来源:https://docs.janusgraph.org/
一、JanusGraph的好处
JanusGraph的设计目的是支持处理非常大的图形,这些图形需要的存储和计算能力超出了一台机器所能提供的能力。用于实时遍历和分析查询的缩放图数据处理是JanusGraph的基本优势。本节将讨论JanusGraph的各种具体好处及其底层的、受支持的持久性解决方案。
二、一般JanusGraph好处
支持非常大的图形。JanusGraph图形可以根据集群中的机器数量进行缩放。
支持非常多的并发事务和操作图处理。JanusGraph的事务处理能力随集群中机器的数量而变化,可以在毫秒内回答大型图上的复杂遍历查询。
通过Hadoop框架支持全局图分析和批处理图。
支持地理,数值范围,和全文搜索顶点和边非常大的图形。
本机支持Apache TinkerPop公开的流行属性图数据模型。
本机支持图形遍历语言Gremlin。
许多图级配置提供了调优性能的旋钮。
以vertex为中心的索引提供了vertex级别的查询,以缓解臭名昭著的超级节点问题。
提供优化的磁盘表示,以便有效地使用存储和访问速度。
在Apache 2许可下的开放源码。
三、JanusGraph与Apache Cassandra匹配的好处

连续可用,没有单点故障。
因为没有主/从架构,所以对图没有读/写瓶颈。
弹性可伸缩性允许引入和删除机器。
缓存层确保连续访问的数据在内存中可用。
通过向集群添加更多的机器来增加缓存的大小。
与Apache Hadoop集成。
在Apache 2许可下的开放源码。
三、JanusGraph与HBase匹配的好处

与Apache Hadoop生态系统的紧密集成。
本机支持强一致性。
线性可扩展性,增加更多的机器。
严格一致的读写。
使用HBase表支持Hadoop MapReduce作业的方便基类。
支持通过JMX导出指标。
在Apache 2许可下的开放源码。
四、JanusGraph和CAP定理
在使用数据库时,应该充分考虑CAP定理(C=一致性,a =可用性,P=可分性)。JanusGraph有3个支持后端:Apache Cassandra、Apache HBase和Oracle Berkeley DB Java Edition。注意,BerkeleyDB JE是一个非分布式数据库,通常仅用于JanusGraph的测试和探索。
HBase优先考虑一致性,而牺牲了收益率,即完成请求的概率。Cassandra优先考虑可用性,而牺牲了收获,即查询答案的完整性(可用数据/完整数据)。
五、开始
本节中的示例广泛使用了与JanusGraph一起发布的称为众神图的玩具图。此图如下图所示。抽象的数据模型被称为属性图模型,这个特殊的例子描述了罗马万神殿的存在和地点之间的关系。此外,图中的特殊文本和符号修饰符(例如粗体、下划线等)表示图中的不同示意图/类型。


六、下载JanusGraph并运行Gremlin控制台
JanusGraph可以从项目存储库的发布部分下载。一旦检索并解包,就可以打开Gremlin控制台。Gremlin控制台是一个与JanusGraph一起发布的REPL(即交互式shell),它与标准Gremlin控制台的唯一区别在于,JanusGraph是一个预安装和预加载的包。或者,用户可以从中央存储库下载JanusGraph包,选择在现有的Gremlin控制台中安装和激活JanusGraph。在下面的例子中,使用了janusgraph.zip,但是,一定要解压缩下载的zip文件。
注意:JanusGraph需要Java 8(标准版)。推荐使用Oracle Java 8。JanusGraph的shell脚本期望$JAVA_HOME环境变量指向安装JRE或JDK的目录。
Gremlin控制台使用Apache Groovy解释命令。Groovy是Java的一个超集,它具有各种简化的表示法,使交互式编程变得更容易。类似地,Gremlin-Groovy是Groovy的超集,具有各种简化图遍历的简写符号。下面的基本示例演示如何处理数字、字符串和映射。本教程的其余部分将讨论特定于图的构造。

注意:有关使用Gremlin的更多信息,请参阅Apache TinkerPop、SQL2Gremlin和Gremlin菜谱。
七、加载众神图到JanusGraph
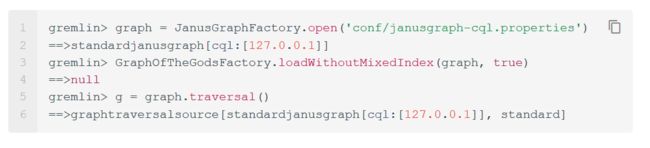
下面的示例将打开一个JanusGraph图形实例,并加载上面所示的众神数据集的图形。JanusGraphFactory提供了一组静态开放方法,每个方法都以一个配置作为参数并返回一个图形实例。本教程在使用BerkeleyDB存储后端和Elasticsearch索引后端的配置上调用这些开放方法之一,然后使用帮助类GraphOfTheGodsFactory加载诸神图。本节略过配置细节,但是关于存储后端、索引后端及其配置的其他信息可以在存储后端、索引后端和配置参考中找到。

在返回新构造的图之前,JanusGraphFactory.open()和GraphOfTheGodsFactory.load()方法执行以下操作:
在图上创建全局和以顶点为中心的索引的集合。
将所有顶点及其属性添加到图中。
将所有边及其属性添加到图中。
详情请参阅GraphOfTheGodsFactory源代码。
对于使用JanusGraph/Cassandra(或JanusGraph/HBase)的用户,请确保使用conf/JanusGraph-cql-es.properties(或conf/ JanusGraph - HBase - .properties)和GraphOfTheGodsFactory.load()。

您还可以使用conf/janusgraph-cql.properties、conf/janusgraph-berkeleyje.properties或conf/janusgraph-hbase.properties配置文件来打开没有配置后端索引的图形。在这种情况下,您需要使用GraphOfTheGodsFactory.loadWithoutMixedIndex()方法来加载众神图,这样它就不会尝试使用索引后端。
八、全局指数图
在图形数据库中访问数据的典型模式是首先使用图形索引定位到图中的入口点。该入口点是一个元素(或一组元素)——一个顶点或边。在条目元素中,Gremlin路径描述描述了如何通过显式图结构遍历图中的其他元素。
假设name属性上有一个惟一的索引,那么可以检索到Saturn顶点。然后可以检查属性图(即土星的键/值对)。正如所证明的,土星顶点有一个名字“土星”,年龄10000,和一个类型的“泰坦”。通过遍历表示:“谁是土星的孙子?”(“父亲”的反义词是“孩子”)。结果是大力神。

属性位置也在图索引中。属性位置是边属性。因此,JanusGraph可以在一个图索引中对边进行索引。可以查询在雅典50公里范围内(纬度:37.97和经度:23.72)发生的所有事件的众神图。然后,给定这些信息,哪些顶点参与了这些事件。

图索引是JanusGraph中的一种索引结构。图索引由JanusGraph自动选择,以回答要求满足一个或多个约束(例如has或interval)的所有顶点(g.V)或所有边(g.E)的问题。JanusGraph索引的第二个方面是以顶点为中心的索引。以顶点为中心的索引用于加速图内的遍历。以顶点为中心的索引将在后面介绍。
九、图遍历的例子
宙斯和阿尔克墨涅之子赫拉克勒斯拥有超人的力量。大力神是半神,因为他的父亲是神,他的母亲是人。朱庇特的妻子朱诺对朱庇特的不忠大发雷霆。为了复仇,她用暂时的精神错乱蒙蔽了大力神的双眼,导致他杀死了自己的妻子和孩子。为了赎罪,特尔斐的神谕命令赫拉克勒斯为欧律斯透斯服务。欧律斯透斯任命赫拉克勒斯做12件事。
在前面的章节中,已经证明了土星的孙子是大力神。这可以用循环来表示。在本质上,大力神是一个顶点,它离土星有2步远,沿着“父亲”的路径。

大力神是半神。要证明赫拉克勒斯是半人半神,就必须考察他父母的出身。从赫拉克勒斯的顶点到他的父母是可能的。最后,可以确定它们的类型——产生“神”和“人”。

到目前为止的例子都是关于罗马万神殿中不同角色的基因序列。属性图模型具有足够的表达能力来表示多种类型的事物和关系。通过这种方式,众神图也确定了赫拉克勒斯的各种英雄壮举——他著名的12项劳作。在前一节中,人们发现大力神卷入了雅典附近的两场战役。可以通过遍历大力神顶点的战斗边来探索这些事件。

战斗边上的边属性时间由顶点的中心索引来索引。根据对时间的约束/过滤器对大力神事件的边进行排列,比对所有边进行线性扫描和过滤(通常为O(log n),其中n为事件边数)要快。JanusGraph足够智能,可以在可用时使用以顶点为中心的索引。Gremlin表达式的toString()将分解为各个步骤。
gremlin>g.V(hercules).outE('battled').has('time',gt(1)).inV().values('name').toString()==>[GraphStep([v[24744]],vertex),VertexStep(OUT,[battled],edge),HasStep([time.gt(1)]),EdgeVertexStep(IN),PropertiesStep([name],value)]
十、更复杂的图遍历示例
冥王星住在塔耳塔斯的深处。他与赫拉克勒斯的关系因为赫拉克勒斯与他的宠物赛布勒斯的争斗而变得紧张。然而,大力神是他的侄子——他该如何让大力神为他的傲慢付出代价呢?
下面的Gremlin遍历提供了关于众神图的更多示例。每个遍历的解释在前面的行中作为//注释提供。
Tartarus的室友

Pluto’s Brothers

最后,冥王星住在塔耳塔鲁斯,因为他对死亡毫不关心。而他的兄弟们,则是根据他们对这些地点的某些特性的喜爱来选择地点的。

十一、体系结构概述
JanusGraph是一个图形数据库引擎。JanusGraph本身专注于紧凑的图形序列化、丰富的图形数据建模和高效的查询执行。另外,JanusGraph利用Hadoop进行图形分析和批处理。JanusGraph为数据持久性、数据索引和客户端访问实现了健壮的、模块化的接口。JanusGraph的模块化架构允许它与广泛的存储、索引和客户端技术进行互操作;它还简化了扩展JanusGraph以支持新图形的过程。
在JanusGraph和磁盘之间有一个或多个存储和索引适配器。JanusGraph具有以下适配器的标准,但是JanusGraph的模块化架构支持第三方适配器。
数据存储:
Apache Cassandra
Apache HBase
Oracle Berkeley DB Java Edition
索引,加快和支持更复杂的查询:
Elasticsearch
Apache Solr
Apache Lucene
一般来说,应用程序可以通过两种方式与JanusGraph交互:
将JanusGraph嵌入到应用程序中,直接针对相同JVM中的图形执行Gremlin查询。查询执行、JanusGraph的缓存和事务处理都发生在与应用程序相同的JVM中,而来自存储后端的数据检索可能是本地的,也可能是远程的。
通过向服务器提交Gremlin查询,与本地或远程JanusGraph实例进行交互。JanusGraph本身支持Apache TinkerPop堆栈的Gremlin服务器组件。
