Sharding-JDBC是当当开源的分库分表中间件,通过重写jdbc api的方式为Java应用提供分库分表的能力,在官方项目首页有很多使用说明,相比较其他的分库分表开源产品,文档算是维护的比较好的一个项目,而且开发者也一直在维护更新,并和社区保持着积极的沟通。
sharding-jdbc的整体架构图如下:
基本上分库分表中间件都要实现如图中的这些功能:规则配置、SQL解析、SQL改写、SQL路由、SQL执行、结果集合并。下面让我们深入到sharding-jdbc的源码中去,粗略地看一下这些功能在代码中是如何实现的。
在github上下载sharding-jdbc的源码后,需要在IDE中添加对Lombok的支持,因为项目中大量地使用了Lombok的注解,以减少项目代码量。在sharding-jdbc中有个大量示例的子项目sharding-jdbc-example,以sharding-jdbc-example-jdbc为突破口,先执行resources中的all_schema.sql文件建好所需要的分表,然后执行Main类中的示例查询。
规则配置
sharding-jdbc的规则配置稍显复杂,规则配置的目的是为了能够得到ShardingDataSource对象,即包含有分片信息和物理数据源的分片数据源对象,而ShardingDataSource是继承标准的JDBC的DataSource接口的。物理数据源是真正执行sql的地方,每个物理数据源连接实际的database,在构建物理数据源的过程中,可以使用数据库连接池技术提升性能,比如常用的出c3p0、druid,而示例用的是dbcp。
private static ShardingDataSource getShardingDataSource() {
DataSourceRule dataSourceRule = new DataSourceRule(createDataSourceMap());
TableRule orderTableRule = TableRule.builder("t_order").actualTables(Arrays.asList("t_order_0", "t_order_1")).dataSourceRule(dataSourceRule).build();
TableRule orderItemTableRule = TableRule.builder("t_order_item").actualTables(Arrays.asList("t_order_item_0", "t_order_item_1")).dataSourceRule(dataSourceRule).build();
ShardingRule shardingRule = ShardingRule.builder().dataSourceRule(dataSourceRule).tableRules(Arrays.asList(orderTableRule, orderItemTableRule))
.bindingTableRules(Collections.singletonList(new BindingTableRule(Arrays.asList(orderTableRule, orderItemTableRule))))
.databaseShardingStrategy(new DatabaseShardingStrategy("user_id", new ModuloDatabaseShardingAlgorithm()))
.tableShardingStrategy(new TableShardingStrategy("order_id", new ModuloTableShardingAlgorithm())).build();
return new ShardingDataSource(shardingRule);
}
private static Map createDataSourceMap() {
Map result = new HashMap<>(2);
result.put("ds_0", createDataSource("ds_0"));
result.put("ds_1", createDataSource("ds_1"));
return result;
}
private static DataSource createDataSource(final String dataSourceName) {
BasicDataSource result = new BasicDataSource();
result.setDriverClassName(com.mysql.jdbc.Driver.class.getName());
result.setUrl(String.format("jdbc:mysql://localhost:3306/%s", dataSourceName));
result.setUsername("root");
result.setPassword("");
return result;
}
获取数据源之后,就是执行SQL语句,然后获得结果集,这个和以往正常的通过jdbc api连接数据库并获取数据的流程并无实质性差别,唯一区别的是这里的每个接口的实现类都是Sharding的,比如printGroupBy执行的统计用户订单量的示例。
private static void printGroupBy(final DataSource dataSource) throws SQLException {
String sql = "SELECT o.user_id, COUNT(*) FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id GROUP BY o.user_id";
try (
Connection conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql)
) {
ResultSet rs = preparedStatement.executeQuery();
while (rs.next()) {
System.out.println("user_id: " + rs.getInt(1) + ", count: " + rs.getInt(2));
}
}
}
关键的ShardingContext
在执行dataSource.getConnection()之后获取到了shardingConnection,shardingConnection是一种逻辑意义上的分布式数据库的连接,其中最重要的成员变量当属shardingContext,即数据源运行时的上下文信息,包括了shardingRule(分片规则)、sqlRouteEngine(数据路由引擎,得出最终可执行的SQL语句)、executorEngine(执行引擎,通过多线程的方式并行执行多路SQL),之后的一系列的操作都离不开这个shardingContext,对于能够正确解析SQL并执行正确非常关键,可以认为是整个中间件执行的核心。
/**
* 数据源运行期上下文.
*
* @author gaohongtao
*/
@RequiredArgsConstructor
@Getter
public final class ShardingContext {
private final ShardingRule shardingRule;
private final SQLRouteEngine sqlRouteEngine;
private final ExecutorEngine executorEngine;
}
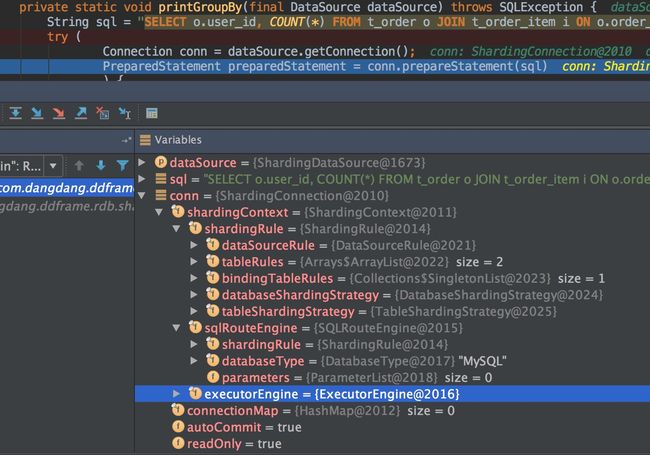
获取shardingConnection之后,通过conn.prepareStatement(sql)获取ShardingPreparedStatement,之后调用executeQuery()方法开始执行分布式的查询操作,包括SQL解析、改写、路由、执行和合并。
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet rs;
try {
rs = ResultSetFactory.getResultSet(
new PreparedStatementExecutor(getShardingConnection().getShardingContext().getExecutorEngine(), routeSQL()).executeQuery(), getMergeContext());
} finally {
clearRouteContext();
}
setCurrentResultSet(rs);
return rs;
}
private List routeSQL() throws SQLException {
List SQL解析、路由和改写
这个过程是SQL处理的重要步骤,原始的逻辑上的SQL,需要转换成实际可以执行的SQL,比如替换成正确的库名、表名,对于需要统计合并类的操作,可能一条逻辑SQL会对应多条物理SQL。
/**
* 使用参数进行SQL路由.
* 当第一次路由时进行SQL解析,之后的路由复用第一次的解析结果.
*
* @param parameters SQL中的参数
* @return 路由结果
*/
public SQLRouteResult route(final ListSQL Parse的过程主要是解析SQL获得抽象语法树(AST),这个过程本质上和参数是无关的,只是把SQL拆解成一个个token的过程,传递参数的目的主要用在改写和路由,比如根据参数把原来的t_order路由到t_order_0和t_order_1。SQL Parse的结果理论上是可以缓存起来的,虽然这里似乎通过if (null == sqlParsedResult)来复用了解析的结果,但其实由于该方法所在类PreparedSQLRouter每次都会重新创建,并没有真正意义上的缓存利用起来,只有在复用ShardingPreparedStatement的情况下才会复用sqlParsedResult(参考https://github.com/dangdangdotcom/sharding-jdbc/issues/156). 路由和改写并不是两个割裂的过程,而是在路由的同时,就知道该向哪个分库或分表执行SQL,同时就改写相应的SQL。
执行与合并
在SQL路由之后最终得到的结果是封装了可执行的物理PrepareStatement的集,并由preparedStatementExecutorWrappers来包装,如果只有一个物理prepareStatement,直接执行executeQuery获取结果集即可,如果有多个物理prepareStatement,框架就会借助多线程执行每个查询,最后合并。
/**
* 执行SQL查询.
*
* @return 结果集列表
*/
public List executeQuery() {
Context context = MetricsContext.start("ShardingPreparedStatement-executeQuery");
eventPostman.postExecutionEvents();
List result;
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
final Map dataMap = ExecutorDataMap.getDataMap();
try {
if (1 == preparedStatementExecutorWrappers.size()) {
//直接执行一条SQL
return Collections.singletonList(executeQueryInternal(preparedStatementExecutorWrappers.iterator().next(), isExceptionThrown, dataMap));
}
//多线程框架下执行
result = executorEngine.execute(preparedStatementExecutorWrappers, new ExecuteUnit() {
@Override
public ResultSet execute(final PreparedStatementExecutorWrapper input) throws Exception {
synchronized (input.getPreparedStatement().getConnection()) {
return executeQueryInternal(input, isExceptionThrown, dataMap);
}
}
});
} finally {
MetricsContext.stop(context);
}
return result;
}
整体上sharding-jdbc就是分这几部分来实现分库分表的功能的,框架内部做了很多事情,应用方要做的就是接入依赖,然后通过代码或配置写清楚分库分表的规则,即可像正常模式一样使用分布式数据库。