左右值无限分类 预排序遍历树算法:modified preorder tree traversal algorithm
介绍:
什么是左右值无限级分类:
左右值无限级分类,也称为预排序树无限级分类,是一种有序的树状结构,位于这些树状结构中的每一个节点都有一个“左值”和“右值”,其规则是:每一个后代节点的左值总是大于父类,右值总是小于父级,右值总是小于左值。处于这些结构中的每一个节点,都可以轻易的算出其祖先或后代节点。因此,可以用它来实现无限分类。
左右值无限分类的优缺点:
优点:
通过一条SQL就可以获取所有的祖先或后代,这在复杂的分类中非常必要
通过简单的四则运算就可以得到后代的数量
缺点
分类操作麻烦
2. 插入分类思路
删除分类是基础操作,删除分类的处理过程跟节点在分层中所处的位置是有关,在删除时需要考虑两种情况,1 删除单个的叶子分类 2 删除子节点 相对而言删除单个的叶子分类比较简单,
就好比新增的逆过程,我们删除节点的同时该节点右边所有的左右值和该父节点的右值都会减去该节点的宽度值
转载请注明来源:http://blog.csdn.net/i_bruce/article/details/41558063
什么是左右值无限级分类:
左右值无限级分类,也称为预排序树无限级分类,是一种有序的树状结构,位于这些树状结构中的每一个节点都有一个“左值”和“右值”,其规则是:每一个后代节点的左值总是大于父类,右值总是小于父级,右值总是小于左值。处于这些结构中的每一个节点,都可以轻易的算出其祖先或后代节点。因此,可以用它来实现无限分类。
左右值无限分类的优缺点:
优点:
通过一条SQL就可以获取所有的祖先或后代,这在复杂的分类中非常必要
通过简单的四则运算就可以得到后代的数量
缺点
分类操作麻烦
无法简单的获取子代(请看请“子代”和"后代")
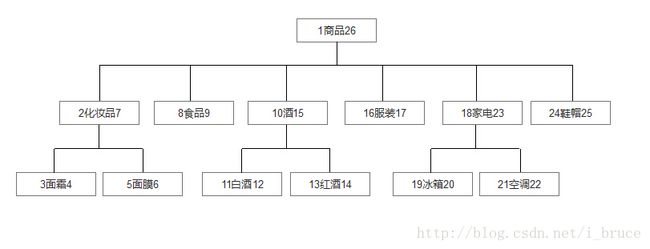
1. 测试数据准备
CREATE TABLE `nested_category` (
`category_id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`name` varchar(18) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' COMMENT '名称',
`lft` int(4) NOT NULL,
`rgt` int(4) NOT NULL,
KEY `category_id` (`category_id`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
INSERT INTO `nested_category` VALUES
(1,'商品',1,26),
(2,'化妆品',2,7),
(3,'食品',8,9),
(4,'酒',10,15),
(5,'服装',16,17),
(6,'家电',18,23),
(7,'鞋帽',24,25),
(8,'面霜',3,4),
(9,'面膜',5,6),
(10,'白酒',11,12),
(11,'红酒',13,14),
(12,'冰箱',19,20),
(13,'空调',21,22);
数据查看
mysql> select * from nested_category;
+-------------+-----------+-----+-----+
| category_id | name | lft | rgt |
+-------------+-----------+-----+-----+
| 1 | 商品 | 1 | 26 |
| 2 | 化妆品 | 2 | 7 |
| 3 | 食品 | 8 | 9 |
| 4 | 酒 | 10 | 15 |
| 5 | 服装 | 16 | 17 |
| 6 | 家电 | 18 | 23 |
| 7 | 鞋帽 | 24 | 25 |
| 8 | 面霜 | 3 | 4 |
| 9 | 面膜 | 5 | 6 |
| 10 | 白酒 | 11 | 12 |
| 11 | 红酒 | 13 | 14 |
| 12 | 冰箱 | 19 | 20 |
| 13 | 空调 | 21 | 22 |
+-------------+-----------+-----+-----+2. 插入分类思路
分析一下两种情况:
插入最顶级节点:它的左右值与该树中最大的右值有关:左值=最大右值+1,右值=最大右值+2,你可以自己模拟一下;
插入子节点:它的左右值与它的父级有关:左值=父级的右值,右值=当前的左值+1,这时要更新的数据有:父级的右值,所有左值大于父级左级,右值大于低级右值的节点左右值都应该+2;
下载实例
3. 获取所有的后代节点
从图中可以看出找出某个节点的所有子节点,lft 大于左值 rgt 小于右值
select * from nested_category where lft > 18 and rgt < 23;
+-------------+--------+-----+-----+
| category_id | name | lft | rgt |
+-------------+--------+-----+-----+
| 12 | 冰箱 | 19 | 20 |
| 13 | 空调 | 21 | 22 |
+-------------+--------+-----+-----+
2 rows in set (0.00 sec)有人认为使用 count 配合上面的语句就可以算出,这当然是可以的,但有更快的方式:每有子类节点中每个节点占用两个值,而这些值都是不一样且连续的,那些就可以计算出子代的数 量=(右值-左值-1)/2。减少1的原因是排除该节点,你可以想像一个,一个单节点,左值是1,右值是2,没有子类节点,而这时它的右值-左值=1.
5. 检索单一路径
方法:通过上述结果可以发子类的lft,rgt 都可以父类的lft,rgt之前
select
parent.name,
parent.category_id,
parent.lft,
parent.rgt
from
nested_category as node, nested_category as parent
where
node.lft between parent.lft and parent.rgt and node.name = '空调'
order by parent.lft;
+--------+-------------+-----+-----+
| name | category_id | lft | rgt |
+--------+-------------+-----+-----+
| 商品 | 1 | 1 | 26 |
| 家电 | 6 | 18 | 23 |
| 空调 | 13 | 21 | 22 |
+--------+-------------+-----+-----+
3 rows in set (0.00 sec)检索出所有的叶子节点,使用嵌套集合模型的方法比邻接表模型的LEFT JOIN方法简单多了。如果你仔细得看了nested_category表,你可能已经注意到叶子节点的左右值是连续的。要检索出叶子节点,我们只要查找满足rgt=lft+1的节点:
select
*
from
nested_category
where rgt = lft + 1;
+-------------+--------+-----+-----+
| category_id | name | lft | rgt |
+-------------+--------+-----+-----+
| 3 | 食品 | 8 | 9 |
| 5 | 服装 | 16 | 17 |
| 7 | 鞋帽 | 24 | 25 |
| 8 | 面霜 | 3 | 4 |
| 9 | 面膜 | 5 | 6 |
| 10 | 白酒 | 11 | 12 |
| 11 | 红酒 | 13 | 14 |
| 12 | 冰箱 | 19 | 20 |
| 13 | 空调 | 21 | 22 |
+-------------+--------+-----+-----+
9 rows in set (0.01 sec)select
node.name as name, (count(parent.name) - 1) as deep
from
nested_category as node,
nested_category as parent
where node.lft between parent.lft and parent.rgt
group by node.name
order by node.lft
+-----------+------+
| name | deep |
+-----------+------+
| 商品 | 0 |
| 化妆品 | 1 |
| 面霜 | 2 |
| 面膜 | 2 |
| 食品 | 1 |
| 酒 | 1 |
| 白酒 | 2 |
| 红酒 | 2 |
| 服装 | 1 |
| 家电 | 1 |
| 冰箱 | 2 |
| 空调 | 2 |
| 鞋帽 | 1 |
+-----------+------+
13 rows in set (0.03 sec)可以想象一下,你在零售网站上呈现电子产品的分类。当用户点击分类后,你将要呈现该分类下的产品,同时也需列出该分类下的直接子分类,而不是该分类下的全部分类。为此,我们只呈现该节点及其直接子节点,不再呈现更深层次的节点
如上述获取深度的例子,可以根椐深度来小于等于1获得直接子节点
select * from (
select
node.name as name,
(count(parent.name) - 1) as deep
from
nested_category as node,
nested_category as parent
where node.lft between parent.lft and parent.rgt
group by node.name
order by node.lft
) as a where a.deep <= 1;
+-----------+------+
| name | deep |
+-----------+------+
| 商品 | 0 |
| 化妆品 | 1 |
| 食品 | 1 |
| 酒 | 1 |
| 服装 | 1 |
| 家电 | 1 |
| 鞋帽 | 1 |
+-----------+------+
7 rows in set (0.00 sec)删除分类是基础操作,删除分类的处理过程跟节点在分层中所处的位置是有关,在删除时需要考虑两种情况,1 删除单个的叶子分类 2 删除子节点 相对而言删除单个的叶子分类比较简单,
就好比新增的逆过程,我们删除节点的同时该节点右边所有的左右值和该父节点的右值都会减去该节点的宽度值
lock table nested_category write;
select @myleft := lft, @myright := rgt, @mywidth := rgt-lft+1 from nested_category where name = '家电';
delete from nested_category where lft between @myleft and @myright;
update nested_category set lft = lft - @mywidth where rgt > @myright
update nested_category set rgt = rgt - @mywidth where lft > @myright
unlock tables;转载请注明来源:http://blog.csdn.net/i_bruce/article/details/41558063