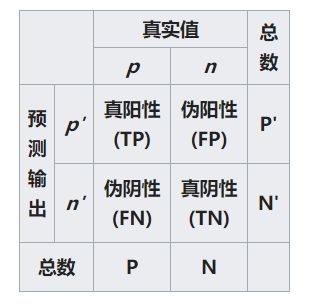
在机器学习中模型进行预测时,会得到一下几个结果:
- 真阳性,TP,True Positive;
- 假阳性,FP,False Positive;
- 真阴性,TN,True Negative;
- 假阴性,FP,False Negative;
而通过TP,FP,TN,FN这几个值又可以间接地计算得到一些能够评价我们模型好坏的指标:
- 真阳性率/召回率(recall)/查全率/敏感度(sensitivity): TPR = TP/(TP+FN);
- 假阳率:FPR = FP/(FP+TN);
- 准确率:Accuracy = (TP+TN)/(TP+FP+TN+FN);
- 真阴性率/特异度(specificity):Specificity = TN/(TN+FP) = 1-FPR ;
- 阳性预测值/Precision:PPV = TP/(TP+FP);
- 阴性预测值:NPV = TN/(TN+FN);
-
假发现率 FDR:FP/(FP+TP).
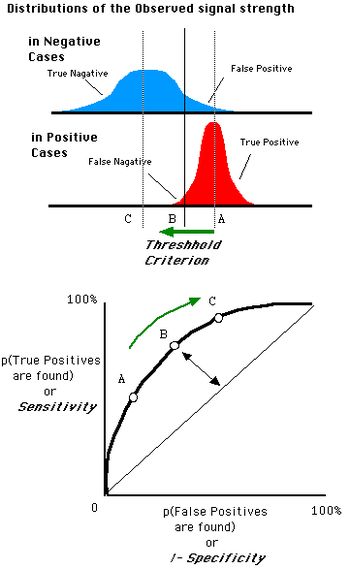
ROC曲线
接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)将假阳性率(FPR/(1-specificity))作为X轴,真阳性率(TPR)作为Y轴,其中:
- 真阳性率(TPR)表示在所有实际为阳性的样本中,模型预测的阳性样本所占的比率:TPR = TP/(TP+FN);
- 假阳性率(FPR/(1-specificity))表示在所有实际为阴性的样本中,模型错误预测为阳性样本所占的比率:FPR = FP/(FP+TN).
给定一个二元分类模型和它的阈值(通常是一个概率),就能从所有样本的真实值和预测值计算出一个坐标点(X=FPR,Y=TPR)坐标点。将同一个模型每个阈值的(FPR,TPR)坐标都画在ROC空间里,就成为特定模型的ROC曲线。
从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。
完美的预测点是一个在左上角的点,在ROC空间坐标(0,1)点,X=0代表着没有假阳性(所有阴性均正确预测),Y=1代表没有假阴性(所有阳性均正确预测),也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。
ROC曲线的一些规律:
- 当阈值设定为最高时,亦即所有样本都被预测为阴性,没有样本被预测为阳性,此时在伪阳性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同时在真阳性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%。
→ 当阈值设定为最高时,必得出ROC座标系左下角的点 (0, 0)。- 当阈值设定为最低时,亦即所有样本都被预测为阳性,没有样本被预测为阴性,此时在伪阳性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同时在真阳性率 TPR = TP / ( TP + FN ) 算式中的 FN = 0,所以 TPR=100%
→ 当阈值设定为最低时,必得出ROC座标系右上角的点 (1, 1)。- 因为TP、FP、TN、FN都是累积次数,TN和FN随着阈值调低而减少(或持平),TP和FP随着阈值调低而增加(或持平),所以FPR和TPR皆必随着阈值调低而增加(或持平)。
→ 随着阈值调低,ROC点 往右上(或右/或上)移动,或不动;但绝不会往左下(或左/或下)移动。
 图片来自维基百科
图片来自维基百科
曲线下面积(AUC)
在比较不同的分类模型时,可以将每个模型的ROC曲线都画出来,比较曲线下面积(即AUC)做为模型优劣的指标。
ROC曲线下方的面积(Area under the Curve of ROC (AUC ROC)),其意义是:
- 因为是在1x1方格里求面积,AUC必在0~1之间;
- 假设阈值以上是阳性,以下是阴性;
- 若随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本的概率为AUC;
- 简单说,AUC值越大的分类器,正确率越高
更大白话的解释AUC的意义:
从所有1样本中随机选取一个样本, 从所有0样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把1样本预测为1的概率为p1,把0样本预测为1的概率为p0,p1>p0的概率就等于AUC。所以AUC反应的是分类器对样本的排序能力。ROC AUC的数值与每个预测概率的数值大小无关,在乎的是每个预测概率的排序。假设我们按照概率从大到小排。如果根据你的预测结果,所有标签为1的样本都排在了标签为0的样本前面,那么你的ROC AUC就是1。
ROC AUC = 0.8的意思是说,随机挑选个标签为1的样本,它被排在随机的0样本的前面的概率是0.8。显然ROC AUC是0.5的话,就说明这个模型和随便猜没什么两样。
AUC值越大,当前的分类算法越有可能将正样本排在负样本前面(即将正样本预测为正样本的概率大于负样本预测为正样本的概率),即能够更好的分类。
FROC曲线
FROC (Free-response ROC) 曲线常在图像识别任务中作为效果评估指标。
经典的ROC方法不能解决对一幅图像上多个异常进行评价的实际问题,70年代提出了无限制ROC的概念(free-response ROC;FROC)。FROC允许对每幅图像上的任意异常进行评价。
FROC曲线与之前的ROC只是横坐标的不同。横坐标是误报率(测试中所有不是实际结节预测成结节的个数/测试CT个数),纵坐标是召回率(测试所有CT数据中实际是结节的检测出来个数/测试所有CT数据中实际是结节个数)。
具体举个简单的例子:我们的测试集就两个ct序列:
第一个其中真结节2个,检测出的结节自信度列表[0.99,0.8,0.7,0.5,0.4,...](已经从大到小排列过了),其中真结节是0.99和0.5对应的结节。
第二个其中真结节1个,检测出的结节自信度列表[0.9,0.8,0.7,0.6,0.5,...]其中真结节0.8对应的结节.
假设你把自信度阈值设置为0.90(这个值在计算时一般有一个等比列表),那么这时检测到了一个真结节,召回率是(1+0)/(2+1)=1/3,而误报率是(0+1)/(2)=1/2,(0+1)代表所有CT序列中误报结节数,(2)代表CT序列的个数。这可以画出FROC中的点(1/2,1/3)。
然后,你再把自信度阈值设置为0.80,那么这时检测到的还是二个真结节,召回率是(1+1)/(2+1)=2/3,而误报率是(1+1)/(2)=1,这可以画出FROC中的点(1,2/3)。
以此类推当你把自信度阈值设置为0.5时,那么这时检测到的就是三个真结节,召回率是3/3=1,而误报率是(6)/(2)=3,这可以画出FROC中的点(3,1)。
这样就能画出一条FROC曲线来了。
参考:
维基百科:ROC曲线
关于肺结节检测相关的FROC曲线和目标检测中Precision-Recall曲线,ROC曲线,mAP,AP,APs,APm,APl,AP0.5等的理解
如何理解机器学习和统计中的AUC?