够好,没有发挥出python真正意义上的命名空间,或者叫引用赋值,或者叫切片与append的实质,混淆了重新赋值与引用的区别。。
2、具体可以看微信公众号关于def(… [空列表]),以及函数里面传参时候(传值还是传引用的区别),以及微信公众号这篇文章:https://mp.weixin.qq.com/s/iBKfnlofrvJjcybX9A48mg
亦或者,可以看看下面这一部分可以加深这块的理解(类变量与对象变量),我觉得讲得很好,如下:
################################ 原文 #####################################
python中的类变量
最近我参加了一次面试,面试官要求用python实现某个api,一部分代码如下
class Service(object):
data = []
def __init__(self, other_data):
self.other_data = other_data
面试官说:“ data = []这一行是错误的。”
我:“这没问题啊,为一个成员变量设定了初始值。”
面试官:“那么这段代码什么时候被执行呢?”
我:“我也不太清楚。为了不导致混乱还是把它删了吧”
于是把代码改成了下面这样
class Service(object):
def __init__(self, other_data):
self.data = []
self.other_data = other_data
面试回来后再想想,我们都错了。问题出在对python类变量的理解。
类成员
面试官错在,上面的代码在语法上是对的。
我错在,这句并不是为一个成员变量设置初始值,而是定义一个类变量,其初始值为空list。
和我一样,很多人都知道类变量,但是并不完全理解。
区别
类变量是类的一个属性,而不是一个对象的属性。
举个例子来说明吧,class_var是一个类变量,i_var是一个实例变量
class MyClass(object):
class_var = 1
def __init__(self, i_var):
self.i_var = i_var
所有MyClass的对象都能够访问到class_var,同时class_var也能被MyClass直接访问到
foo = MyClass(2)
bar = MyClass(3)
foo.class_var, foo.i_var
## 1, 2
bar.class_var, bar.i_var
## 1, 3
MyClass.class_var
## 1
这个类成员有点像Java或者C++里面的静态成员,但是又不一样。
类和对象的命名空间
这里需要简单了解一下python的命名空间。
python中,命名空间是名字到对象映射的结合,不同命名空间中的名字是没有关联的。这种映射的实现有点类似于python中的字典
根据上下文的不同,可以通过"."或者是直接访问到命名空间中的名字。举个例子
class MyClass(object):
# 在类的命名空间内,不需要用"."访问
class_var = 1
def __init__(self, i_var):
self.i_var = i_var
## 不在类的命名空间内,需要用"."访问
MyClass.class_var
## 1
python中,类和对象都有自己的命名空间,可以通过下面的方式访问。
>>> MyClass.__dict__
dict_proxy({'__module__': 'namespace', 'class_var': 1, '__dict__': , '__weakref__': , '__doc__': None, '__init__': })
>>> a = MyClass(3)
>>> a.__dict__
{'i_var': 3}
当你名字访问一个对象的属性时,先从对象的命名空间寻找。如果找到了这个属性,就返回这个属性的值;如果没有找到的话,则从类的命名空间中寻找,找到了就返回这个属性的值,找不到则抛出异常。
举个例子
foo = MyClass(2)
## 在对象的命名空间中寻找i_var
foo.i_var
## 2
## 在对象的命名空间中找不到class_var,则从类的命名空间中寻找
foo.class_var
## 1
逻辑类似下面的代码
def instlookup(inst, name):
if inst.__dict__.has_key(name):
return inst.__dict__[name]
else:
return inst.__class__.__dict__[name]
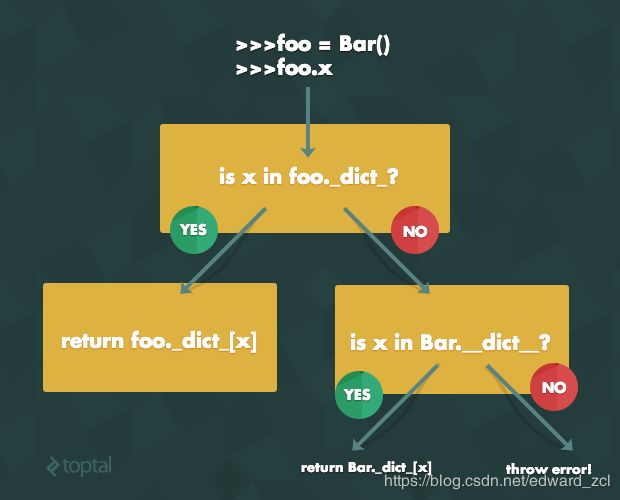
赋值
有了上面的基础,就能了解怎样给类变量赋值了。
通过类来赋值
举个例子
foo = MyClass(2)
foo.class_var
## 1
MyClass.class_var = 2
foo.class_var
## 2
在类的命名空间内,设置
setattr(MyClass, ‘class_var’, 2)
需要说明的是,MyClass.dict返回的是一个dictproxy,这是不可变的,所以不能通过MyClass.dict[‘class_var’]=2
的方式修改。之后在对象中访问class_var,得到返回值是2
通过对象来赋值
如果通过对象来给类变量赋值,将只会覆盖那个对象中的值。举个例子
foo = MyClass(2)
foo.class_var
## 1
foo.class_var = 2
foo.class_var
## 2
foo.__dict__
{'i_var': 2, 'class_var': 2}
MyClass.class_var
## 1
MyClass.__dict__
## dict_proxy({'__module__': 'namespace', 'class_var': 1, '__dict__': , '__weakref__': , '__doc__': None, '__init__': })
上面的代码在对象的命名空间内,加入了class_var属性,这时候,类的命名空间中的class_var属性并没有被改变,MyClass的其他对象的命名空间中并没有class_var这个属性,所以在其他对象中访问这个属性时,依然会返回类命名空间中的class_var,也就是1。
可变属性
假如类命名空间中的变量是可变的话,这时候会发生什么呢?
答案是,如果通过类的实例改变了变量,类变量也会发生改变,还是举个例子看看吧。
class Service(object):
data = []
def __init__(self, other_data):
self.other_data = other_data
在上面的代码中,在Service的命名空间中定义一个data,其初始值为空list,现在通过对象来改变它
s1 = Service(['a', 'b'])
s2 = Service(['c', 'd'])
s1.data.append(1)
s1.data
## [1]
s2.data
## [1]
s2.data.append(2)
s1.data
## [1, 2]
s2.data
## [1, 2]
可以看到,如果属性是可变的,在对象中改变这个属性,将会影响到类的命名空间。
可以通过赋值防止对象改变类变量。
s1 = Service(['a', 'b'])
s2 = Service(['c', 'd'])
s1.data = [1]
s2.data = [2]
s1.data
## [1]
s2.data
## [2]
在上面的例子中,我们给s1加了一个data,所以Service中的data不受影响。
但是上面的做法也有问题,因为Service的对象很容易就改变了data,应该从设计上来来避免这个问题。我个人的意见是,如果要用一个类变量来为对象的变量设定初始值,不要使用可变类型来定义这个类变量。我们可以这样
class Service(object):
data = None
def __init__(self, other_data):
self.other_data = other_data
当然,这样就要多花一点心思来处理None了。
使用
类变量有时候会很有用
存储常量
类变量可以用来存储常量,比如下面的例子
class Circle(object):
pi = 3.14159
def __init__(self, radius):
self.radius = radius
def area(self):
return Circle.pi * self.radius * self.radius
Circle.pi
## 3.14159
c = Circle(10)
c.pi
## 3.14159
c.area()
## 314.159
定义默认值
比如下面的例子
class MyClass(object):
limit = 10
def __init__(self):
self.data = []
def item(self, i):
return self.data[i]
def add(self, e):
if len(self.data) >= self.limit:
raise Exception("Too many elements")
self.data.append(e)
MyClass.limit
## 10
追踪类的所有对象
比如下面的例子
class Person(object):
all_names = []
def __init__(self, name):
self.name = name
Person.all_names.append(name)
joe = Person('Joe')
bob = Person('Bob')
print Person.all_names
## ['Joe', 'Bob']
深入底层
之前提到,类的命名空间在声明的时候就创建了。也就是说,对一个类,只会执行一次初始化,而对象每创建一次,就要初始化一次。举个例子
def called_class():
print "Class assignment"
return 2
class Bar(object):
y = called_class()
def __init__(self, x):
self.x = x
## "Class assignment"
def called_instance():
print "Instance assignment"
return 2
class Foo(object):
def __init__(self, x):
self.y = called_instance()
self.x = x
Bar(1)
Bar(2)
Foo(1)
## "Instance assignment"
Foo(2)
## "Instance assignment"
可以看到,Bar中的y被初始化了一次,而Foo中的y在每次生成新的对象时都要被初始化一次。
为了进一步的探究,我们使用Python disassembler
import dis
class Bar(object):
y = 2
def __init__(self, x):
self.x = x
class Foo(object):
def __init__(self, x):
self.y = 2
self.x = x
dis.dis(Bar)
## Disassembly of __init__:
## 7 0 LOAD_FAST 1 (x)
## 3 LOAD_FAST 0 (self)
## 6 STORE_ATTR 0 (x)
## 9 LOAD_CONST 0 (None)
## 12 RETURN_VALUE
dis.dis(Foo)
## Disassembly of __init__:
## 11 0 LOAD_CONST 1 (2)
## 3 LOAD_FAST 0 (self)
## 6 STORE_ATTR 0 (y)
## 12 9 LOAD_FAST 1 (x)
## 12 LOAD_FAST 0 (self)
## 15 STORE_ATTR 1 (x)
## 18 LOAD_CONST 0 (None)
## 21 RETURN_VALUE
可以明显看到Foo.__init__执行了两次赋值操作,而Bar.__init__只有一次赋值操作。
那么在实际中这两种方式性能有没有差别呢?
这里需要说明的是,影响代码执行速度的因素是很多的。
不过在这里的简单例子应该还是能说明一些问题,使用python中timeit模块来进行测试。
为了方便,笔者使用ipython写一些测试代码。
In [1]: class Bar(object):
...: y = 2
...: def __init__(self, x):
...: self.x = x
...: class Foo(object):
...: def __init__(self, x):
...: self.x = x
...: self.y = 2
初始化测试
In [2]: %timeit Bar(2)
The slowest run took 8.17 times longer than the fastest. This could mean that an intermediate result is being cached.
1000000 loops, best of 3: 379 ns per loop
In [3]: %timeit Foo(2)
The slowest run took 8.10 times longer than the fastest. This could mean that an intermediate result is being cached.
1000000 loops, best of 3: 471 ns per loop
可以看到Bar的初始化比Foo的初始化要快了不少。
为什么会这样呢,一个合理的解释是:Bar对象初始化的时候执行了一次赋值,而Foo对象初始化时执行了两次赋值
赋值测试
In [4]: %timeit Bar(2).y = 15
The slowest run took 27.73 times longer than the fastest. This could mean that an intermediate result is being cached.
1000000 loops, best of 3: 430 ns per loop
In [5]: %timeit Foo(2).y = 15
1000000 loops, best of 3: 511 ns per loop
因为这里实际上执行了一次初始化操作,所以需要减掉之前的初始化值
Bar assignments: 430 - 379 = 51ns
Foo assignments: 511 - 471 = 40n
看起来Foo的赋值操作比Bar的赋值操作要快一些。一个合理的解释是,在Foo的对象命名空间中能够直接找到(Foo(2).dict[y])这个属性,而在Bar的对象命名空间中找不到(Bar(2).dict[y])这个属性,然后就去Bar的类命令空间中找,这多出来的查找导致了性能的消耗。
看起来Foo的赋值操作比Bar的赋值操作要快一些。一个合理的解释是,在Foo的对象命名空间中能够直接找到(Foo(2).dict[y])这个属性,而在Bar的对象命名空间中找不到(Bar(2).dict[y])这个属性,然后就去Bar的类命令空间中找,这多出来的查找导致了性能的消耗。
虽然在实际中这样的性能差别几乎可以忽略不计,但是对于理解类中的变量和对象中的变量之间的差异还是有帮助的。
总结
在学习python的时候,了解类属性和对象属性还是很有必要的。
不过在工作中,为了保证不入坑,还是避免使用的好。
私有变量
额外说一点,python中并没有私有变量,但是通过取名可以部分实现私有变量的效果。
python文档中说,不希望被外部访问到的属性取名时,前面应该加上__,这不仅仅是个标志,而且是一种保护措施。比如下面的代码
class Bar(object):
def __init__(self):
self.__zap = 1
a = Bar()
a.__zap
## Traceback (most recent call last):
## File "", line 1, in
## AttributeError: 'Bar' object has no attribute '__zap'
## 查看命名空间
a.__dict__
{'_Bar__zap': 1}
a._Bar__zap
## 1
可以看到,前面加了__的变量,被自动加上了前缀_Bar,python就是通过这样的机制防止’私有’的变量被访问到。
作者:大蟒传奇
链接:https://www.jianshu.com/p/3aca78a84def
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
###################################### 结束原文 #####################################
以上转载自:https://blog.csdn.net/feng98ren/article/details/80068036, 基本上很好的解释了类变量与对象变量的区别。
下面是一个关于类变量与对象变量的一个较简短的总结:
Python的类变量和对象变量声明解析
Python的类和C++一样,也都是存在两种类型的变量,类变量和对象变量!前者由类拥有,被所有对象共享,后者由每个对象独有。这里我主要想讨论一下他们的声明办法。
首先说的是对象变量:
只要是声明在类的语句块中,且没有"self."前缀的变量都是类变量,且类变量是被所有对象共享的。
注意加粗部分,如果声明在类的方法的语句块中,那么就是局部变量了!比如下面这个例子:
1 #!/usr/bin/env python
2 # -* - coding: UTF-8 -* -
3 #Function: Use the class var
4
5 class Person:
6 cvar = 1
7 def sayHi(self):
8 fvar = 1
9
10 print Person.cvar
11 print Person.fvar
那个cvar就是属于Python类的变量,而那个fvar就是方法sayHi()中的局部变量,第11条语句那里就会报错!
接下来我们再来讨论一下对象变量的声明方法:
在类的方法的语句块中声明的以“self.”开头的变量都是对象变量,由对象独有!
比如下面这个例子:
1 #!/usr/bin/env python
2 # -* - coding: UTF-8 -* -
3 #Function: Use the object var
4
5 class Person:
6 def haveName(self):
7 self.name = 'Michael'
8 def sayName(self):
9 print self.name
10
11 def main():
12 p = Person()
13
14 p.haveName()
15 p.sayName()
16
17 main()
这里在haveName()方法中声明了一个对象变量,然后再在sayName()方法中调用。然后主程序中就会输出了!
不过建议将对象变量声明在__init__()方法中,因为对象一被创建的时候即会调用这个方法,否则的话,比如上面那个例子,如果我先调用sayName()的话,那么就会出错,说对象实例还没有name这个属性!
最后还想说的一点的就是,Python中没有private public这些关键字来标明类的变量或者方法的访问权限,但是可以通过在变量或者方法的前面加上"__"来表明这个成员是被类私有的,不能在外部调用,比如下面这个例子:
1 #!/usr/bin/env python
2 # -* - coding: UTF-8 -* -
3 #Function: Use the private var and func
4
5 class Person:
6 __count = 0 #这个变量是私有数据成员,只能被类的方法访问,是属于类的
7 def get(self):
8 return Person.__count
9 def __pri(self):
10 print 'Yes'
11
12 p = Person()
13 print p.get()
14
15 p.__pri()
16 print p.__count
比如这里的类变量__count就是类私有的,只能被类的函数成员调用(13行),而在类外面调用(16行)就是错误的!还有那个函数成员__pri()也是私有的,在类外面直接调用(15行),也是错误的!
以上转载自:https://www.cnblogs.com/bwangel23/p/4330268.html
总而言之,私有的类变量与对象变量都不能在外面直接访问,父类的私有属性, 连子类也无法继承,子类对象也不能访问到这个数据。但是其实Python对这个封装得不那么严格,实际上还是可以通过一定的手段获取到的,下面会提到。另外,类变量(甚至是类的私有变量)在类的各种方法中,以及对象方法中也可以被访问,甚至改变。
参考下面三段代码:
示例1:
#!/usr/bin/env python
# -* - coding: UTF-8 -* -
#Function: Use the private var and func
class Person:
__count = 0 #这个变量是私有数据成员,只能被类的方法访问,是属于类的
def get(self):
print(self.__count)
print(id(self.__count))
Person.__count+=1
print(id(self.__count))
print(self.__count)
return self.__count
def __pri(self):
print ('Yes')
p = Person()
print (p.get())
print()
q=Person()
print (q.get())
p.__pri()
print (p.__count)
示例2:
class Person:
__count = 0 #这个变量是私有数据成员,只能被类的方法访问,是属于类的
def get(self):
print(self.__count)
print(id(self.__count))
self.__count+=1
print(id(self.__count))
print(self.__count)
return self.__count
def __pri(self):
print ('Yes')
p = Person()
print (p.get())
print()
q=Person()
print (q.get())
p.__pri()
print (p.__count)
示例3:
class Person:
__count = 0 #这个变量是私有数据成员,只能被类的方法访问,是属于类的
@classmethod
def get(cls):
print(cls.__count)
print(id(cls.__count))
cls.__count+=1
print(id(cls.__count))
print(cls.__count)
return cls.__count
def __pri(self):
print ('Yes')
p = Person()
print (p.get())
print()
q=Person()
print (q.get())
p.__pri()
print (p.__count)
##注:将私有变量__count变为公有类变量,结果仍然一致。
4、类保护变量,私有变量,全局变量,局部变量
接下来,讨论另外一个比较重要的话题,私有变量,当它与类的定义结合起来时,内容会相当丰富。。
默认情况下,Python中的成员函数和成员变量都是公开的(public),在python中没有类似public,private等关键词来修饰成员函数和成员变量。
在python中定义私有变量只需要在变量名或函数名前加上 ”__“两个下划线,那么这个函数或变量就是私有的了。
在内部,python使用一种 name mangling 技术,将 __membername替换成 _classname__membername,也就是说,类的内部定义中,
所有以双下划线开始的名字都被"翻译"成前面加上单下划线和类名的形式。
例如:为了保证不能在class之外访问私有变量,Python会在类的内部自动的把我们定义的__spam私有变量的名字替换成为
_classname__spam(注意,classname前面是一个下划线,spam前是两个下划线),因此,用户在外部访问__spam的时候就会
提示找不到相应的变量。 python中的私有变量和私有方法仍然是可以访问的;访问方法如下:
私有变量:实例._类名__变量名
私有方法:实例._类名__方法名()
其实,Python并没有真正的私有化支持,但可用下划线得到伪私有。 尽量避免定义以下划线开头的变量!
(1)_xxx "单下划线 " 开始的成员变量叫做保护变量,意思是只有类实例和子类实例能访问到这些变量,
需通过类提供的接口进行访问;不能用’from module import '导入
(2)__xxx 类中的私有变量/方法名 (Python的函数也是对象,所以成员方法称为成员变量也行得通。),
" 双下划线 " 开始的是私有成员,意思是只有类对象自己能访问*,连子类对象也不能访问到这个数据。
(3)__xxx __ 系统定义名字,前后均有一个“双下划线” 代表python里特殊方法专用的标识,如 __ init __()代表类的构造函数。
下面我们看几个例子:
【1】
class A(object):
def __init__(self):
self.__data=[] #翻译成 self._A__data=[]
def add(self,item):
self.__data.append(item) #翻译成 self._A__data.append(item)
def printData(self):
print self.__data #翻译成 self._A__data
a=A()
a.add('hello')
a.add('python')
a.printData()
#print a.__data #外界不能访问私有变量 AttributeError: 'A' object has no attribute '__data'
print a._A__data #通过这种方式,在外面也能够访问“私有”变量;这一点在调试中是比较有用的!
运行结果是:
[‘hello’, ‘python’]
[‘hello’, ‘python’]
【2】
获取实例的所有属性 print a.dict
获取实例的所有属性和方法 print dir(a)
class A():
def __init__(self):
self.__name='python' #私有变量,翻译成 self._A__name='python'
def __say(self): #私有方法,翻译成 def _A__say(self)
print self.__name #翻译成 self._A__name
a=A()
#print a.__name #访问私有属性,报错!AttributeError: A instance has no attribute '__name'
print a.__dict__ #查询出实例a的属性的集合
print a._A__name #这样,就可以访问私有变量了
#a.__say()#调用私有方法,报错。AttributeError: A instance has no attribute '__say'
print dir(a)#获取实例的所有属性和方法
a._A__say() #这样,就可以调用私有方法了
运行结果:
{’_A__name’: ‘python’}
python
[’_A__name’, ‘_A__say’, ‘doc’, ‘init’, ‘module’]
python
从上面看来,python还是非常的灵活,它的oop没有做到真正的不能访问,只是一种约定让大家去遵守,
比如大家都用self来代表类里的当前对象,其实,我们也可以用其它的,只是大家习惯了用self 。
【3】小漏洞:派生类和基类取相同的名字就可以使用基类的私有变量
class A():
def __init__(self):
self.__name='python' #翻译成self._A__name='python'
class B(A):
def func(self):
print self.__name #翻译成print self._B__name
instance=B()
#instance.func()#报错:AttributeError: B instance has no attribute '_B__name'
print instance.__dict__
print instance._A__name
运行结果:
{’_A__name’: ‘python’}
python
class A():
def __init__(self):
self.__name='python' #翻译成self._A__name='python'
class A(A): #派生类和基类取相同的名字就可以使用基类的私有变量。
def func(self):
print self.__name #翻译成print self._A__name
instance=A()
instance.func()
运行结果:
python
以上转载自:https://blog.csdn.net/sxingming/article/details/52875125, 对私有变量做了一个较为充分的解析。
此外,还可以参考这两篇博文,进入更深入的理解:
https://www.cnblogs.com/lijunjiang2015/p/7802410.html
https://blog.csdn.net/boyun58/article/details/77131261
################################## NO.1 ##################################
python 类的私有变量和私有方法
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2017/11/08 8:46
# @Author : lijunjiang
# @File : class3.py
"""
类的私有变量和私有方法
在Python中可以通过在属性变量名前加上双下划线定义属性为私有属性
特殊变量命名
1、 _xx 以单下划线开头的表示的是protected类型的变量。即保护类型只能允许其本身与子类进行访问。若内部变量标示,如: 当使用“from M import”时,不会将以一个下划线开头的对象引入 。
2、 __xx 双下划线的表示的是私有类型的变量。只能允许这个类本身进行访问了,连子类也不可以用于命名一个类属性(类变量),调用时名字被改变(在类FooBar内部,__boo变成_FooBar__boo,如self._FooBar__boo)
3、 __xx__定义的是特列方法。用户控制的命名空间内的变量或是属性,如init , __import__或是file 。只有当文档有说明时使用,不要自己定义这类变量。 (就是说这些是python内部定义的变量名)
在这里强调说一下私有变量,python默认的成员函数和成员变量都是公开的,没有像其他类似语言的public,private等关键字修饰.但是可以在变量前面加上两个下划线"_",这样的话函数或变量就变成私有的.这是python的私有变量轧压(这个翻译好拗口),英文是(private name mangling.) **情况就是当变量被标记为私有后,在变量的前端插入类名,再类名前添加一个下划线"_",即形成了_ClassName__变量名.**
Python内置类属性
__dict__ : 类的属性(包含一个字典,由类的数据属性组成)
__doc__ :类的文档字符串
__module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
__bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
"""
class pub():
_name = 'protected类型的变量'
__info = '私有类型的变量'
def _func(self):
print("这是一个protected类型的方法")
def __func2(self):
print('这是一个私有类型的方法')
def get(self):
return(self.__info)
a = pub()
print(a._name)
a._func()
# print(a.info)
# 执行结果:
# protected类型的变量
# 这是一个protected类型的方法
# protected类型的变量和方法 在类的实例中可以获取和调用
# # print(a.__info)
# # a.__func2()
# 执行结果:
# File "D:/Python/class/class3.py", line 46, in
# print(a.__info)
# # AttributeError: pub instance has no attribute '__info'
# a.__func2()
# AttributeError: pub instance has no attribute '__func2'
# 私有类型的变量和方法 在类的实例中获取和调用不到
# 获取私有类型的变量
print(a.get())
# 执行结果:私有类型的变量
# 如果想要在实例中获取到类的私有类形变量可以通过在类中声明普通方法,返回私有类形变量的方式获取
print(dir(a))
# 执行结果:['__doc__', '__module__', '_func', '_name', '_pub__func2', '_pub__info', 'get']
print(a.__dict__)
# 执行结果:{}
print(a.__doc__)
# 执行结果: None
print(a.__module__)
# 执行结果:__main__
print(a.__bases__)
# 执行结果:
# print(a.__bases__)
# AttributeError: pub instance has no attribute '__bases__'
################################### END ##################################
################################# NO.2 ###################################
PYTHON中对象命名的单下划线与双下划线的区别(私有和保护)
Python中用单双下划线作为变量前缀和后缀指定特殊变量的意义:
_name 不能用’from moduleimport *'导入
__ name __ 系统定义名字__xxx 类中的私有变量名
因为下划线对解释器有特殊的意义,而且是内建标识符所使用的符号
变量名_xxx被看作是“私有 的”,在模块或类外不可以使用。当变量是私有的时候,用_xxx 来表示变量是很好的习惯。因为变量名xxx对python 来说有特殊含义,对于普通的变量应当避免这种命名风格。
“单下划线开头” 的成员变量叫做保护变量,意思是只有类对象和子类对象才能访问到这些变量。
“双下划线开头” 的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
以单下划线开头(_func)的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用“from name import *”而导入;以双下划线开头的(func)代表类的私有成员;以双下划线开头和结尾的(__foo)代表python里特殊方法专用的标识,如 init(),del( ), new这些代表类的构造函数
1、_name 不能用于’from module import *’ 以单下划线开头的表示的是protected类型的变量。即保护类型只能允许其本身与子类进行访问。
2、__name 双下划线的表示的是私有类型的变量。只能是允许这个类本身进行访问了。连也是子类也不可以的。
3、__ name __ 定义的是特列方法。像init、del之类。
#################################### END #################################
那么接下来,如何,修改私有属性的值,这一部分其实上面已经介绍过一些了,这里再重复解释一下。
python中私有属性和私有方法,修改私有属性的值
- 如果一个属性是以两个下划线开始 就标识这个这个属性是一个私有属性
self.__money = 1000000
- 如果一个方法是以两个下划线开始 也代表已经私有
- 子类继承了父类 如果父类的属性私有 将不会被子类继承
- 私有属性和私有方法可以在类的里面使用
- 自定义类中 如果一个属性进行了私有 在类的外面不能调用
修改私有属性的值
- 如果需要修改一个对象的属性值,通常有2种方法
对象名.属性名 = 数据 ----> 直接修改
对象名.方法名() ----> 间接修改
- 私有属性不能直接访问,所以无法通过第一种方式修改,一般的通过第二种方式修改私有属性的值:定义一个可以调用的公有方法,在这个公有方法内访问修改。
class Person(object):
def __init__(self):
self.name = "小明"
self.__age = 20
#获取私有属性的值
def get_age(self):
return self.__age
#设置私有属性的值
def set_age(self, new_age):
self.__age = new_age
#定义一个对象
p = Person()
#强行获取私有属性
#崇尚一切靠自觉
print(p._Person__age)
print(p.name)
#想在类的外面获取对象的属性
ret = p.get_age()
print(ret)
#想在类的外面修改对象私有属性的值
p.set_age(30)
print(p.get_age())
以上转载自:https://blog.csdn.net/S201314yh/article/details/79874085
Python中默认的成员函数,成员变量都是公开的(public),而且python中没有类似public,private等关键词来修饰成员函数,成员变量。
总而言之,在python中定义私有变量只需要在变量名或函数名前加上 ”__“两个下划线,那么这个函数或变量就会为私有的了。
在内部,python使用一种 name mangling 技术,将 __membername替换成 _classname__membername,所以你在外部使用原来的私有成员的名字时,会提示找不到。
命名混淆意在给出一个在类中定义“私有”实例变量和方法的简单途径, 避免派生类的实例变量定义产生问题,或者与外界代码中的变量搞混。 要注意的是混淆规则主要目的在于避免意外错误, 被认作为私有的变量仍然有可能被访问或修改。 在特定的场合它也是有用的,比如调试的时候, 这也是一直没有堵上这个漏洞的原因之一 (小漏洞:派生类和基类取相同的名字就可以使用基类的私有变量。)
最后,介绍一下python中self和cls的区别。
python中的cls到底指的是什么,与self有什么区别?
作者:秦风
链接:https://www.zhihu.com/question/49660420/answer/335991541
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。
而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。
这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。
class A(object):
a = 'a'
@staticmethod
def foo1(name):
print 'hello', name
def foo2(self, name):
print 'hello', name
@classmethod
def foo3(cls, name):
print 'hello', name
首先定义一个类A,类A中有三个函数,foo1为静态函数,用@staticmethod装饰器装饰,这种方法与类有某种关系但不需要使用到实例或者类来参与。如下两种方法都可以正常输出,也就是说既可以作为类的方法使用,也可以作为类的实例的方法使用。
a = A()
a.foo1('mamq') # 输出: hello mamq
A.foo1('mamq')# 输出: hello mamq
foo2为正常的函数,是类的实例的函数,只能通过a调用。
a.foo2('mamq') # 输出: hello mamq
A.foo2('mamq') # 报错: unbound method foo2() must be called with A instance as first argument (got str instance instead)
foo3为类函数,cls作为第一个参数用来表示类本身. 在类方法中用到,类方法是只与类本身有关而与实例无关的方法。如下两种方法都可以正常输出。
a.foo3('mamq') # 输出: hello mamq
A.foo3('mamq') # 输出: hello mamq
但是通过例子发现staticmethod与classmethod的使用方法和输出结果相同,再看看这两种方法的区别。
既然@staticmethod和@classmethod都可以直接类名.方法名()来调用,那他们有什么区别呢 从它们的使用上来看,
@staticmethod不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
@classmethod也不需要self参数,但第一个参数需要是表示自身类的cls参数。
如果在@staticmethod中要调用到这个类的一些属性方法,只能直接类名.属性名或类名.方法名。
而@classmethod因为持有cls参数,可以来调用类的属性,类的方法,实例化对象等,避免硬编码。
也就是说在classmethod中可以调用类中定义的其他方法、类的属性,但staticmethod只能通过A.a调用类的属性,但无法通过在该函数内部调用A.foo2()。修改上面的代码加以说明:
class A(object):
bar = 1
def foo(self):
print ('foo')
@staticmethod
def static_foo():
print ('static_foo')
print (A.bar)
@classmethod
def class_foo(cls):
print ('class_foo')
print (cls.bar)
cls().foo()
A.static_foo()
A.class_foo()
一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。而使用@staticmethod或@classmethod,就可以不需要实例化,直接类名.方法名()来调用。这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。
在看__new__和__init__的区别的时候, 发现一个参数是cls一个参数是self, 顺便查了他们的区别
cls 和 self其实只是一种命名习惯习惯, 是在PEP8中定义的.
cls作为第一个参数用来表示类本身. 在类方法中用到
类方法是只与类本身有关而与实例无关的方法, 比如:
class A(object):
a = 'a'
@classmethod
def repeat_a(cls, times=1):
return cls.a * times
foo = A()
print(foo.repeat_a(2))
输出:
aa
讲道理的话类方法可以在类的外面实现, 但是这样扩散了类代码的关系到类定义的外面, 不利于后期代码的维护.
self作为第一个参数用来表示类的实例, 在类的一般方法中用到. 类的一般方法与类的实例有关.
类中还有一种静态方法, 用@staticmethod装饰器装饰, 这种方法与类有某种关系但不需要使用到实例或者类来参与
比如:
DEBUG = True
class A(object):
a = 'a'
@staticmethod
def is_debug():
return DEBUG
def show_error_messages(self):
if self.is_debug():
print('error_messages')
else:
pass
foo = A()
foo.show_error_messages()
参考资料:
飘逸的python - @staticmethod和@classmethod的作用与区别
python中self,cls - SA高处不胜寒 - 博客园
python cls 和 self
总结如下:
1、self表示一个具体的实例本身。
如果用了staticmethod,那么就可以无视这个self,将这个方法当成一个普通的函数使用。
2、cls表示这个类本身
>>> class A(object):
def foo1(self):
print "Hello",self
@staticmethod
def foo2():
print "hello"
@classmethod
def foo3(cls):
print "hello",cls
>>> a = A()
>>> a.foo1() #最常见的调用方式,但与下面的方式相同
Hello <__main__.A object at 0x9f6abec>
>>> A.foo1(a) #这里传入实例a,相当于普通方法的self
Hello <__main__.A object at 0x9f6abec>
>>> A.foo2() #这里,由于静态方法没有参数,故可以不传东西
hello
>>> A.foo3() #这里,由于是类方法,因此,它的第一个参数为类本身。
hello
>>> A #可以看到,直接输入A,与上面那种调用返回同样的信息。
3、whats more,类先调用__new__方法,返回该类的实例对象,这个实例对象就是__init__方法的第一个参数self,即self是__new__的返回值。
可以参考这个示例,辅助理解:
python中的类变量和对象变量,以及传值传引用的探究
一、类变量
可变变量作为类变量:对于列表、字典、自定义类这些可变变量,如果将其作为类变量,则是传引用。即所有对象的类变量公用一个内存地址。
不可变变量作为类变量:对于INT,STRING这种不可变变量,如果将其作为类变量,则是传值。即所有对象的类变量有各自的内存地址。
二、对象变量
不管是可变变量还是不可变变量,只要是放在构造函数中,则都是传值。即各个对象拥有自己的对象属性。
例子请参考:
一个类的三个对象实例的属性被同时修改
有段代码如下:
#本文环境:Python 2.7
class task_queue:
queue=[]
def append(self,obj):
self.queue.append(obj)
def print_queue(self):
print self.queue
if __name__=="__main__":
a=task_queue()
b=task_queue()
c=task_queue()
a.append('tc_1')
a.print_queue()
b.print_queue()
c.print_queue()
我们期望在队列 a 中插入 tc_1,结果 b 和 c 也被同时操作了,这并不是我们所期望的
['tc_1']
['tc_1']
['tc_1']
static
这种行为很像静态变量的行为,可是 Python 中并没有 static 关键字,这是怎么回事?
Java 和 C++ 中的 static 关键字有多种用法
其中,如果 static 去修饰一个类的属性,那么该属性就不是被各个对象所持有,而是一片公共的区域
利用这种方法,我们可以在构造函数中对一个静态变量 ++ 以查看它被实例化了多少次
class a(){
static private count
public a(){
this.count++
}
public static instance_count(){
System.out.println(this.count)
}
}
回到 Python
Python 中并没有访问限定符 static,这种机制在 Python 中被称为 类的属性 和 对象的属性
第一段代码中的 queue 在类的声明中被初始化为空,这是 类的属性
a.append() 之后,queue 中添加了 ‘tc_1’,而 b 和 c 获取的 queue 依然是公共的 类的属性
如何让这个属性变为对象自己的呢?改动如下:
class task_queue:
def __init__(self):
self.queue=[]
def append(self,obj):
self.queue.append(obj)
def print_queue(self):
print self.queue
在构造对象实例时构造对象自己的属性 queue
['tc_1']
[]
[]
另一个例子
class a():
num = 0
if __name__=="__main__":
obj1 = a()
obj2 = a()
print obj1.num, obj2.num, a.num
obj1.num += 1
print obj1.num, obj2.num, a.num
a.num += 2
print obj1.num, obj2.num, a.num
实例化 obj1 和 obj2 的时候,他们都没有对属性 num 进行操作,所以打印出来的都是类 a 的属性 num,也就是 0
后来 obj1 对自己的 num 进行 +1 之后,与类的属性脱离了关系,属性 num 就变成对象 obj1 自己的属性,而 obj2 尝试打印属性 num 的时候还是从类的属性中去读取
第三段中,类的属性 +2 后,obj1.num 没有受到影响,而 obj2 尝试读取 num 属性时,依旧从类中去拿,所以它拿到的 num 是2
0 0 0
1 0 0
1 2 2
以上参考自:https://www.cnblogs.com/turtle-fly/p/3280610.html
最后分享一个有趣的示例:
Python 实例方法、类方法、静态方法的区别与作用
Python中至少有三种比较常见的方法类型,即实例方法,类方法、静态方法。它们是如何定义的呢?如何调用的呢?它们又有何区别和作用呢?且看下文。
首先,这三种方法都定义在类中。下面我先简单说一下怎么定义和调用的。(PS:实例对象的权限最大。)
实例方法
定义:第一个参数必须是实例对象,该参数名一般约定为“self”,通过它来传递实例的属性和方法(也可以传类的属性和方法);
调用:只能由实例对象调用。
类方法
定义:使用装饰器**@classmethod**。第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:实例对象和类对象都可以调用。
静态方法
定义:使用装饰器**@staticmethod**。参数随意,没有“self”和“cls”参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:实例对象和类对象都可以调用。
实例方法
简而言之,实例方法就是类的实例能够使用的方法。这里不做过多解释。
类方法
使用装饰器**@classmethod**。
原则上,类方法是将类本身作为对象进行操作的方法。假设有个方法,且这个方法在逻辑上采用类本身作为对象来调用更合理,那么这个方法就可以定义为类方法。另外,如果需要继承,也可以定义为类方法。
如下场景:
假设我有一个学生类和一个班级类,想要实现的功能为:
执行班级人数增加的操作、获得班级的总人数;
学生类继承自班级类,每实例化一个学生,班级人数都能增加;
最后,我想定义一些学生,获得班级中的总人数。
思考:这个问题用类方法做比较合适,为什么?因为我实例化的是学生,但是如果我从学生这一个实例中获得班级总人数,在逻辑上显然是不合理的。同时,如果想要获得班级总人数,如果生成一个班级的实例也是没有必要的。
class ClassTest(object):
__num = 0
@classmethod
def addNum(cls):
cls.__num += 1
@classmethod
def getNum(cls):
return cls.__num
# 这里我用到魔术函数__new__,主要是为了在创建实例的时候调用人数累加的函数。
# 另外,这也说明,python的子类实例化的时候,父类也会初始化,先__new__,再默认的构造__init__。
def __new__(self):
ClassTest.addNum()
return super(ClassTest, self).__new__(self)
class Student(ClassTest):
def __init__(self):
self.name = ''
a = Student()
b = Student()
print(ClassTest.getNum())
静态方法
使用装饰器**@staticmethod**。
静态方法是类中的函数,不需要实例。静态方法主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。可以理解为,静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护。
譬如,我想定义一个关于时间操作的类,其中有一个获取当前时间的函数。
import time
class TimeTest(object):
def __init__(self, hour, minute, second):
self.hour = hour
self.minute = minute
self.second = second
@staticmethod
def showTime():
return time.strftime("%H:%M:%S", time.localtime())
print(TimeTest.showTime())
t = TimeTest(2, 10, 10)
nowTime = t.showTime()
print(nowTime)
如上,使用了静态方法(函数),然而方法体中并没使用(也不能使用)类或实例的属性(或方法)。若要获得当前时间的字符串时,并不一定需要实例化对象,此时对于静态方法而言,所在类更像是一种名称空间。
其实,我们也可以在类外面写一个同样的函数来做这些事,但是这样做就打乱了逻辑关系,也会导致以后代码维护困难。
以上就是我对Python的实例方法,类方法和静态方法之间的区别和作用的简要阐述。转载自:https://www.cnblogs.com/wcwnina/p/8644892.html
5、装饰器,反射机制,类属性,生成器,迭代器,可迭代对象
Python 反射机制之hasattr()、getattr()、setattr() 、delattr()函数
6、可变对象与不可变对象,python的传值,传引用,命名空间,一切皆对象
7、魔法方法,特殊方法,python运算符重载,封装,抽象类,析构函数,虚函数,新式类经典类
8、元类,python设计思想,__ new __,type类