基于Keras的卷积神经网络用于猫狗分类(进行了数据增强)+卷积层可视化
接着我上一篇博客,https://blog.csdn.net/fanzonghao/article/details/81149153。
在上一篇基础上对数据集进行数据增强。函数如下:
"""
查看图像增强是否发生作用
"""
def see_pic_aug():
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 从训练集例返回图片的地址
train_dir, validation_dir, cat_img_files, dog_img_files = data_read.read_data()
# 返回随机一张图片的地址
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150))
x = img_to_array(img)
# 变成(1,150,150,3)
x = x.reshape((1,) + x.shape)
i = 0
for batch in train_datagen.flow(x, batch_size=1):
plt.figure(i)
plt.imshow(array_to_img(batch[0]))
i += 1
if i % 5 == 0:
break
plt.show()打印5张查看:




确实发生了一些改变。
下面就用数据增强的样本训练模型,代码如下:
import numpy as np
import matplotlib.pyplot as plt
import random
import data_read
import tensorflow as tf
from keras.models import Model
from keras import layers,optimizers
from keras import backend as K
from keras.preprocessing.image import ImageDataGenerator,img_to_array,load_img,array_to_img
"""
获得所需求的图片--进行了图像增强
"""
def data_deal_overfit():
# 获取数据的路径
train_dir, validation_dir, next_cat_pix, next_dog_pix = data_read.read_data()
#图像增强
train_datagen=ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen=ImageDataGenerator(rescale=1./255)
#从文件夹获取所需要求的图片
train_generator=train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
return train_generator,test_generator
"""
定义模型并加入了dropout
"""
def define_model():
#定义TF backend session
# tf_config=tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))
# K.set_session(tf.Session(config=tf_config))
#卷积过程 三层卷积
img_input=layers.Input(shape=(150,150,3))
x=layers.Conv2D(filters=16,kernel_size=(3,3),activation='relu')(img_input)
print('第一次卷积尺寸={}'.format(x.shape))
x=layers.MaxPooling2D(strides=(2,2))(x)
print('第一次池化尺寸={}'.format(x.shape))
x=layers.Conv2D(filters=32,kernel_size=(3,3),activation='relu')(x)
print('第二次卷积尺寸={}'.format(x.shape))
x=layers.MaxPooling2D(strides=(2,2))(x)
print('第二次池化尺寸={}'.format(x.shape))
x=layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu')(x)
print('第三次卷积尺寸={}'.format(x.shape))
x=layers.MaxPooling2D(strides=(2,2))(x)
print('第三次池化尺寸={}'.format(x.shape))
#全连接层
x=layers.Flatten()(x)
x=layers.Dense(512,activation='relu')(x)
output=layers.Dense(1,activation='sigmoid')(x)
model=Model(inputs=img_input,outputs=output,name='CAT_DOG_Model')
return img_input,model
"""
训练模型
"""
def train_model():
#构建网络模型
img_input,model=define_model()
#编译模型
model.compile(optimizer=optimizers.RMSprop(lr=0.001),loss='binary_crossentropy',metrics=['accuracy'])
train_generator,test_generator=data_deal_overfit()
#verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
#训练模型 返回history包含各种精度和损失
history=model.fit_generator(
train_generator,
steps_per_epoch=100,#2000 images=batch_szie*steps
epochs=1,
validation_data=test_generator,
validation_steps=50,#1000=20*50
verbose=2)
# 模型参数个数
model.summary()
#精度
acc=history.history['acc']
val_acc=history.history['val_acc']
#损失
loss=history.history['loss']
val_loss=history.history['val_loss']
#epochs的数量
epochs=range(len(acc))
plt.plot(epochs,acc)
plt.plot(epochs, val_acc)
plt.title('training and validation accuracy')
plt.figure()
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('training and validation loss')
plt.show()
#测试图片
# 从训练集例返回图片的地址
train_dir, validation_dir, cat_img_files, dog_img_files = data_read.read_data()
# 返回随机一张图片的地址
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150))
plt.imshow(img)
plt.show()
x = img_to_array(img)
# 变成(1,150,150,3)
x = x.reshape((1,) + x.shape)
y_pred=model.predict(x)
print('预测值y={}'.format(y_pred))
#图形化形式查看卷积层生成的图
def visualize_model():
img_input,model=define_model()
# print(model.layers)
#存储每一层的tensor的shape 类型等
successive_outputs=[layer.output for layer in model.layers]
# print(successive_outputs)
visualization_model=Model(img_input,successive_outputs)
#从训练集例返回图片的地址
train_dir, validation_dir, cat_img_files,dog_img_files = data_read.read_data()
#返回随机一张图片的地址
img_path=random.choice(cat_img_files+dog_img_files)
img=load_img(img_path,target_size=(150,150))
x=img_to_array(img)
#print(x.shape)
#变成(1,150,150,3)
x=x.reshape((1,)+x.shape)
x/=255
#(samples,150,150,3) 存储10层的信息
successive_feature_maps=visualization_model.predict(x)
# print(len(successive_feature_maps))
# for i in range(len(successive_feature_maps)):
# print(successive_feature_maps[i].shape)
layer_names=[layer.name for layer in model.layers]
#zip 打包成一个个元组以列表形式返回[(),()]
#并且遍历元组里的内容
for layer_name,feature_map in zip(layer_names,successive_feature_maps):
if len(feature_map.shape)==4:#只查看卷积层
n_features=feature_map.shape[-1]#(1,150,150,3)取3 取出深度
size=feature_map.shape[1]##(1,150,150,3)取150 尺寸大小
display_grid=np.zeros((size,size*n_features))
for i in range(n_features):
x=feature_map[0,:,:,i]
x-=x.mean()
x/=x.std()
x*=64
x+=128
#限定x的值大小 小于0 则为0 大于255则为255
x=np.clip(x,0,255).astype('uint8')
display_grid[:,i*size:(i+1)*size]=x
#显示
scale=64./n_features
plt.figure(figsize=(scale*n_features,scale))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid,aspect='auto',cmap='Oranges')
plt.show()
"""
查看图像增强是否发生作用
"""
def see_pic_aug():
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 从训练集例返回图片的地址
train_dir, validation_dir, cat_img_files, dog_img_files = data_read.read_data()
# 返回随机一张图片的地址
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150))
x = img_to_array(img)
# 变成(1,150,150,3)
x = x.reshape((1,) + x.shape)
i = 0
#32个训练样本
for batch in train_datagen.flow(x, batch_size=32):
plt.figure(i)
plt.imshow(array_to_img(batch[0]))
i += 1
if i % 5 == 0:
break
plt.show()
if __name__ == '__main__':
# see_pic_aug()
train_model()
#visualize_model()
# 像素缩小到0~1
迭代100次结果:可看出相比上一篇文章,精度是稳定的,损失值也几乎是稳定的,数据增强还是起了防止过拟合的作用。

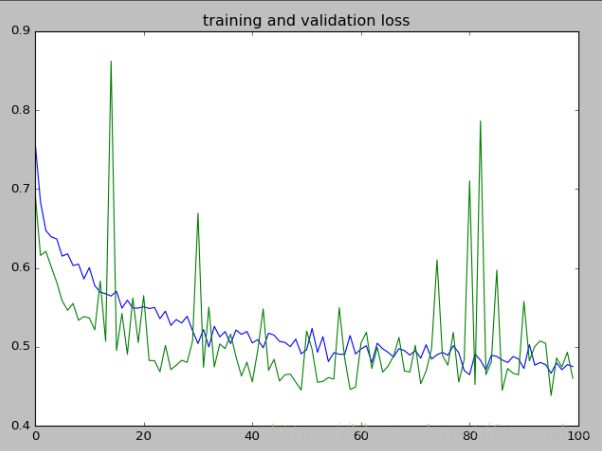

同样可视化卷积层:
![]()
![]()


