Oracle物化视图之 物化视图日志与快速刷新
1、使用物化视图中遇到的问题
一般在创建物化视图的时候,在数据量不大的时候,刷新的方式都是采用完全刷新的。
随着系统的使用一些物化视图的源表的数据量在不断的增长,原本采用完全方式几秒就能刷新完成的物化视图,现在需要等待很久的时间才能刷新完成。
其实物化视图从一开始就帮我们想好了解决方法:通过物化视图日志来实现物化视图的快速刷新;
2、传统完全刷新 区分 快速刷新
完全刷新:先把物化视图的数据全部删除,然后把基表的数据插入到 物化视图中。
当数据达到百万级别时,若原表更新了一条数据,完全刷新就得 插入全部数据
快速刷新:保留物化视图的数据,然后基表的所有数据的变更记录到物化视图日志中
总结: 物化视图日志就是一个数据库引擎创建的表,用来跟踪基表发生的变更
所以若需要进行快速刷新,则需要建立物化视图日志
3、首先分析一下物化视图日志结构
Oracle物化视图日志根据不同物化视图的快速刷新的需要,可以建立为ROWID或PRIMARY KEY类型的。还可以选择是否包括SEQUENCE、INCLUDING NEW VALUES以及指定列的列表。
create table t (id number ,name varchar2(30),val number);
create materialized view log on t with rowid,sequence (id,name) including new values;
删除相应日志表:drop materialized view log on dim_a;
desc mlog$_t

ID和NAME: 标识基表中的列,记录每次DML操作对应的ID 和 NAME的值
m_row$$: 标识基表中ROWID信息,可以定位到发生DML操作的记录
sequence$$: DML操作发生的序列编号
dmltype$$: 标识DML类型
old_new$$: 标识物化视图日志中保存的数据是 DML操作之前的值还是之后的值
chance_vector$$: 记录DML操作发生在哪几个段上
总结:当刷新物化视图时,只需要根据SEQUENCE$$列给出的顺序,通过M_ROW$$定位到基表的记录,如果是UPDATE操作,通过CHANGE_VECTOR$$定位到字段,然后根据基表中的数据重复执行DML操作
4、并不是所有的物化视图都可以进行快速刷新
所有类型的快速刷新物化视图都必须满足的条件:
1.物化视图不能包含对不重复表达式的引用,如SYSDATE和ROWNUM;
2.物化视图不能包含对LONG和LONG RAW数据类型的引用。
只包含连接的物化视图:
1.必须满足所有快速刷新物化视图都满足的条件;
2.不能包括GROUP BY语句或聚集操作;
3.如果在WHERE语句中包含外连接,那么唯一约束必须存在于连接中内表的连接列上;
4.如果不包含外连接,那么WHERE语句没有限制,如果包含外连接,那么WHERE语句中只能使用AND连接,并且只能使用“=”操作。
5.FROM语句列表中所有表的ROWID必须出现在SELECT语句的列表中。
6.FROM语句列表中的所有表必须建立基于ROWID类型的物化视图日志。
参考:https://blog.csdn.net/demonson/article/details/82018706
5、物化视图日志 解决多视图的原理
物化视图日志——必须支持 多视图的快速刷新
也就是在刷新时,必须判断
1. 刷新时必须判断,哪些物化视图日志记录 是当前物化视图需要的(控制更新粒度)
2. 刷新后必须判断,哪些日志需要清除,哪些不需要清除
SQL> create materialized view mv_t_id refresh fast as select id, count(*) from t group by id;
SQL> create materialized view mv_t_name refresh fast as select name, count(*) from t group by name;
SQL> create materialized view mv_t_id_name refresh fast as select id, name, count(*) from t group by id, name;
SQL> insert into t values (1, 'a', 2);
SQL> insert into t values (1, 'b', 3);
SQL> insert into t values (2, 'a', 5);
SQL> insert into t values (3, 'b', 7);
SQL> update t set name = 'c' where id = 3;
SQL> delete t where id = 2;
SQL> commit;
snaptime$$: 4000-01-01 00:00:00。这个值表示这条记录还没有被任何物化视图刷新过,第一个刷新这些记录的物化视图会将SNAPTIME$$的值更新为物化视图当前的刷新时间。
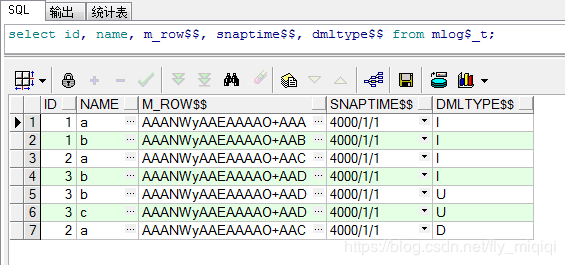
SQL> exec dbms_mview.refresh('MV_T_ID');
SQL> select id, name, m_row$$, snaptime$$, dmltype$$ from mlog$_t;
SQL> select name, last_refresh from user_mview_refresh_times
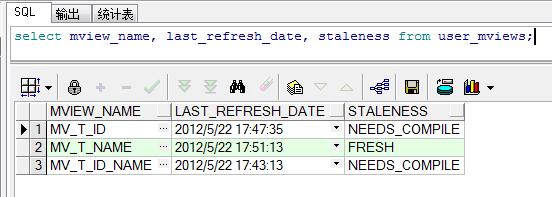
SQL> select mview_name, last_refresh_date, staleness from user_mviews
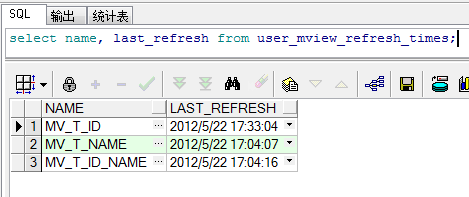
这些视图中记录了每个物化视图上次执行刷新操作的时间,并且给出每个物化视图中的数据是否和基表同步。
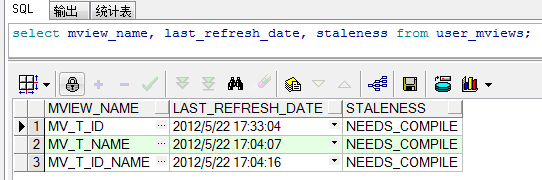
由于MV_T_ID刚刚进行了刷新,因此状态是FRESH,而另外两个由于在刷新(建立)之后,基表又进行了DML操作,因此状态为NEEDS_COMPILE。
如果这时对基表进行DML操作,则MV_T_ID的状态也会变为NEEDS_COMPILE
SQL> insert into t values (4, 'd', 10);
SQL> commit;
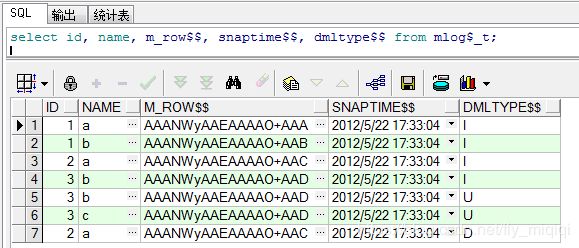
SQL> select id, name, m_row$$, snaptime$$, dmltype$$ from mlog$_t; 【基表记录的 刷新时间】
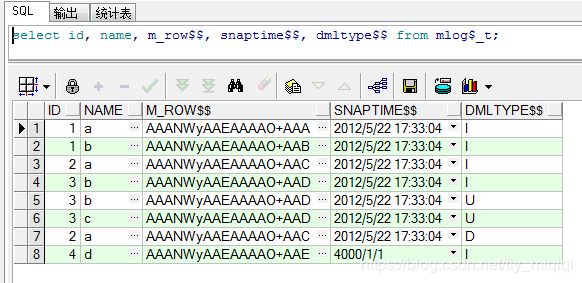
SQL> select mview_name, last_refresh_date, staleness from user_mviews; [物化视图的 刷新时间]
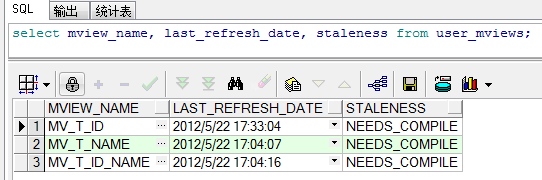
下面刷新MV_T_ID_NAME(上次刷新了MV_T_ID),刷新依据是:
1、仅刷新物化视图日志记录中 SNAPTIME$$列(基表记录的刷新时间) 大于 当前物化视图的LAST_REFRESH_DATE的记录(视图的刷新时间)
2、对于SNAPTIME$$列的值是4000-01-01 00:00:00的记录,物化视图会把SNAPTIME$$列的值更新为当前刷新时间
3、那些已经被更新过的SNAPTIME$$列,则保持原值
SQL> exec dbms_mview.refresh('MV_T_ID_NAME')
SQL> select id, name, m_row$$, snaptime$$, dmltype$$ from mlog$_t;
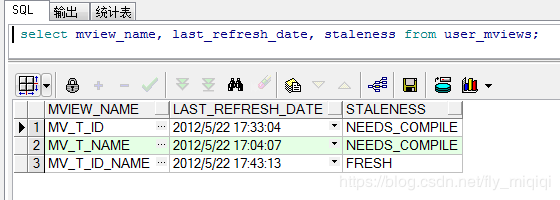
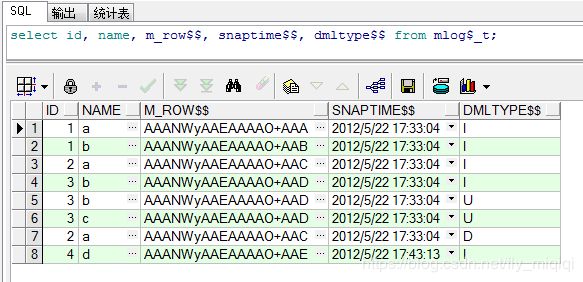
如果这时再次刷新物化视图MV_T_ID,则只有ID=4的这条记录的SNAPTIME$$的时间点大于MV_T_ID上次刷新的时间点,因此,只刷新这一条记录,且不会改变SNAPTIME$$的值。
SQL> exec dbms_mview.refresh('MV_T_ID')
SQL> select id, name, m_row$$, snaptime$$, dmltype$$ from mlog$_t;

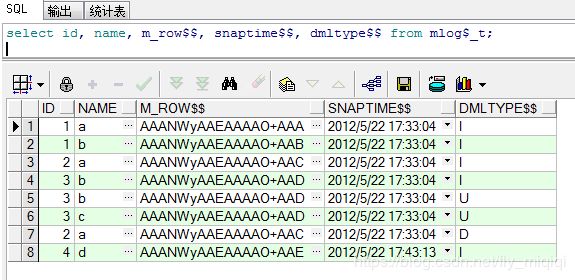
物化视图日志记录的删除
每次进行完刷新,物化视图日志都会试图删除没有用的物化视图日志记录。物化视图日志记录的删除条件是删除那些SNAPTIME$$列(日志记录)小于等于所有物化视图的上次刷新时间===旧数据,已经刷新的数据
SQL> insert into t values (5, 'e', 2);
SQL> commit;
SQL> exec dbms_mview.refresh('MV_T_NAME')
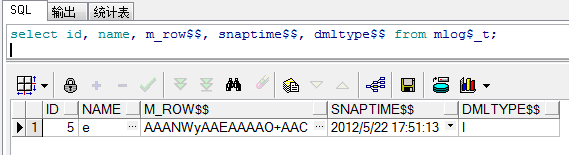

SQL> drop materialized view log on t;
SQL> drop materialized view mv_t_id;
SQL> drop materialized view mv_t_name;
SQL> drop materialized view mv_t_id_name;
SQL> drop table t;
到此 完整删除了 物化视图,物化视图日志,实体表
总结:物化视图在刷新时,会刷新SNAPTIME$$(基表记录 刷新时间)大于该物化视图上次刷新时间(视图刷新时间)的记录,并将所有是4000-01-01 00:00:00的记录更新为当前刷新时间。对于其他大于上次刷新时间的记录,只刷新不更改。这样,当刷新执行完以后,数据字典中记录当前物化视图的上次刷新时间为当前时刻,这保证了物化视图日志中目前所有的记录都小于或等于刷新时间。因此,每个物化视图只要刷新大于上次刷新时间的记录,且保证每次刷新后,所有记录的时间都小于等于上次刷新时间,那么无论有多少个物化视图,就可以互不影响的使用同一个物化视图日志进行快速刷新了。当物化视图刷新完之后,会清除那些SNAPTIME$$列小于所有物化视图的上次刷新时间的记录,而这些记录已经被所有的物化视图都刷新过了,保存在物化视图日志中已经没有意义了。
每个物化视图只要刷新大于上次刷新时间的记录,且保证每次刷新后,所有记录的时间都小于等于上次刷新时间,那么无论有多少个物化视图,就可以互不影响的使用同一个物化视图日志进行快速刷新了