使用python爬取电影上映前后两个月的百度指数
使用python爬取电影上映前后两个月的百度指数
https://blog.csdn.net/hcbbbb/article/details/82380418
本文参考了Github上的TerenceLiu2/BaiduIndexCrawl项目,进行适当的改进,使之适用于个人的需要。
本文主要是从excel表格中读取电影的名称以及上映日期,并在百度指数上进行搜索,然后选定指定的上映前后两个月的日期,并将这60天每一天的百度指数数值通过截图的方式截取下来,最后将图片进行识别即可。
本次主要只将图片截取保存下来,识别的话可以使用免费开源的pytesseract,识别度不会特别的高,当然也可以使用网上很多的图像识别系统,个人推荐可以使用百度的AI开放平台 (笑 ,数据量不是很大的话,注册认证之后有一定的免费额度可以使用。
目录
- 使用python爬取电影上映前后两个月的百度指数
- 目录
- 前期准备
- python
- selenium
- 进入正文
- 初始数据
- 读取数据
- 对读取的数据进行处理
- 计算需要选择的日期——电影上映前后一个月
- 利用selenium进行百度指数的登录
- 进行电影上映前后两个月的百度指数截取
- 输入数据
- 对抗反爬机制
- 自动移动鼠标进行每一日百度指数的选取
- 对每一天的百度指数进行图像的截取
- 进行viewbox的监测
- 得到的文件
- 写在最后
前期准备
注意:本文使用的是python2.7编写的编码。
python
本文安装的为anaconda2.7,anaconda里面有python以及python很多基础的包以及与数据科学相关的包,推荐可以直接安装使用。安装的其他问题请自行百度。
selenium
安装可以查看这篇博客:Python爬虫环境常用库安装(看第四点哦)
基本用法可以查看这篇博客:selenium用法详解
进入正文
初始数据
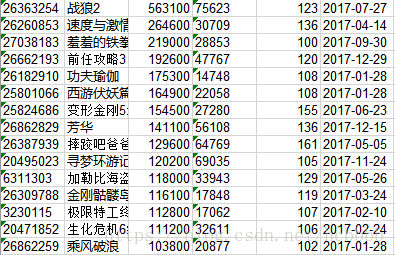
使用到的数据截图如下,数据来源于豆瓣电影与猫眼网,列对应属性为豆瓣ID,电影名称,票房,想看人数,时长,上映日期。
读取数据
利用xlrd读取excel中的数据。
XmlPath = "data/2016.xls" # 数据路径
rbook = xlrd.open_workbook(XmlPath) # 读取数据
rsheet = rbook.sheet_by_index(0)
id = rsheet.col_values(0) # 第一列数据,id
keywords = rsheet.col_values(1) # 第二列数据,电影名称
releases = rsheet.col_values(5) # 第六列数据,上映日期
ticot = 0 # 从第0行开始读取对读取的数据进行处理
将第 i 行的数据进行处理,返回第i行数据的电影名称,上映年,月,日。
def load_req(i, keywords, releases):
if keywords != "":
name = keywords[i]
day = releases[i].split('-')[2]
month = releases[i].split('-')[1]
year = releases[i].split('-')[0]
print "正在获取", name.encode("utf-8"), "的百度指数"
return [name, year, month, day]
else:
return False计算需要选择的日期——电影上映前后一个月
#月份-日字典
Monthdict = {'01': 31, '02': 28, '03': 31, '04': 30, '05': 31, '06': 30, '07': 31, '08': 31, '09': 30, '10': 31,'11': 30, '12': 31}
def CalculateDate(year, month):
if year == '2010':
fyear = 2011
fmonth = '01'
else:
fyear = year
if int(month) == 1:
fmonth = '12'
fyear = str(int(year) - 1)
else:
fmonth = str(int(month) - 1)
if len(fmonth) < 2:
fmonth = '0' + fmonth
if year == '2010':
ayear = 2011
amonth = '03'
else:
ayear = year
if int(month) + 1 == 13:
amonth = '01'
ayear = str(int(year) + 1)
else:
amonth = str(int(month) + 1)
if len(amonth) < 2:
amonth = '0' + amonth
return fyear, fmonth, ayear, amonth利用selenium进行百度指数的登录
利用selenium进行半自动的登录,第一次登录自己输入账号密码然后进行下一步操作,之后可以将登录后的cookies进行保存,然后后续可以直接利用cookies进行登录。
url = "http://index.baidu.com/" # 百度指数网站
chromePath = r'../chromedriver.exe' # Chromedriver的路径
browser = webdriver.Chrome(executable_path=chromePath) # 打开浏览器
browser.get(url) # 打开网站
# 第一次登录,将这两行取消注释,后三行进行注释
a = raw_input() # 手动登录之后,在程序中按回车继续程序
pickle.dump(browser.get_cookies(), open("cookies.pkl", 'wb')) # 保存登录的cookies
# 利用cookies进行登录,将这三行取消注释,前两行进行注释
# cookies = pickle.load(open("cookies.pkl", "rb")) # 读取之前登录的cookies
# for cookie in cookies: # 利用cookies进行登录
# browser.add_cookie(cookie)
status = browser # 检测浏览器状态,是否成功
b = raw_input() # 在百度指数搜索框中输入任意字符然后进行搜索,然后在程序中按回车继续程序手动登录之后在程序中按回车继续程序
任意字符进行搜索之后在程序中按回车继续程序
进行电影上映前后两个月的百度指数截取
在浏览器中自动输入电影名称,选择起止日期,进行电影百度指数的截取。这个部分比较复杂,分为好几个函数,请仔细观察理解。其中,exec_spider函数用于将数据自动输入到网页中,CollectIndex函数用于准确寻找到上映前后两个月60天每一天百度指数的位置,自动将指针放到该位置上,这是每一天的百度指数都会出现一个viewbox,即一个小框。GetTheCode函数主要将图片截取下来,然后进行有用部分的截取和处理。
主要流程 exec_spider -> CollectIndex -> GetTheCode
输入数据
def exec_spider(request):
try:
name = request[0]
year = request[1]
month = request[2]
day = request[3]
# 清空网页输入框
try:
browser.find_element_by_id("schword").clear()
# 写入需要搜索的百度指数
browser.find_element_by_id("schword").send_keys(name)
except:
browser.find_elements_by_id("search-input-word").clear()
# 写入需要搜索的百度指数
browser.find_element_by_id("search-input-word").send_keys(name)
# 点击搜索
try:
browser.find_element_by_id("searchWords").click()
except:
browser.find_element_by_id("schsubmit").click()
# 计算电影上映前后两个月日期
fyear, fmonth, ayear, amonth = CalculateDate(year, month)
# 点击网页上的开始日期
if str(fyear) == "2010":
return False
browser.maximize_window()
time.sleep(1)
browser.find_elements_by_xpath("//div[@class='box-toolbar']/a")[6].click()
time.sleep(0.05)
browser.find_elements_by_xpath("//span[@class='selectA yearA']")[0].click()
time.sleep(0.05)
browser.find_element_by_xpath(
"//span[@class='selectA yearA slided']//div//a[@href='#" + str(fyear) + "']").click()
time.sleep(0.05)
browser.find_elements_by_xpath("//span[@class='selectA monthA']")[0].click()
time.sleep(0.05)
browser.find_element_by_xpath(
"//span[@class='selectA monthA slided']//ul//li//a[@href='#" + str(fmonth) + "']").click()
# 选择网页上的截止日期
time.sleep(0.05)
browser.find_elements_by_xpath("//span[@class='selectA yearA']")[1].click()
time.sleep(0.05)
browser.find_element_by_xpath(
"//span[@class='selectA yearA slided']//div//a[@href='#" + str(ayear) + "']").click()
time.sleep(0.05)
browser.find_elements_by_xpath("//span[@class='selectA monthA']")[1].click()
time.sleep(0.05)
browser.find_element_by_xpath(
"//span[@class='selectA monthA slided']//ul//li//a[@href='#" + str(amonth) + "']").click()
time.sleep(0.5)
browser.find_element_by_xpath("//input[@value='确定']").click()
time.sleep(0.5)
# 闰年处理
if int(year) == 2012 or int(year) == 2016:
Monthdict['02'] = 29
# 进行截图
return CollectIndex(browser, fyear, fmonth, day, name)
# 异常处理
except IndexError, e:
if Anti_Exist(browser) is True: # 对抗反爬机制
print 'wait'
time.sleep(100)
return exec_spider(request)
else:
return False
except StaleElementReferenceException, e2:
print 'wait'
time.sleep(100)
return exec_spider(request)
except:
return exec_spider(request)对抗反爬机制
# 对抗反爬机制
def Anti_Exist(browser):
try:
browser.find_element_by_xpath("//img[@src='/static/imgs/deny.png']")
return True
except:
return False自动移动鼠标进行每一日百度指数的选取
def CollectIndex(browser, fyear, fmonth, day, name):
# 初始化输出String
OutputString = '['
x_0 = 1
y_0 = 1
# 根据起始具体日子计算鼠标的初始位置
# 一日=13.51 例如,上映日期为7.20日 则x起始坐标为1+13.41*19
if str(fyear) != '2011':
ran = Monthdict[fmonth] + int(day) - 32
if ran < 0:
ran = 0.5
x_0 = x_0 + 13.51 * ran
else:
day = 1
xoyelement = browser.find_elements_by_css_selector("#trend rect")[2]
ActionChains(browser).move_to_element_with_offset(xoyelement, x_0, y_0).perform()
for i in range(61):
# 计算当前得到指数的时间
if int(fmonth) < 10:
fmonth = '0' + str(int(fmonth))
if int(day) >= Monthdict[str(fmonth)] + 1:
day = 1
fmonth = int(fmonth) + 1
if fmonth == 13:
fyear = int(fyear) + 1
fmonth = 1
day = int(day) + 1
time.sleep(0.5)
# 获取Code
code = GetTheCode(browser, fyear, fmonth, day, name, path, xoyelement, x_0, y_0)
# ViewBox不出现的循环
cot = 0
jud = True
# print code
while (code == None):
cot += 1
code = GetTheCode(browser, fyear, fmonth, day, name, path, xoyelement, x_0, y_0)
if cot >= 3:
jud = False
break
if jud:
anwserCode = code.group()
else:
anwserCode = str(-1)
if int(day) < 10:
day = '0' + str(int(day))
if int(fmonth) < 10:
fmonth = '0' + str(int(fmonth))
OutputString += str(fyear) + '-' + str(fmonth) + '-' + str(day) + ':' + str(anwserCode) + ','
x_0 = x_0 + 13.51
#print anwserCode
OutputString += ']'
#print OutputString
return OutputString.decode('utf-8')对每一天的百度指数进行图像的截取
# 图片保存路径
path = os.getcwd()
def GetTheCode(browser, fyear, fmonth, day, name, path, xoyelement, x_0, y_0):
ActionChains(browser).move_to_element_with_offset(xoyelement, x_0, y_0).perform()
# 鼠标重复操作直到ViewBox出现
cot = 0
while (ExistBox(browser) == False):
cot += 1
ActionChains(browser).move_to_element_with_offset(xoyelement, x_0, y_0).perform()
if ExistBox(browser) == True:
break
if cot == 6:
return None
imgelement = browser.find_element_by_xpath('//div[@id="viewbox"]')
locations = imgelement.location
printString = str(fyear) + "-" + str(fmonth) + "-" + str(day)
# 找到图片位置
# 可以自己酌情更改
l = len(name)
if l > 8:
l = 8
rangle = (int(int(locations['x'])) + l * 10 + 35, int(int(locations['y'])) + 33,
int(int(locations['x'])) + l * 10 + 35 + 75,
int(int(locations['y'])) + 51)
# 保存整个画面的截图
browser.save_screenshot(str(path) + "/raw/" + printString + ".png")
img = Image.open(str(path) + "/raw/" + printString + ".png")
if locations['x'] != 0.0:
# 按Rangle截取数据的图片
jpg = img.crop(rangle)
imgpath = str(path) + "/crop/" + printString + ".jpg"
r, g, b, a = jpg.split()
jpg = Image.merge("RGB", (r, g, b))
jpg.save(imgpath)
jpgzoom = Image.open(str(imgpath))
# 图片处理
out = jpgzoom.convert('L')
out = out.point(initTable(), '1')
out = out.convert('L')
out = ImageOps.invert(out)
out = out.convert('1')
out = out.convert('L')
(x, y) = jpgzoom.size
x_s = x * 10
y_s = y * 10
out = out.resize((x_s, y_s), Image.ANTIALIAS)
# 按电影id对截图进行分类,
movpath = path + '/2016/' + '{}/'.format(id[ticot])
folder = os.path.exists(movpath)
if not folder:
os.makedirs(movpath)
out.save(movpath + printString + ".jpg", 'jpeg', quality=95)
return 'save'
else:
return None进行viewbox的监测
# 进行viewbox的监测
def ExistBox(browser):
try:
browser.find_element_by_xpath('//div[@id="viewbox"]')
return True
except:
return False
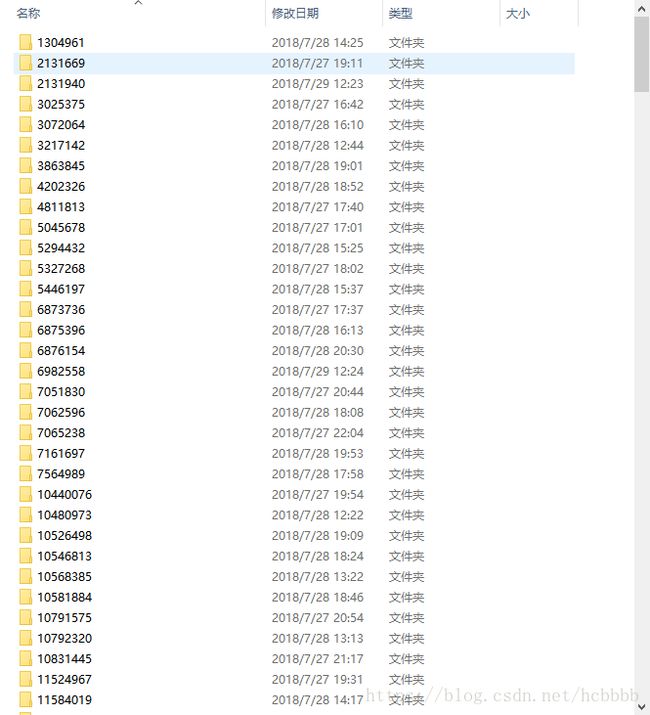
得到的文件
电影对应id的文件夹
某个文件夹里的图片,有一些空白可能是没抓到(哭,不过后面可以处理一下,取个平均感觉应该差不多
写在最后
emmmmm,这是本人第一篇的博客,有挺多的感触。
本人一名在校生,因学业上需要在github上找到了这个项目TerenceLiu2/BaiduIndexCrawl,稍加修改了一下便拿来用了,(感谢原作者的无私奉献!) 在看懂了代码之后,觉得这个思路挺好,便有了想要记录下来的想法,便有了这一篇的博客,第一次写博客,一些不好的地方请原谅,也希望看这一篇博客的同志们可以好好的看完(毕竟我也是马马虎虎的看了好多文章,哈哈哈),个人感觉不是很难,懂得python基础和一些爬虫基础的人应该能顺利的看下去。也欢迎大家与我交流,可以留言或者私信哦,我应该会看的吧(大误
源代码我会放到:这里
以后估计也会在这里记录一些其他的东西吧。
更新于 2018 / 9 / 4
未经允许禁止转载https://blog.csdn.net/hcbbbb/article/details/82380418