微服务实战之高可用性
高可用性指你提供的服务要始终可用, 不管天灾(停电, 断网, 磁盘空间满, 服务器硬件损坏等), 人祸(软件bug, 黑客破坏, 误操作等), 甚至地震, 洪水抑或战争.
高可性性的指标就是可用时间与总时间之比
availability = uptime/(uptime + downtime)
现在普遍要求可用性至少达到两个九, 最好在四个九以上, 也就是说你的服务要达到如下要求
| 可用性 % | 每年不可用时间 | 每月不可用时间 | 每周不可用时间 | 每天不可用时间 |
|---|---|---|---|---|
| 90% 一个九 | 36.5 天 | 72 小时 | 16.8 小时 | 2.4 小时 |
| 99% 两个九 | 3.65 天 | 7.20 小时 | 1.68 小时 | 14.4 分钟 |
| 99.9% 三个九 | 8.76 小时 | 43.8 分钟 | 10.1 分钟 | 1.44 分钟 |
| 99.99% 四个九 | 52.56 分钟 | 4.38 分钟 | 1.01 分钟 | 8.64 秒 |
为了达到高可用性, 必须在设计, 实现, 运维等各个方面着手, 才到达到随时可用的目标.
根据我的经验, 分以下三个方面来谈谈
- 高可用性设计
- 高可用性实现
- 高可用性运维
高可用性和高扩展性相关, 另外再深谈关于扩展性的话题
高可用性设计
高可用的不二法宝是冗余, 也就是说, 为了避免单点失败(Single Point Failure), 会增加一到多个点, 而且最好放在不同的物理位置, 降低多点失败的概率.
具体来说, 服务器之间的关系有主从(primary/slave)关系, 主主(active-active)关系.
再细分的话有一主多仆, 多主多仆, 对等自治等关系, 是一个服务器集集群还是多个服务器集群.
举例来说, 我有一个聊天服务器, 提供公司内部的机密对话聊天服务
通过 Web App 经 Web Socket 通过 TLS 和服务器进行通讯.
这台服务器放在北京总部, 时而由于断网和断电造成服务器不可用, 于是我又增加了一台服务器, 为避免总部大厦停电可能造成其他分公司的服务不可用, 后来又在上海分公司搭建了两台服务器. 最终的拓扑结构如下:
数据存储采用 Cassandra , LoadBalancer 用 HAProxy, ChatService 是自己写的应用服务器, 数据存储采用Cassandra
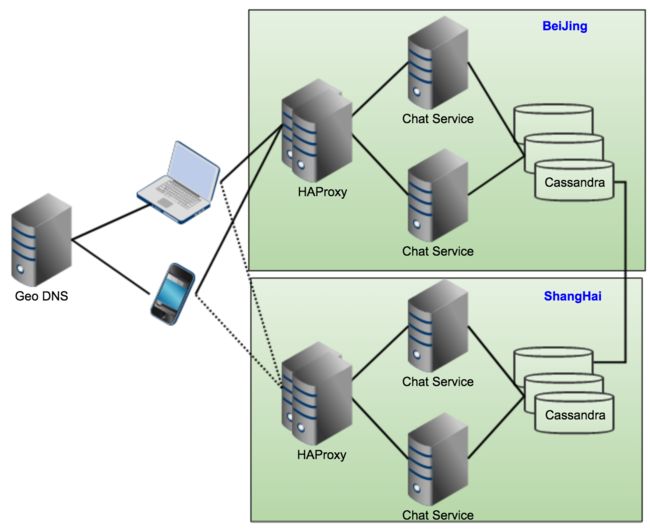
这个架构符合了基本的高可用性要求, 没有单点失败, 数据通过Cassandra 进行存储, 并且进行内部及跨区域的数据同步.
高可用性的关键难点在于状态同步和一致性要求, 上例中采用的 Cassandra 只能保证最终一致性, 要是用于支付结算系统, 会有点问题.
Cassandra 看起来很美, 它不象MySQL, 结点之间没有主从之分, 均为可读可写, 高度可扩展, 可是实际应用起来, 在大数据量, 高并发请求的场景下经常出现读取数据超时的情况, 这里不展开讲, 请参见 微服务实战之Cassandra
避免单点失败是基本要求,要达到两个九以上,这还远远不够。
当大量用户请求峰值来临时,极有可能由于压力过大,造成整个系统不可用,这时候,要么按需扩展增加服务器,存储器等资源,要么让服务降级或变慢,也要保持整个系统的可用。
要尽可能地自动化,在重大故障和紧急时刻也要能及时通知运维工程师进行快速反应和故障恢复。有道是,隐患险于明火,防范胜于胜于救灾,责任重于泰山,在技术和非技术层面都要做好预案,做足功课,有备无患。
基本度量 metrics, 我们可以做如下的基本功课
分流
使用反向代理, 负载均衡器将负载均匀分配给多个微服务器实例, 简单场景下使用简单的 round-robbin 策略就够了.
复杂的情况下必须参照各个微服务实例上的负载情况做分流限流
每个实例的负载是一定的, 如果负载过高, 超过了其处理能力, 可能会造成整个系统不可用的状况.
对于特定用户, IP和组织, 我们最好设定一个上限的阀值, 根据metrics 统计, 如果超过这个阀值可以返回错误码(429)让其过会儿重试(retry-after)断流
当某个实例持续出现问题, 与其超时, 失败, 再不断重试, 不如直接断开, 过会儿再尝试访问它, 这个在断路器模式再详细讨论
这个断路器的打开和关闭也是基于 metrics
高可用性实现
设计要为失败而设计, 在实现时要处处考虑失败的可能性, 比如异常关机, 内存耗尽了, 磁盘满了, 网断了, 以及安全性考虑, 防止可能的恶意攻击和破坏.
安全方面的 AAA认证, 授权, 审计, 防止SQL 注入, 跨域攻击, 在 [微服务实战之安全性] 详述.
我们在编程开发中要牢记三点
- 容错
- 防错
- 纠错
容错
所谓容错性开发,是指在系统某些模块或外部依赖出错的情况下,系统依然能保持基本可用
比如
- 网络连接断开了或不可达,进行重试直至恢复
- 内存不够用了, 就序列化到一部分到磁盘上后释放一部分内存
- 某个外部服务不可用, 给予用户友好提示并提供备选方案
防错
而防错性开发是指预先采取措施防止错误, 比如对于输入参数的有效性及合法性检查, 数据存储总有冗余和备份, 这是实现高用性的重点, 其中尤其要注意
-
- 防止资源耗尽.
在内存, CPU, 磁盘, 带宽, 数据库等外部资源的使用上, 必须牢记资源有借有还, 切勿任意无节制的使用.
常见的有错误有
1) 内存泄漏
2) 文件句柄泄漏
3) 内部集合增长过快, 删除过慢
4) 网络或数据库连接泄漏
5) 栈空间溢出
6) 无节制的创建线程
7) 不当的循环造成的CPU繁忙
8) 某些异常导致的 log过多且没有 rotate ,从而把磁盘写满
-
- 对请求频率加以限制 Rate Limit
对于超过规定的频率和数量的请求, 服务器会对特定的客户端暂停或降级服务,防止局部问题影响整个系统的稳定。
-
- 加强欺诈检测和保护 Fraud detection and protection
对于可疑的请求和客户端定义按既有策略进行检测和保护, 比如对于单位时间内来自某个IP地址或者某个帐号的超量请求, 异常密码尝试, 异常越权尝试进行暂时锁定
纠错
纠错性开发是指预先设置错误处理预案,制订应急响应, 比如在上线新版本出现重大bug时,在至多几分钟内就能迅速回滚至上个版本, 或者可以迅速关掉引起错误某个功能开关
在系统中定义了一些告警阀值,并设置回调,一旦触发警报,即进入紧急状态,采取紧急措施
如磁盘剩余空间预警,则自动清理一周之前的日志数据,并呼叫值班人员紧急待命,或者增加磁盘空间或挂接新磁盘
如发现下游所依赖的服务响应太慢或如发现日志中某一类错误超过阀值,则立即触发告警和自动分析程序, 提醒值班人员排查原因并给予解决
并且要支持自动和手动故障恢复 Auto fallback and manual fallback, 对于单点失败零容忍
- 单个服务器挂掉无所谓
- 单个机房挂掉无所谓
- 单个数据中心挂掉无所谓
- 单个地区中的服务挂掉无所谓
具体来说就是提供足够的冗余备份.
基于HTTP Restful 的无状态服务可以充分利用dns, load balance 的相应的功能
而一些基于长连接的有状态服务,dns不管用,LB的支持也有缺陷,可能需要应用程序自己来设计实现服务的 Failover
高可用性运维
基本要求是按需求快速恢复故障,快速部署或回滚服务,从容应对各种突发事件,快速解决各种软硬件故障,一句话,又快又稳,安全第一.
基本手段有:
- 1. 实时监控和度量 Monitor and metrics
每台服务器和重特性都有足够的监控和度量, 比如常规的健康检查 Health Check , 可以每分钟做一次, 比较简单的做法是服务提供health check 和接口或API, 通过调用这些API并检查其结果来判断服务是否可用, 是否需要做服务切换.
-
- 实时产线自动化测试
有一些基于TCP或UDP的心跳检查, 基于SNMP 事件的监控机制, 个人觉得 TaP( Test Against Production) 产线自动化功能测试最有针对性, 检查的粒度最细, 也最能发现一些深层次的问题
比如挑出一些比较重要和稳定的自动化测试用命, 在系统的某个闲时, 直接在产品线上运行一系列有针对性的测试
-
- 定时进行常规化维护
比如定期对日志文件进行归档, 清理无用文件和数据库记录, 定时重启服务器以防止细微的内存泄漏和内存碎片等等
-
- 灾难 Disaster Recover
在遇到突发的重大软硬件故障时, 及时进行灾难恢复, 将服务切换到备份服务器, 集群或数据中心上