DSO 中的Windowed Optimization
该博客内容发表在泡泡机器人公众号上,请尊重泡泡机器人公众号的版权声明
DSO中除了完善直接法估计位姿的误差模型外(加入了仿射亮度变换,光度标定,depth优化),另一个核心就是像okvis一样使用sliding window来优化位姿,Engel也专门用了一节来介绍它。sliding window 就像c++中的队列,队首进来一个新人,队尾出去一个老人,它更像王朝中武将的新老交替,老将解甲归田,新人受window大王的重用,然而安抚老将不得当,会使得SLAM王朝土崩瓦解。对于初次接触sliding window的初学者来说,window大王安抚老将,振兴SLAM王朝的三件法宝“First Estimate Jacobians”,“Marginalization”,“Schur complement”实在让人有点摸不清头脑。原谅我的口水话,接下来我将用尽量直观简洁的方式进行描述。
在此之前,泡泡群里王京和张腾在知乎写过First Estimate Jacobians的回答,范帝楷也在《OKVIS的理论推导(下)》中对marginalization进行了描述,这些都可以在泡泡历史推文中找到,我也写过一篇《SLAM中的marginalization 和 Schur complement》的博客。虽然资料已经很全了,这里还是想结合DSO[1],以及另一篇文献[2]对windowed optimization涉及到的知识点进行一个全面的讲解。
本文将包括如下三个方面:
1. 为什么要使用sliding window ?
2. 什么是sliding window? Marginalization, Schur Complement, First Estimate Jacobians
3. DSO中是如何使用windowed optimization的?
为什么要使用sliding window?
在基于图优化的SLAM技术中,无论是pose graph还是bundle adjustment都是通过最小化损失函数来达到优化位姿和地图的目的。然而,当待优化的位姿或特征点坐标增多时,优化过程的计算量也随着增大。因此不能无限制的添加待优化的变量,而是使用滑动窗口技术来限制计算量在一定范围。比如,一开始有三个关键帧 kf1,kf2,kf3 在窗口里,经过时间t,第四个关键帧 kf4 加入优化,此时我们需要去掉 kf1 ,只对关键帧 kf2,kf3,kf4 进行优化。这样就始终保持待优化变量的个数,而固定了计算量。在上面的过程中,新的关键帧到来时,我们直接丢弃了关键帧1和关键帧2,3之间的约束,直接只用新的关键帧4和2,3构建的约束来对帧2,3,4的位姿进行新的优化,因此一个很自然的问题是,优化后的 kf2,kf3 的位姿和原来 kf1 的约束肯定就被破坏了,原来 kf1 的一些约束信息就被损失了。那么,我们如何做到即使用滑动窗口固定计算量又充分保留信息呢?因此下面我们要对sliding window进行一个彻底的分析。额,感觉有点水深,像一个坑,别急,喝口水,后面不是一个坑是一个湖在等你。
sliding window技术
在这部分,我们从基本的graph based slam出发,逐步分析当新的优化变量加入时,如何优雅的去掉旧变量,在固定计算量的同时又保留信息并且不破坏系统的一致性。
我们知道图优化SLAM问题中两个顶点之间的边有如下的形式:
Marginalization和Schur Complement
假设要marginalize掉的变量为 xm , 和这些待丢弃变量有约束关系的变量用 xb 表示,窗口中其他变量为 xr ,即 x=[xm,xb,xr]T 。相应的测量值为 z={zb,zr}={zm,zc,zr} ,其中 zb={zm,zc} 。为了有助于理解,看下图所示

现在,需要丢掉变量 xm ,而去优化 xb,xr 。为了不丢失信息,正确的做法是把 xm,xb 之间的约束 zm 封存成状态 xb 的先验信息,简单地说就是告诉 xr ,我和 xb 之前是有约定的,你不能只按照你的约定胡来。封存先验信息就是如下公式,在 zm 条件下 xb 的概率:
为了求解 (x^b,Λ−1t) ,我们只需要求解
First Estimate Jacobians
在marg的时候,我们需要不断迭代计算H矩阵和残差b,而迭代过程中,状态变量会被不断更新,计算雅克比时我们要fix the linearization point。也就是计算雅克比时求导变量要固定,而不是用每次迭代更新以后的x去求雅克比,这就是所谓的用第一次得到的雅克比(First Estimate Jacobians)。在之前介绍的泡泡机器人的推文或我的博文中都已经直观的介绍了这里面的原理,在这里我们将采用更理论的方式来进行分析。
假设之前求最小二乘的损失函数可以表达成:
现在我们把损失函数 cm(xm,xb) 去掉了 xm 得到了无信息损失的近似函数公式(5), 那我们把公式(5)代入公式:
如果有了这个概念,我们再回到DSO的论文中,就不难理解论文中的公式了。
DSO中的windowed optimization
在DSO论文的2.3节,在进行窗口优化Gauss-Newton迭代的时候,作者特意强调要使用First Estimate Jacobians技术。作者将优化前的状态定义为 ζ0 ,高斯牛顿迭代过程的总的累计量定义为 x ,高斯牛顿迭代中每一步得到的增量 δ 。作者用了下面一个图来讲解这些变量的关系:
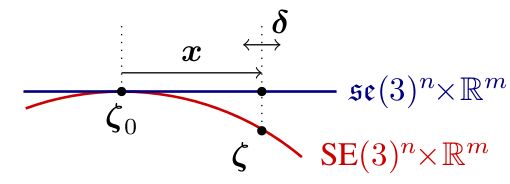
我们可以看到在优化过程中有:
扩展
上面只是理论的一些推导,在实际应用中还要考虑稀疏矩阵H会变得稠密。仔细想一想,我们在marg的过程中,要去掉变量还要保留他的信息,把以前一个大的H矩阵丢掉一些维度压缩到一个小的H矩阵里,不可避免的就会使得原本稀疏的H矩阵变得稠密,这就是所谓的fill-in。DSO,OKVIS的作者在使用的时候都使用了一些策略那尽量维持稀疏性,在上面提到的我的另一篇博文中有详细介绍,这里不再赘述。
(转载请注明作者和出处:http://blog.csdn.net/heyijia0327 未经允许请勿用于商业用途)
【版权声明】泡泡机器人SLAM的所有文章全部由泡泡机器人的成员花费大量心血制作而成的原创内容,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能否进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
【注】商业转载请联系刘富强([email protected])进行授权。普通个人转载,请保留版权声明,并且在文章下方放上“泡泡机器人SLAM”微信公众账号的二维码即可。
ref:
[1] 《Direct Sparse Odometry》
[2] 《Decoupled, Consistent Node Removal and Edge Sparsification for Graph-based SLAM》