【Python学习笔记】——特征工程
目 录
- 1 特征工程
- 1.1 什么是特征工程
- 1.2 为什么特征工程很重要
- 1.2.1 增加了模型选择的灵活性
- 1.2.2 使参数优化变得简单
- 1.2.3 得到更好的结果
- 1.3 特征工程在机器学习中的步骤
- 1.4 怎样做特征工程
- 1.5 特征工程实例
- 1.5.1 Predicting Student Test Performance in KDD Cup 2010
- 1.5.2 Predicting Patient Admittance in the Heritage Health Prize
- 2 特征
- 3 特征重要性
- 4 特征提取(Feature Extraction)
- 5 特征构造(Feature Construction)
- 6 特征选择(Feature Selection)
- 6.1 什么是特征选择
- 6.2 特征选择的方法
- 6.2.1 理论方法
- 6.2.1.1 Filter方法
- 6.2.1.2 Wrapper方法
- 6.2.1.3 Embeded方法
- 6.2.2 工程方法
- 6.2.1 理论方法
- 6.3 实例
- 6.4 总结
- 7 特征学习(Feature Learning)
- 8 学习资源
参考:https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
特征工程
什么是特征工程
“feature engineering is another topic which doesn’t seem to merit any review papers or books, or even chapters in books, but it is absolutely vital to ML success. […] Much of the success of machine learning is actually success in engineering features that a learner can understand.”
— Scott Locklin, in “Neglected machine learning ideas”
在机器学习中,特征工程并不能算作是一个热点话题,甚至很少有一本机器学习的教材专门拿出一个章节来讲特征工程,但是它对于机器学习来说是至关重要的。在众多的机器学习模型中算法多么高深未必能取得好的结果,而获得高分的模型往往在特征工程上都做的更加出色。因为我们面对的数据并不像书中的数据那样完美的适合一个模型。我们需要从数据中得到更有用、更全面、更干净的信息。数据决定了学习的上限,而算法不过是不断地逼近这个上限。
有很多因素可以影响学习的结果:模型的选择(LR?SVM?)、可获得的数据(samples? formatting? cleaning?)、特征的选择、对问题的理解(classification? regression?)以及评估的标准(RMSE? AUC?)等等。对于一个预测问题,我们想要得到最好的结果,这包括在模型中学得最好的结果,也包括获取用来训练模型的最好的数据,后面的工作就是特征工程。严格来说,特征工程就是从原始数据中获得能够更好的还原问题到可预测模型,并且在测试集上提高模型精度的特征。还原到程序中,特征工程就是如何来构建我们训练所要的 X X X 。
“feature engineering is manually designing what the input x’s should be”
— Tomasz Malisiewicz, answer to “What is feature engineering?”
特征工程要解决的是如何把一个实际问题转化为可以进行建模的数据
“you have to turn your inputs into things the algorithm can understand”
— Shayne Miel, answer to “What is the intuitive explanation of feature engineering in machine learning?”
特征工程要实现的是为建模提供最好的数据
“…some machine learning projects succeed and some fail. What makes the difference? Easily the most important factor is the features used.”
— Pedro Domingos, in “A Few Useful Things to Know about Machine Learning”
为什么特征工程很重要
“Actually the success of all Machine Learning algorithms depends on how you present the data.”
— Mohammad Pezeshki, answer to “What are some general tips on feature selection and engineering that every data scientist should know?”
虽然已经说明了特征工程是很重要的,那么它重要在哪里,为什么如此重要呢?
增加了模型选择的灵活性
更好的特征意味着我们在模型选择上有更多的余地,即使不是最优模型仍能获得好的结果,基于此,我们可以选择更简单、更快速、更易于维护的模型
使参数优化变得简单
更好的特征意味着我们不必去追求最优的参数,即使不是最优的参数也能获得较好的结果。好的特征使得我们更加接近真实问题,更好的描述现有的数据。
得到更好的结果
“The algorithms we used are very standard for Kagglers. […] We spent most of our efforts in feature engineering.”
— Xavier Conort, on “Q&A with Xavier Conort” on winning the Flight Quest challenge on Kaggle
特征工程在机器学习中的步骤
先来看一下一般特征工程具体是在哪个步骤做呢?
一个普通的机器学习过程是这样的一个过程:
-
(Task before here):一般是问题分析和定义
-
选择数据(Select Data): 整合数据,将数据去标准化成一个数据集,收集到一起.
-
数据预处理(Preprocess Data): 数据格式化,数据清理,采样等。
-
数据转换(Transform Data): 这个阶段做特征工程。
-
数据建模(Model Data): 建立模型,评估模型并逐步优化。
-
(Tasks after here…):一般是结果展示
然而前面这个过程不应该是一个流水式的过程,而应该是不断反复的。在整个过程中的任何时刻我们都可能挖掘出新的观点或者模型的不足,我们需要不断的设计特征、选择特征、建立模型、评估模型,然后才能得到最终的model。比如对于加和的时间特征,我们不知道是按周、按月或是按季度去求和,这需要我们建模来确认。再比如数据预处理的过程,有时候我们选择的模型要求的是数值型变量,而有时因子变量也可以,有时需要做标准化,有时又不需要。所以说机器学习的过程是前后关联,互动性很强的过程。
怎样做特征工程
-
头脑风暴:分析问题、观察数据、在其它问题上学习一下特征工程看看能否从中得到灵感;
-
设计特征:根据你的问题,你可以使用自动地特征提取,或者是手工构造特征,或者两者混合使用;
-
选择特征:使用不同的特征重要性评分和特征选择方法进行特征选择,得到一些你认为适合进行学习的特征子集;
-
评估模型:使用你选择的特征进行建模,同时使用未知的数据(验证集或者测试集)来评估你的模型精度。
你需要一个定义好的问题来决定你什么时候停止这个流程来尝试其他的模型、参数和集成方法。渐渐地在整个过程的后半段才能确定你的想法并且得到稳定的提高。同时你也需要一个仔细考虑和设计的测试工具来评估模型在未知数据上的表现(比如Kaggle的Submit)。即使得到了不好的结果也一定不要在过程中怀疑做这些是在浪费时间。
特征工程实例
Predicting Student Test Performance in KDD Cup 2010
2010年KDD比赛的冠军把他们的方法发表在“Feature Engineering and Classifier Ensemble for KDD Cup 2010”.。他们把自己的成功归功于特征工程。事实上,他们仅仅以线性模型为主,进行了一些集成。他们通过创造上百万个二分类的特征简化了模型。通过这篇文章我们可以学习到一些他们做特征工程的想法和技巧。
Predicting Patient Admittance in the Heritage Health Prize
他们的论文在“Round 1 Milestone Prize: How We Did It – Team Market Makers”
特征
对于这个概念想必大家都非常熟悉,对于最常接触的表格数据,有人可能认为每一列就是一个特征,确实也可以这样说,因为我们学习中遇到的数据大部分都是处理过的格式化的数据,但在工程中我们拿到的原始数据并不是这么友好。为了与特征进行区分,我们称原始数据的列为属性(attribute),而经过加工的数据列称为特征。对比属性,特征对于问题来说应该是有实际意义的,而不应该是毫无解释性的数据,哪怕它对结果影响非常大(当然一般这样的变量一定是可以解释的)。比如在CV中,图片是我们的observation(raw data),那么一个特征可以是他的一条线;在NLP中,一段文本是我们的observation,那么一个短语或者单词可能是它的特征。
特征重要性
我们可以通过打分的方式来评定一个特征的重要性,进而对特征进行排序,作为我们特征选择的标准。此外,特征重要性也能为特征提取和特征构造提供参考,比如那些与已经进入特征子集的特征相似的但是没有被选择的特征。那些与响应变量相关性较高的特征往往更重要。
一些复杂的模型算法甚至可以在学习的过程中完成特征重要性的评估并进行特征选择。比如MARS,Random Forest和Gradient Boosted Machines。并且打印出特征的重要性。
特征提取(Feature Extraction)
特征提取的对象是原始数据(raw data),我们面对的数据可能是图像,音频,文本,也有可能是含有百万级以上的属性的表格数据。显然这些属性是不能直接拿来训练模型的。而特征提取就是用来解决这个问题的,特征提取能自动地把数据降维到能够进行建模的量级,将原始属性转换为一组具有明显物理意义的特征。比如通过变换特征取值来减少原始数据中某个特征的取值个数等。对于表格数据,你可以在你设计的特征矩阵上使用主要成分分析(Principal Component Analysis,PCA)来进行特征提取从而创建新的特征。对于图像数据,可能还包括了线或边缘检测。
常用的方法有:
-
PCA (Principal component analysis,主成分分析)
-
ICA (Independent component analysis,独立成分分析)
-
LDA (Linear Discriminant Analysis,线性判别分析)
对于图像识别中,还有SIFT方法。
特征构造(Feature Construction)
特征构建指的是从原始数据中人工的构建新的特征。我们需要人工的创建它们。这需要我们花大量的时间去研究真实的数据样本,思考问题的潜在形式和数据结构,同时能够更好地应用到预测模型中。
“Feature engineering and feature selection are not mutually exclusive. They are both useful. I’d say feature engineering is more important though, especially because you can’t really automate it.”
— Robert Neuhaus, answer to “Which do you think improves accuracy more, feature selection or feature engineering?”
特征构造被视为一门艺术,不仅仅是因为其重要性,更因为特征构造决定了机器学习的差异性。特征构建需要很强的洞察力、分析能力以及想象力,要求我们能够从原始数据中找出一些具有物理意义的特征,要求丰富而不冗余、精准而不遗漏。假设原始数据是表格数据,一般你可以使用混合属性或者组合属性来创建新的特征,或是分解或切分原有的特征来创建新的特征。若是文本对象,通常要设计与问题相关的特定文本指标。若是图形对象,它通常意味着设计大量的自动滤波器(filter)去挑选相关结构。
特征选择(Feature Selection)
参考:https://blog.csdn.net/boon_228/article/details/51749646
什么是特征选择
特征选择说白了就是自动的从所有的特征中选择一个特征子集,用来进行后续的训练。对于我们平时接触到的数据来说就是选择部分列。
特征选择的方法
理论方法
特征选择理论上一般有Filter、Wrapper和Embeded三种
Filter方法
Filter方法是通过特征(列)和标签(列)的相关性(特征重要性)来衡量特征所携带的信息。常用的评价相关性的标准有:Pearson相关系数,Gini-index(基尼指数),IG(信息增益)等。以Pearson相关系数为例,计算出每个特征的相关系数后,可以人为的选择排名前10的特征作为特征子集。或者画出不同子集的一个精度图,根据绘制的图形来找出性能最好的一组特征。
Filter方法主要侧重于单个特征跟目标变量的相关性。优点是计算时间上较高效,对于过拟合问题也具有较高的鲁棒性。缺点就是倾向于选择冗余的特征,因为他们不考虑特征之间的相关性,有可能某一个特征的分类能力很差,但是它和某些其它特征组合起来会得到不错的效果。
Wrapper方法
wrapper是将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,比如GA/PSO/DE/ABC。Wrapper方法实质上是一个分类器,Wrapper用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准,经过比较选出最好的特征子集。常用的有逐步回归(Stepwise regression)、向前选择(Forward selection)和向后选择(Backward selection)。它的优点是考虑了特征与特征之间的关联性,缺点是:当观测数据较少(n小)时容易过拟合,而当特征数量较多(p大)时,计算时间又会较长。
Embeded方法
Embeded方法是学习器自身自主选择特征,如使用Regularization做特征选择,或者使用决策树思想。这里还提一下,在做实验的时候,我们有时候会用Random Forest和Gradient boosting做特征选择,本质上都是基于决策树来做的特征选择,只是细节上有些区别。
工程方法
实际工作中经常面对海量的数据,工程上常用的方法有以下:
-
计算每一个特征与响应变量的相关性:工程上常用的手段有计算皮尔逊系数和互信息系数,皮尔逊系数只能衡量线性相关性而互信息系数能够很好地度量各种相关性,但是计算相对复杂一些,好在很多toolkit里边都包含了这个工具(如sklearn的MINE),得到相关性之后就可以排序选择特征了;
-
构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征,另外,记得JMLR’03上有一篇论文介绍了一种基于决策树的特征选择方法,本质上是等价的。当选择到了目标特征之后,再用来训练最终的模型;
-
通过L1正则项来选择特征:L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验;
-
训练能够对特征打分的预选模型:Random Forest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
-
通过特征组合后再来选择特征:如对用户id和用户特征进行组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见,这也是所谓亿级甚至十亿级特征的主要来源,原因是用户数据比较稀疏,组合特征能够同时兼顾全局模型和个性化模型,这个问题有机会可以展开讲。
-
通过深度学习来进行特征选择:目前这种手段正在随着深度学习的流行而成为一种手段,尤其是在计算机视觉领域,原因是深度学习具有自动学习特征的能力,这也是深度学习又叫unsupervised feature learning的原因。从深度学习模型中选择某一神经层的特征后就可以用来进行最终目标模型的训练了。
实例
下面举一个例子来说一下特征选择
数据集中的每个特征对于数据集的分类贡献并不一致,以经典iris数据集为例,这个数据集包括四个特征:sepal length,sepal width,petal length,petal width,有三个分类,setoka iris,versicolor iris和virginica iris。
这四个特征对分类的贡献如下图所示:

可见,petal width 和 petal width比sepal length和sepal width在分类上的用处要大得多(因为后者在训练集上的重叠部分太多了,导致不好用于分类)。
下面我们做几个测试
第一个:所有特征
Accuracy: 94.44% (+/- 3.51%), all attributes
第二个:两个特征
Accuracy: 94.44% (+/- 6.09%), Petal dimensions (column 3 & 4) 使用PCA方法,从新特征中找出权重TOP2的,petal width and petal width,虽然准确率和第一个没区别,但方差变大,也就是说分类性能不稳定
Accuracy: 85.56% (+/- 9.69%), PCA dim. red. (n=2) 使用LDA(不是主题模型的LDA)方法,从新特征中找出权重TOP2的,
Accuracy: 96.67% (+/- 4.44%), LDA dim. red. (n=2)
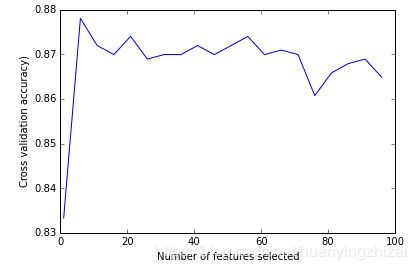
那么我们忍不住问一个问题,是不是选择全部特征集,模型准确率最高,如果不是这样,那么究竟选择什么样的特征集时准确率最高?
这里有一个图,横轴是所选择的特征数目,纵轴是交叉验证所获得的准确率,从中可以看到,并非选择了全部特征,准确率最高,当少数几个特征就可以得到最高准确率时候,选择的特征越多,反倒画蛇添足了。
总结
总的来说特征选择包括四个部分:即特征子集的选择(产生过程( Generation Procedure ))、特征子集的评价(评价函数( Evaluation Function ))、特征选择的停止(停止准则( Stopping Criterion ))、在验证集上验证特征子集的有效性(验证过程( Validation Procedure ))。
特征学习(Feature Learning)
严格来说特征学习不属于特征工程的一个分支,他的出现是为了使学习者免于从原始数据里人为的进行特征提取和特征构造。现代的深度学习方法在这个领域取得了很大的成功,并且在语音识别、图像分类和物体检测等方面得到了很大的成功。通过学习,一些特征被筛选出来,然而我们无法理解并解释这些好用的特征,也无法从中得到解决相似或者同类问题的方法。但无论如何,它的出现对于现代特征工程来说是令人激动的。
学习资源
一些关于特征提取的书籍
-
Feature Extraction, Construction and Selection: A Data Mining Perspective
-
Feature Extraction: Foundations and Applications (I like this book)
-
Feature Extraction & Image Processing for Computer Vision, Third Edition
一些关于特征选择的书籍
-
Feature Selection for Knowledge Discovery and Data Mining
-
Computational Methods of Feature Selection
一些关于特征工程的论文和课程
-
JMLR Special Issue on Variable and Feature Selection
-
Feature Engineering (PDF), Knowledge Discover and Data Mining 1, by Roman Kern, Knowledge Technologies Institute
-
Feature Engineering and Selection(PDF), CS 294: Practical Machine Learning, Berkeley
-
Feature Engineering Studio, Course Lecture Slides and Materials, Columbia
-
Feature Engineering(PDF), Leon Bottou, Princeton
一些关于特征工程的博客
- Feature Engineering: How to perform feature engineering on the Titanic competition(a getting started competition on Kaggle). There is more data munging than feature engineering, but it’s still instructive.
一些关于特征选择的视频
- Feature Engineeringby Ryan Baker