DataOps:数据中台的必备底座
【与数据同行】已开通综合、数据仓库、数据分析、产品经理、数据治理及机器学习六大专业群,加微信号frank61822702 为好友后入群。新开招聘微信群,请关注【与数据同行】公众号,后台回复“招聘”后获得入群方法。
前言
数据中台的崛起代表了企业数字化转型从流程驱动走向数据驱动,从数字化走向智能化。而DataOps则是数据中台区别于传统企业数据架构的核心差异,是建设数据中台的必备底座能力。
要上数据中台,DataOps是核心能力,那么什么是DataOps,为什么企业需要DataOps,如何建设DataOps体系呢?
凯哥做了全面的研究,帮助你全面理解DataOps的价值以及结构,全文共5388字,预估阅读时间 :21分钟。
什么是DataOps
、
DataOps的历史
2014年,Lenny Liebmann提出DataOps[1]的概念,在《3 reasons why DataOps is essential for big data success》这篇文章中,Lenny提出DataOps是优化数据科学和运营团队之间协作的一些实践集。
2015年,Andy Palmer[2]将这个理念发扬光大,提出了DataOps的四个关键构成,数据工程,数据集成,数据安全和数据质量。
2017年,Nexla的Jarah Euston把DataOps的核心定义为从数据到价值,这个是首次把DataOps和业务价值关联起来的定义。
2018年,Gartner把DataOps纳入到Data Management的技术成熟度曲线,标志着DataOps正式被业界所接纳并推广起来。
DataOps是一种协作式数据管理的实践,致力于改善组织中数据管理者与使用者之间数据流的沟通,集成和自动化。
像DevOps一样,DataOps也不是一成不变的教条,而是一种基于原则的实践,会影响如何提供和更新数据以满足组织数据消费者的需求。
Gartner研究副总裁Nick Heudecker表示:“ DataOps是一种没有任何标准或框架的新实践。”越来越多的技术提供商在谈论他们的产品时已经开始使用该术语,而且我们还看到数据和分析团队在关注这一概念,DataOps正处于迅速上升的周期。”
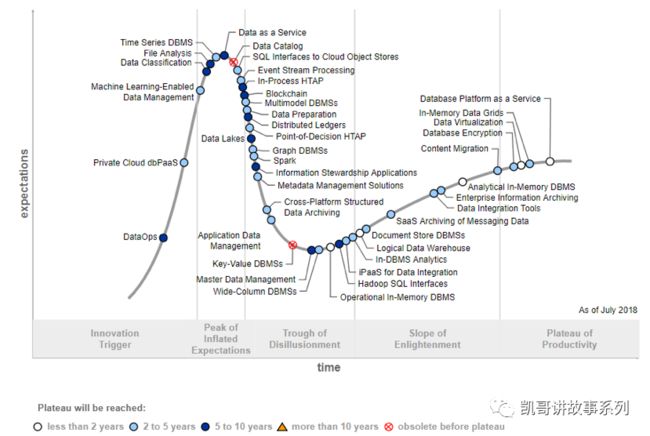
DataOps的出现是在DevOps,Agile,Lean的发展基础上,应对企业不断增长的数据分析,数据利用的需求的一种解决方案。
DataOps的定义
DataOps在行业里的定义有不少,比较权威的有以下几个:
DataOps (data operations) is an Agile approach to designing, implementing and maintaining a distributed data architecture that will support a wide range of open source tools and frameworks in production。The goal of DataOps is to create business value from big data。[3]
DataOps(数据运营)是以一种敏捷的方法,用来设计、实施和维护分布式数据架构,支持广泛的开源工具和框架,数据运营的目的是从大数据中获取业务价值。
这个定义中,强调敏捷的方法。
DataOps is an automated, process-oriented methodology, used by analytic and data teams, to improve the quality and reduce the cycle time of data analytics.[4]
DataOps是一个自动的、面向流程的方法论,被数据和分析团队使用,从而提高质量缩短数据分析的周期。
这个定义中,强调自动的方式。
DataOps is the function within an organization that controls the data journey from source to value.
DataOps是在一个组织中控制数据旅程从而产生价值的一个职能。
这个定义中,强调的是数据旅程和业务价值。
DataOps applies rigor to developing, testing, and deploying code that manages data flows and creates analytic solutions.
DataOps对开发,测试和部署代码进行了严格的管理,这些代码管理数据流并创建分析解决方案。
这个定义中,强调了对于数据流的管理。
我个人觉得下面这个图是更加清晰的表达了DataOps的定义的:
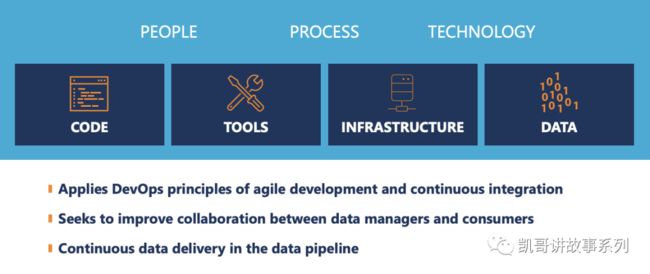
DataOps是包括人,流程和技术的一组体系,用来管理代码,工具,基础架构和数据本身,从而实现三个核心功能:
将DevOps的敏捷开发和持续集成应用到数据领域
优化和改进数据管理者(生产者)和数据消费者的协作
持续交付数据流生产线
而下图则高度抽象的体现了DataOps的三要素:持续集成,持续开发,持续部署 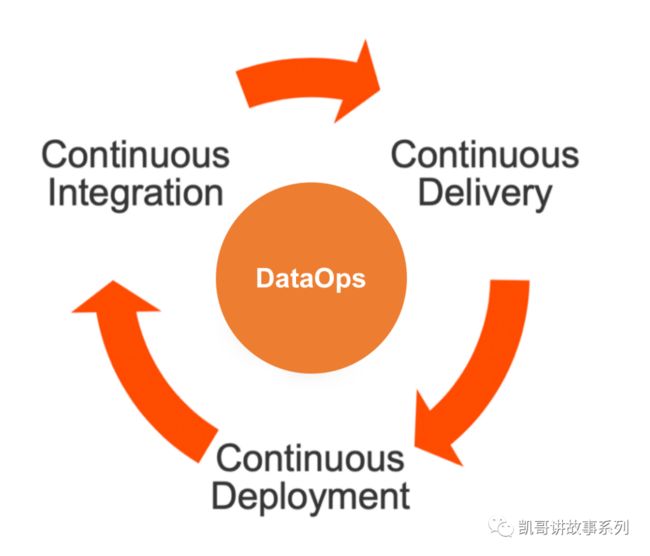
为什么需要DataOps
DataOps的出现,从因为数字化转型进入了数据为核心的智能时代,为了满足企业对于数据管理,数据利用的三大战略趋势:
数据分析民主化/Democratization of Data Analytics
原来数据分析能力是企业少数人需要掌握和构建的能力,而现在数据分析已经在走向民主化的趋势,任何一个岗位都需要数据的支撑。所以如何能够让数据和分析能力可以广泛的被所有背景的人所掌握,成为了企业数据部门所追求的目标。
而传统的数据分析的过程是非常复杂的,如下图所示:
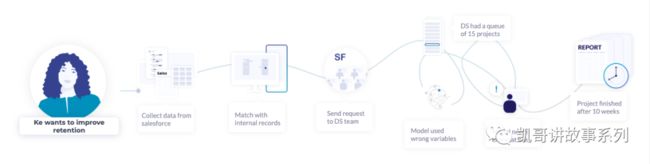
DataOps要解决的首要问题就是构建一套体系能够降低人们使用,利用,分析数据的门槛,让所有人都能够“玩数据”。
数据技术多元化/Diversification of Data Technology
十年以来,数据处理和利用的技术(Data-Tech)的发展突飞猛进,从原来的中心化的数据仓库,ETL技术,衍生到了一个繁杂的数据技术体系,细分成多种数据处理领域,比如:
数据分析
数据可视化
机器学习
云数据处理
流式数据处理
离线数据处理
统计和数据挖掘
每一个领域又有多元化的数据处理工具,框架,如下图所示:

https://dev.to/minchulkim87/my-data-science-tech-stack-2020-1poa
这大大加剧了数据工作者的入门的门槛和学习复杂度。
DataOps很重要的一个目的就是利用这个体系,能够降低这个复杂度,让数据工作者能够更容易的驾驭这些越来越复杂和多元化的数据技术和工具体系。
业务价值精益化/Lean of Business Value
企业对于数据部门的诉求,从“更好的管理数据资产”已经转化为“更快的产生业务价值”。那么如何能够精益化的识别数据的业务价值,并且快速验证,产生和转化业务价值,成为了企业数据部门的头等大事。
这个背景下,DataOps承担着持续支持业务价值产生的使命,如何能够加速业务价值的试验,是错,识别,生产的周期,支撑精益业务价值体系是DataOps构建的核心目标。
DataOps的收益
DataOps的构建对于企业有很多的收益,总结下来有如下这些点:
提供实时的数据洞察能力
加速数据应用的构建过程
让数据价值链的每一个角色都能更好,更高效的协作
提高数据的透明度,从而能够更好的产生数据创新和增进协作
提升数据和数据服务的可复用性
优化数据质量
构建一个统一的,标准化的,同源的数据协作平台
为了更直观的体现有了DataOps和没有DataOps的区别,下图的对比是一个很好理解的方式:
下图是一个典型的传统数据生产过程:
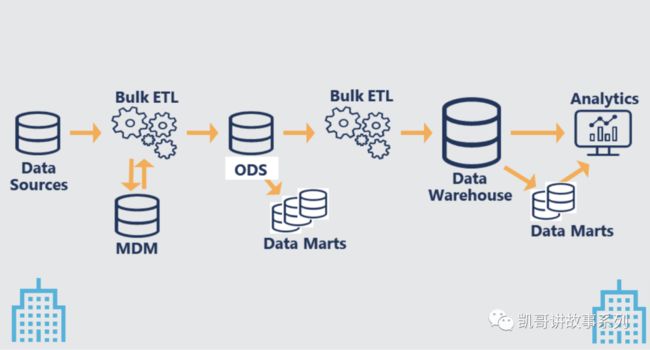
从数据源,到主数据,再到运营型数据集市,再到数据仓库,最终进行数据分析,整个过程有以下的问题:
重复批量的数据移动
难以管理的硬编码ETL(工具类SQL编写的ET)
单体数据架构
业务响应慢

DataOps要构建的数据处理流程是如下所示的:
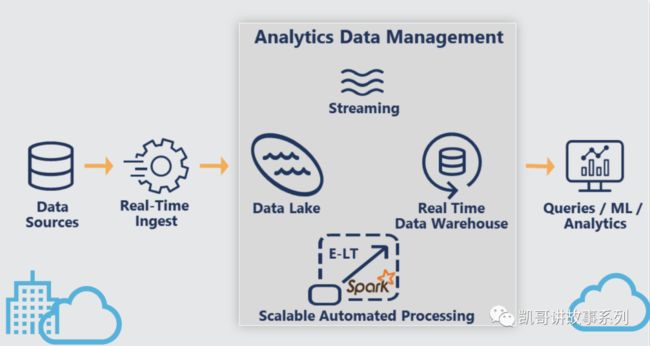 从数据源直接实时获取数据,然后进入数据湖,通过流式数据处理,实时数据仓库,规模化的自动数据处理过程等工具构建分析数据管理闭环,最终输出多元化的数据服务。
从数据源直接实时获取数据,然后进入数据湖,通过流式数据处理,实时数据仓库,规模化的自动数据处理过程等工具构建分析数据管理闭环,最终输出多元化的数据服务。
这样的模式能够带来如下的收益:
实时数据移动
自动化的设计和代码生成
业务场景驱动的规模化技术架构
高响应力

这样以来,DataOps支撑着从源数据到业务价值的整个价值链如下图所示:
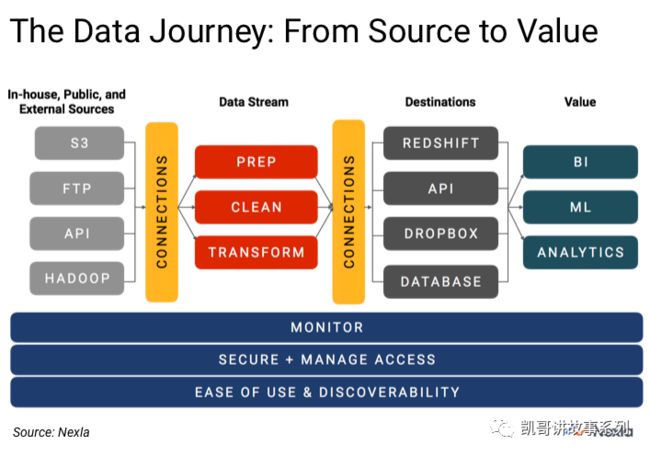
用Eckerson的Wayne Eckerson的一句话来形容DataOps的价值:
![]()
“每一个数据处理链中,数据必须能够被定义、获取、格式化、标签化、被验证、被画像、被清洗、被转换,被合并,被集成,安全的,目录化,被治理,被移动,被查询,被可视化,被分析和被执行。”
这就是现代化的DataOps体系需要具备的能力。

DataOps的四个能力构成
DataOps被业界公认的分成了四个关键构成,或者说是能力结构。
如下图所示,在Agile,DevOps和Lean的加持下,DataOps包括数据工程、数据集成、数据安全和隐私,数据质量四个能力构成:
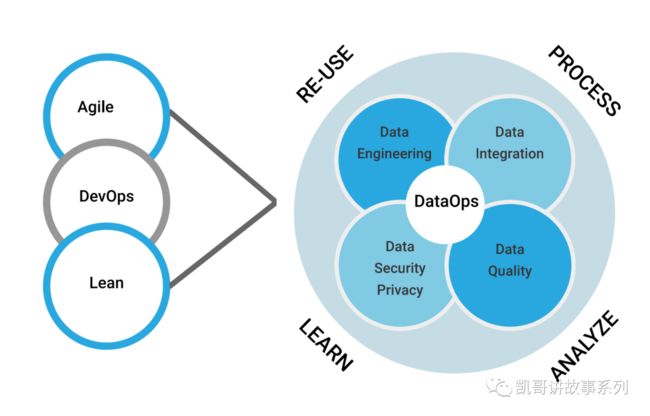
数据工程/Data Engineering
DataOps的核心是数据工程能力,就是利用软件工程来处理和加工数据的能力,也就是从数据源到数据产品中间的过程,可以用下图来简单表示:
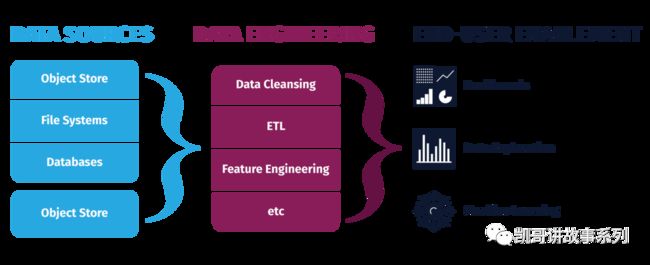
一般包括数据清晰,数据处理,特征工程等过程。
数据集成/Data Integration
在数据处理过程中,处理多样化的数据来源,让他们能够相互集成,相互补充,是DataOps里面很重要的能力,主要包括不同数据源系统,数据模型,数据平台,数据格式,数据标准等多方的集成处理过程,如下图所示:

数据安全和隐私/Data Security & Privacy
在DataOps的全过程中,如何能够提供全方位,端到端的数据安全和隐私的管理支撑,是非常重要的核心功能,所以行业里有时候也称其为:DataSecOps。

数据质量/Data Quality
数据质量管理是DataOps的重要价值和能力,我们一般用下面的7个维度来度量数据的质量,一致性,准确性,可靠性,有序性,唯一性和及时性:
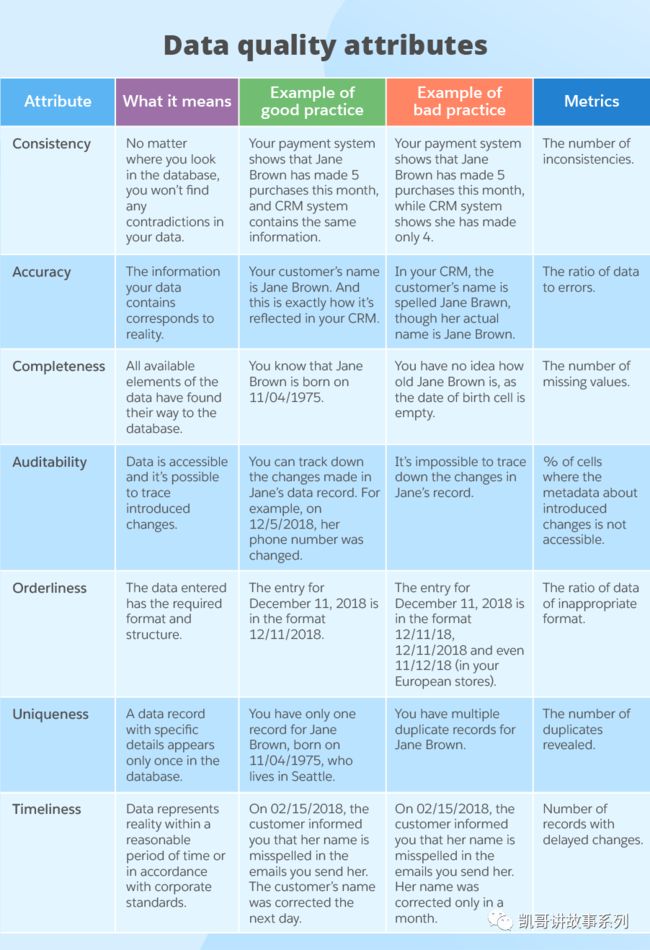
https://www.scnsoft.com/blog/guide-to-data-quality-management
成功DataOps的四个特质CAUTA
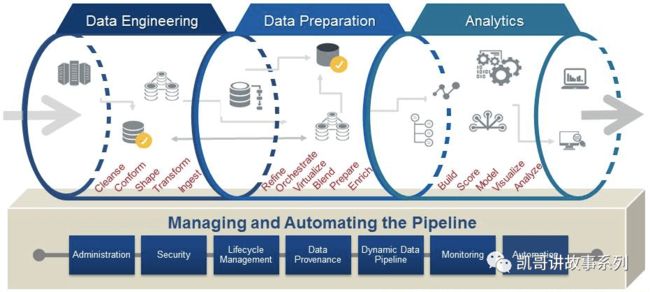
上图是典型的数据价值链过程,而DataOps就是支撑着整个全生命周期的底座,成功的DataOps体系有四个特质:CAUTA。
持续/Continuous
DataOps首要保证的就是尽可能的持续性,不间断,不论什么样的情况出现,都能够自适应的持续让Data Pipeline流动起来,所以持续性是DataOps的首要特质。
持续性可以总结为三个关键点:

保证当流数据和元数据发生变化时能够持续
交易系统数据日志数据对于DataOps的最小影响
对于所有的源系统和目标系统都有一定的优化
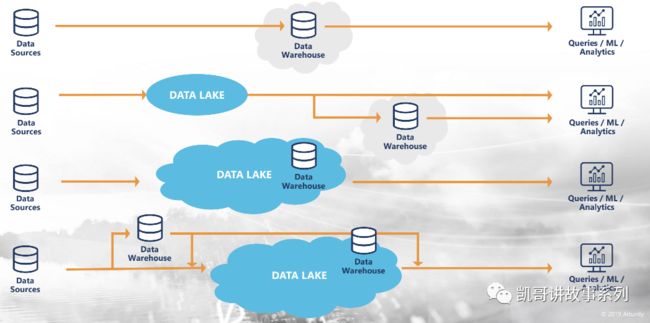
敏捷Agilitly
在持续的基础上,DataOps需要一定的敏捷性,能够快速响应外部的各种变化,主要从三个角度:

支持多种部署模式,公有云,私有云
自动支持数据湖和数据仓库
支持未来的架构变化
用下图可以更好地理解一个好的DataOps体系需要支持的四种数据部署模式:
全面/Universal
作为企业全域数据的底座,DataOps要全面的支持所有的场景和数据,如下图所示例,列示出了常用的30种数据源和40种目标数据。
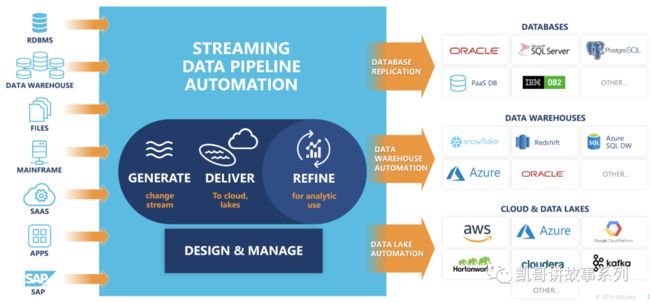
可以分解的更加细致:

可信/Trust
数据的可信包括三个层面:
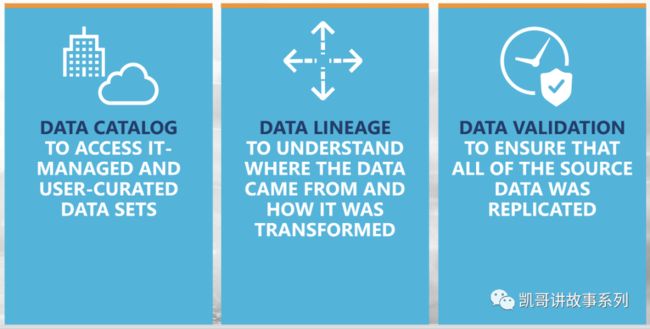
数据目录:保证数据资产和用户产生的数据集的可访问性
数据血缘:能够清晰的知道数据从哪里来的,是怎么被加工和处理的过程
数据验证:确保每一个源数据在变化的时候所有相关的数据集也被复制和更新
只有满足以上的三点要求,才能被认为数据是可信的。
自动/Automation
自动化是DataOps的重要基础能力,从数据的产生,处理到交付数据产品和服务,整个过程要尽可能的自动化处理。

典型DataOps平台架构
一个典型的DataOps平台的架构如下图[4]所示,包括八大组件功能:
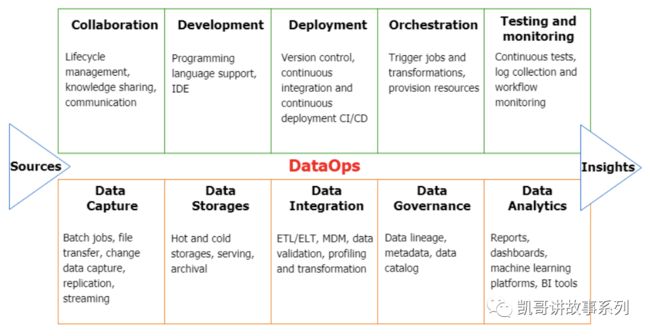
https://www.valdas.blog/2019/04/17/data-ops/
每一部分对应的常见组件和工具如下:
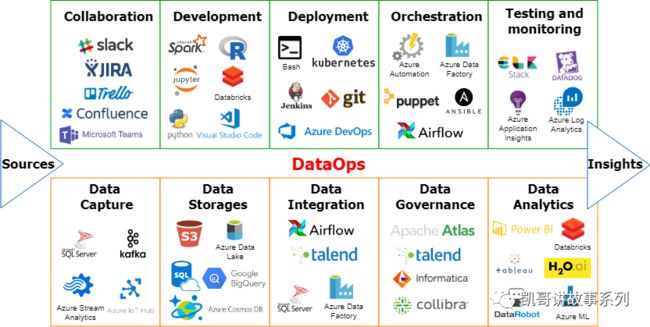
数据管理的功能
数据获取
通过批量任务,文件传输,流式处理等技术手段获取数据。常见的数据获取的工具和组件有Kafka,SQL等。
数据存储
将获取的数据以不同的类型存储起来,主要有关系型数据库,NOSQL数据库,云数据组件等。
数据集成
将不同源,不同格式,不同类型的数据进行处理从而集成整合,主要的工具有AirFlow,ETL工具等。
数据治理
数据治理平台进行数据的标准、元数据管理,数据血缘管理,数据发现和搜索,数据安全和权限等管理功能,从而保证数据的一致性,主要的工具有Atlas,Talend,Informatica等
数据分析
常见的数据分析工具很多,比如PowerBI,H2O等。
数据开发的功能
协作
DataOps的目标之一就是构建一个拉通端到端的数据开发价值链,所以构建一个高效,分布式的协作体系是DataOps很重要的组件模块。当然,这里的协作沟通工具和DevOps所使用的很多都是类似的,如Slack,Jira等。
开发
数据开放平台会有很多,一个好的DataOps平台需要能够无缝的集成这些开发环境,在不同的开发环境之间快速的集成和拉通。
部署
作为DataOps体系来说,持续部署是很重要的基础能力,能够兼容很多底层的容器和部署工具,比如Kubernate,Jenkins等
编排
将数据服务和处理节点进行灵活的编排,形成新的数据处理链,常用的工具有Puppet和Airflow等。
测试和监控
自动化测试和监控的组件是保证数据处理链质量的基础保障,常用的有Stack,DataDog等。
从DataOps到MLOps
在DataOps在不断收到关注的同时,Machine Learning Ops也在不断崛起,那么DataOps和MLOps的关系是什么呢?
DataOps的的源头是数据源系统,终点是数据产品和服务,而Machine Learning的产品也是数据服务和产品的一种,所以从这个角度来讲,DataOps是比MLOps范围更广的。
我觉得下图[5]是比较清晰的展示了DataOps和MLOps之间的关系:
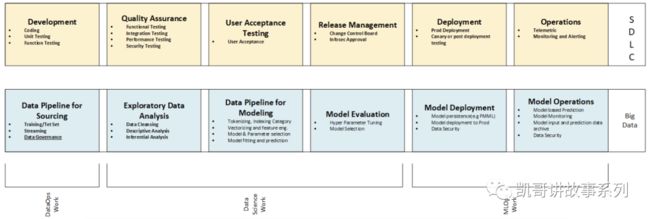
https://www.linkedin.com/pulse/get-rhythm-data-science-initiatives-dataops-mlops-ash-hassan/
可以总结为如下几点:
DataOps比MLOps价值链更长
DataOps端到端管理从数据源到数据产品的全过程,而MLOps则是从模型训练开始到模型上线结束。
DataOps是MLOps的基础能力
MLOps主要涵盖的过程如下图[6]所示:
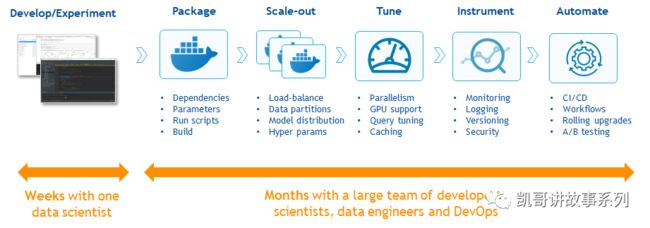
https://www.iguazio.com/blog/mlops-challenges-solutions-future-trends/
MLOps是服务于机器学习系统的,而机器学习系统与一般软件系统有如下差异[7]:
团队技能:
在机器学习项目中,团队通常包括数据科学家或机器学习研究人员,他们主要负责进行探索性数据分析、模型开发和实验。这些成员可能不是经验丰富的、能够构建生产级服务的软件工程师。
开发:
机器学习在本质上具有实验性。您应该尝试不同的特征、算法、建模技术和参数配置,以便尽快找到问题的最佳解决方案。您所面临的挑战在于跟踪哪些方案有效、哪些方案无效,并在最大程度提高代码重复使用率的同时维持可重现性。
测试:
测试机器学习系统比测试其他软件系统更复杂。除了典型的单元测试和集成测试之外,您还需要验证数据、评估经过训练的模型质量以及验证模型。
部署:
在机器学习系统中,部署不是将离线训练的机器学习模型部署为预测服务那样简单。机器学习系统可能会要求您部署多步骤流水线以自动重新训练和部署模型。此流水线会增加复杂性,并要求您自动执行部署之前由数据科学家手动执行的步骤,以训练和验证新模型。
生产:
机器学习模型的性能可能会下降,不仅是因为编码不理想,而且也因为数据资料在不断演变。换句话说,与传统的软件系统相比,模型可能会通过更多方式衰退,而您需要考虑这种降级现象。因此,您需要跟踪数据的摘要统计信息并监控模型的在线性能,以便系统在值与预期不符时发送通知或回滚。
机器学习和其他软件系统在源代码控制的持续集成、单元测试、集成测试以及软件模块或软件包的持续交付方面类似。
但是,在机器学习中,有一些显著的差异:
CI 不再仅仅测试和验证代码及组件,而且还会测试和验证数据、数据架构和模型。
CD 不再针对单个软件包或服务,而会针对应自动部署其他服务(模型预测服务)的系统(机器学习训练流水线)。
CT 是机器学习系统特有的一个新属性,它主要涉及自动重新训练和提供模型。
下图是一个典型的自动化机器学习的示意图
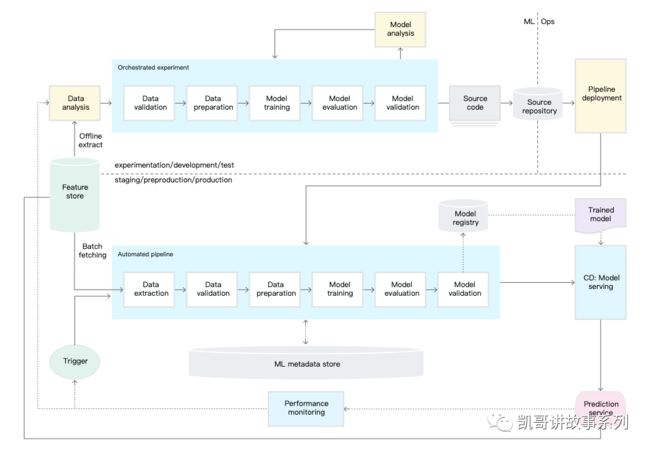
这不是本文的重点,这里就不赘述了。
总而言之,MLOps是DataOps中很重要的一部分,是DataOps团队必须构建的能力,也是支撑数据和智能项目的必备基础,DataOps已经被行业认为是数据和智能领域的主要趋势[8]。
引用
[1]https://www.ibmbigdatahub.com/blog/3-reasons-why-dataops-essential-big-data-success
[2]https://www.tamr.com/blog/from-devops-to-dataops-by-andy-palmer/
[3]https://searchdatamanagement.techtarget.com/definition/DataOps
[4]https://www.valdas.blog/2019/04/17/data-ops/
[5]https://www.linkedin.com/pulse/get-rhythm-data-science-initiatives-dataops-mlops-ash-hassan/
[6]https://www.iguazio.com/blog/mlops-challenges-solutions-future-trends/
[7]https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning?utm_campaign=Weekly%20roundup%20of%20MLOps%20and%20DataOps&utm_medium=email&utm_source=Revue%20newsletter
[8]https://www.informationweek.com/big-data/big-data-analytics/why-dataops-is-a-major-quality-trend-for-2020/a/d-id/1336483




傅一平:如何评估数据中台的成熟度?
没有中台的命,却得了中台的病
你的数据中台需要做一个成熟度评估了
“上中台吗?会送命的那种!”
中台搞了2年,项目叫停,CIO被裁!本以为中台是道送分题,没想到是送命题!
中台的问题,是技术的问题,还是人的问题
有赞数据中台建设实践
漫画:什么是中台?
你需要的不是中台,而是一名合格的架构师(附各大厂中台建设PPT)
不做中台当然会死!
数据中台应该包含什么?
中台的末路
浙江移动数据中台的建设和应用实践
不做中台会死吗?
OPPO数据中台之基石:基于Flink SQL构建实数据仓库
数据中台已成下一风口,它会颠覆数据工程师的工作吗?
数据中台不是技术平台,没有标准架构!
超越平台,数据中台的业务化、服务化及开放化!
读透《阿里巴巴数据中台实践》,其到底有什么高明之处?
什么才是运营商数据中台最大的竞争力?
为什么企业要从离线数据中台走向实时数据中台?
艰难的旅程,你的数据中台到底能为一线提供多少火力?
如何清晰的实施“大中台,小前台” 大数据运营策略?
数据中台到底是什么?
企业的数据中台的价值
艰难的抉择,阿里“小前台、大中台”的解读