基于物品的协同过滤算法:(item-based collaborative filtering)
ItemCF的一个优势就是可以提供推荐解释,即利用用户历史上喜欢的 物品为现在的推荐结果进行解释。
ItemCF算法并 不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的 相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品 B。
基于物品的协同过滤算法主要分为两步。
(1) 计算物品之间的相似度。
(2) 根据物品的相似度和用户的历史行为(即用户之前没有看过的视频)给用户生成推荐列表。
在协同过滤中两个物品产生相似度是因为它们共同被很多用户同时喜欢,,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。(也即物品之间的相似度可以由每个用户的兴趣列表来计算)。
所用到的代码中的k表示推荐最相似的K个列表。
隐语义模型
其实该算法最早在文本挖掘领域被提出,用于找到文本的隐含语义。
这里将对隐含语义模型在Top-N推荐中的应用进行详细介绍,并通过实际的数据评测该模型。
隐语义模型是最近几年推荐系统领域最为热门的研究话题,它的核心思想是通过隐含特征 (latent factor)联系用户兴趣和物品。
首先通过一个例子来理解下这个模型:
用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书, 而用户B的兴趣比较集中在数学和机器学习方面。
那么如何给A和B推荐图书呢?
对于UserCF,首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他 们推荐那些用户喜欢的其他书。
对于ItemCF,需要给他们推荐和他们已经看的书相似的书,比如作者B看了很多关于数据 挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
还有一种方法,可以对书和用户的兴趣进行分类。对于某个用户,首先得到他的兴趣分类, 然后从分类中挑选他可能喜欢的物品。
总结一下,这个基于兴趣分类的方法大概需要解决3个问题。
如何给物品进行分类?
如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
对于一个给定的类,选择哪些属于这个类的物品推荐给用户,以及如何确定这些物品在 一个类中的权重?
对于第一个问题的简单解决方案是找编辑给物品分类。以图书为例,每本书出版时,编辑都会给书一个分类。为了给图书分类,出版界普遍遵循中国图书分类法①。但是,即使有很系统的 分类体系,编辑给出的分类仍然具有以下缺点。
编辑的意见不能代表各种用户的意见。比如,对于《具体数学》应该属于什么分类,有 人认为应该属于数学,有些人认为应该属于计算机。从内容看,这本书是关于数学的, 但从用户看,这本书的读者大部分是做计算机出身的。编辑的分类大部分是从书的内容出 发,而不是从书的读者群出发。
编辑很难控制分类的粒度。我们知道分类是有不同粒度的,《数据挖掘导论》在粗粒度的 分类中可能属于计算机技术,但在细粒度的分类中可能属于数据挖掘。对于不同的用户, 我们可能需要不同的粒度。比如对于一位初学者,我们粗粒度地给他做推荐就可以了, 而对于一名资深研究人员,我们就需要深入到他的很细分的领域给他做个性化推荐。
编辑很难给一个物品多个分类。有的书不仅属于一个类,而是可能属于很多的类。
编辑很难给出多维度的分类。我们知道,分类是可以有很多维度的,比如按照作者分类、 按照译者分类、按照出版社分类。比如不同的用户看《具体数学》原因可能不同,有些人是因为它是数学方面的书所以才看的,而有些人是因为它是大师Knuth的著作所以才去 看,因此在不同人的眼中这本书属于不同的分类。
编辑很难决定一个物品在某一个分类中的权重。比如编辑可以很容易地决定《数据挖掘 导论》属于数据挖掘类图书,但这本书在这类书中的定位是什么样的,编辑就很难给出 一个准确的数字来表示。
为了解决上面的问题,研究人员提出:为什么我们不从数据出发,自动地找到那些类,然后 进行个性化推荐?于是,隐含语义分析技术(latent variable analysis)出现了。隐含语义分析技术 因为采取基于用户行为统计的自动聚类,较好地解决了上面提出的5个问题。
编辑的意见不能代表各种用户的意见,但隐含语义分析技术的分类来自对用户行为的统 计,代表了用户对物品分类的看法。隐含语义分析技术和ItemCF在物品分类方面的思想 类似,如果两个物品被很多用户同时喜欢,那么这两个物品就很有可能属于同一个类。
编辑很难给一个物品多个分类,但隐含语义分析技术会计算出物品属于每个类的权重, 因此每个物品都不是硬性地被分到某一个类中。
编辑很难给出多维度的分类,但隐含语义分析技术给出的每个分类都不是同一个维度的, 它是基于用户的共同兴趣计算出来的,如果用户的共同兴趣是某一个维度,那么LFM给 出的类也是相同的维度。
编辑很难决定一个物品在某一个分类中的权重,但隐含语义分析技术可以通过统计用户 行为决定物品在每个类中的权重,如果喜欢某个类的用户都会喜欢某个物品,那么这个 物品在这个类中的权重就可能比较高。
LFM通过如下公式计算用户u对物品i的兴趣:

Preference( u, i)= Pu,k*Qi,k从f=1到F求和,这里Pu,k和Qk,i是模型的参数,其中pu,k度量了用户u的兴趣和第k第k个隐类的关系,而Qk,i度量了第k个隐类和物品i之间的关系。那么,下面的问题就是如何计算这两个参数。
使用LFM(Latent factor model)隐语义模型进行Top-N推荐
对最优化理论或者机器学习有所了解的读者,可能对如何计算这两个参数都比较清楚。这两 个参数是从数据集中计算出来的。要计算这两个参数,需要一个训练集,对于每个用户u,训练 集里都包含了用户u喜欢的物品和不感兴趣的物品,通过学习这个数据集,就可以获得上面的模 型参数。
推荐系统的用户行为分为显性反馈和隐性反馈。LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。不过本章主要讨论的是隐性反馈数据集,这种数据集的 特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。
那么,在隐性反馈数据集上应用LFM解决TopN推荐的第一个关键问题就是如何给每个用户 生成负样本。
对于这个问题,Rong Pan在文章①中进行了深入探讨。他对比了如下几种方法。
对于一个用户,用他所有没有过行为的物品作为负样本。
对于一个用户,从他没有过行为的物品中均匀采样出一些物品作为负样本。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,保证 每个用户的正负样本数目相当。
对于一个用户,从他没有过行为的物品中采样出一些物品作为负样本,但采样时,偏重 采样不热门的物品。
对于第一种方法,它的明显缺点是负样本太多,正负样本数目相差悬殊,因而计算复杂度很 高,最终结果的精度也很差。对于另外3种方法,Rong Pan在文章中表示第三种好于第二种,而 第二种好于第四种。
后来,通过2011年的KDD Cup的Yahoo! Music推荐系统比赛,我们发现对负样本采样时应该 遵循以下原则。
对每个用户,要保证正负样本的平衡(数目相似)。
对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物 品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣。
那么,接下去的问题就是如何计算矩阵P和矩阵Q中参数值。一般做法就是最优化损失函数来求参数。在定义损失函数之前,我们需要准备一下数据集并对兴趣度的取值做一说明。
按照物品的流行度采样出了那些热门的、但用户却没有过行为的物品。经过采样,可 以得到一个用户—物品集k= {(u ,i)} ,其中如果(u, i)是正样本,则有 Rui =1 ,否则有 Ruir =0 。然后, 需要优化如下的损失函数来找到最合适的参数p和q:

这里:
是用来防止过拟合的正则化项,λ可以通过实验获得。要最小化上面 的损失函数,可以利用一种称为随机梯度下降法①的算法。该算法是最优化理论里最基础的优化 算法,它首先通过求参数的偏导数找到最速下降方向,然后通过迭代法不断地优化参数。下面介 绍优化方法的数学推导。

然后,根据随机梯度下降法,需要将参数沿着最速下降方向向前推进,因此可以得到如下递推 公式:
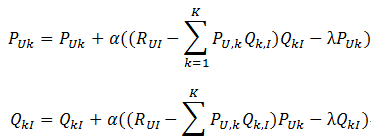
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。
综上所述,执行LFM需要:
1.根据数据集初始化P和Q矩阵。
2.确定4个参数:分类数F,迭代次数N,学习速率α,正则化参数λ。
我们同样通过离线实验评测LFM的性能。首先,我们在MovieLens数据集上用LFM计算出用 户兴趣向量p和物品向量q,然后对于每个隐类找出权重最大的物品。如表2-13所示,表中展示了 4个隐类中排名最高(qik最大)的一些电影。结果表明,每一类的电影都是合理的,都代表了一 类用户喜欢看的电影。从而说明LFM确实可以实现通过用户行为将物品聚类的功能。
其次,我们通过实验对比了LFM在TopN推荐中的性能。在LFM中,重要的参数有4个:
隐特征的个数F;
学习速率alpha;
正则化参数lambda;
负样本/正样本比例 ratio。
通过实验发现,ratio参数对LFM的性能影响最大。因此,固定F=100、alpha=0.02、 lambda=0.01,然后研究负样本/正样本比例ratio对推荐结果性能的影响。
2.6 基于图的模型
用户行为很容易用二分图表示,因此很多图的算法都可以用到推荐系统中。这里将重点讨论 如何将用户行为用图表示,并利用图的算法给用户进行个性化推荐。
研究人员设计了很多计算图中顶点之间相关性的方法①。这里将介绍 一种基于随机游走的PersonalRank算法②
假设要给用户u进行个性化推荐,可以从用户u对应的节点vu开始在用户物品二分图上进行随 机游走。游走到任何一个节点时,首先按照概率 α 决定是继续游走,还是停止这次游走并从vu节 点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一 个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率 会收敛到一个数。最终的推荐列表中物品的权重就是物品节点的访问概率。