机器学习(二)——多变量线性回归
一. 前言
本文继续《机器学习(一)——单变量线性回归》的例子,介绍多维特征中的线性回归问题,并通过矩阵计算的方法优化机器学习的计算效率。
二. 模型表示
现在我们对房价预测模型增加更多的特征值,如房间数、楼层、房屋年限等,构成一个多变量的模型,模型中的特征为( x1,x2,...,xn )。
(说明: 在现实机器学习的问题中往往具有几百甚至上万维的特征值的模型)

2.1 变量定义
下面我们引入新的变量(其余变量与单变量线性回归相同):
- n 代表特征的数量
- x(i) 代表第 i 个训练实例,是特征矩阵中的第 i 行,是一个向量(vertor)。如上图的
x(2)=⎡⎣⎢⎢⎢⎢14163240⎤⎦⎥⎥⎥⎥
- x(i)j 代表特征矩阵中第 i 行的第 j 个特征,也就是第 i 个训练实例的第 j 个特征。如上图中 x(2)3=2 。
2.2 模型定义
2.2.1 假设函数
多变量的假设函数 hθ(x) 表示为:
此公式中有n+1个参数和n个变量,为公式简洁化,引入 x0=1 ,同时定义两个向量:
x=⎡⎣⎢⎢⎢⎢⎢x0x1x2...xn⎤⎦⎥⎥⎥⎥⎥ θ=⎡⎣⎢⎢⎢⎢⎢θ0θ1θ2...θn⎤⎦⎥⎥⎥⎥⎥
则公式可转化为: hθ(x)=θTx ,其中上标T表示矩阵的转置。
2.2.2 代价函数
与单变量线性回归类似,多变量线性回归中代价函数表示为:
其中: hθ(x)=θTx=θ0x0+θ1x1+θ2x2+...+θnxn
三. 算法训练
3.1公式推导
与单变量线性回归问题一样,我们需要找到使得代价函数最小的一系列参数。同样我们可以使用梯度递降法来最小化代价函数:
即:
下面(4)式求偏导过程(可跳过):
注意:公式推导过程中
x(i)j、y(i) 可视为常量。
带入(4)式最终可得:
注意:(6)式与单变量线性回归中的公式形式一致,且在后续的逻辑回归、神经网络的公式也一致,因此有必要记住此公式。
3.2 算法步骤
下面给出算法过程:
1. 随机初始化 θ0,θ1,θ2,...,θn
2. 计算 hθ(x) 的值
3. 计算 J(θ0,θ1,θ2,...,θn) 的值(可记录每次迭代中J的值)。
4. 判断 J(θ0,θ1,θ2,...,θn) 是否小于小量 ϵ 或迭代次数大于阀值,若小于 ϵ 或迭代次数大于阀值则结束循环,当前 θ0,θ1,θ2,...,θn 值为最终所求值;否则跳转至第5步。
5. 使用公式(6) 同步更新 θ0,θ1,θ2,...,θn
6. 跳转至第2步,进行迭代。
3.3 算法复杂度
我们分析下上述算法复杂度:
先分析一次迭代过程,计算 hθ(x(i)) 的复杂度为 o(n) , 计算 J(θ0,θ1,θ2,...,θn) 的复杂度为 o(m∗n) ,计算单个 θj 的复杂度为 o(m∗n) ,计算 θ0,θ1,θ2,...,θn 的复杂度为 o(m∗n2) 。
假设迭代次数为s, 则算法的整体复杂度为 o(s∗m∗n2) ,当n和m很大时,算法的效率将变得很低。
因此下面从向量化的角度优化算法的计算性能。
3.4 向量化(Vectorization)
先说下向量化的优点:
1. 简化代码,减轻编码工作量,减少自己编码的错误率,原本需要使用循环的地方,可以利用矩阵计算,一行代码搞定。
2. 利用线性代数库,可以极大提高计算性能,可以更好地利用硬件的并行处理,性能比非向量化实现提高几十甚至上百倍。
笔者在学习过程中也是尽量使用向量化来实现各种算法。
我们先定义矩阵:
则 Θ∈Rnx1, X∈Rmxn, hθ(X)∈Rmx1 .(此处为方便编写将n+1维计成n维)
根据矩阵乘法法则,可得:
以上我们得到了 hθ(X) 和 J(θ0,θ1,...,θn) 的向量化计算,下面我们来看较为复杂的 θ0,θ1,θ2,...,θn 的计算。
我们可以假设:
其中 δ∈Rnx1的向量。
注:此处省略公式(10)的最后一步推导过程,感兴趣的可自行推导,另外可通过验证等式两边的矩阵维数做验证。
将(10)式带入(9)式,可得:
至此,我们已经将所有计算向量化,并且去掉了所有每次迭代内部的循环。
四. 优化
4.1 特征缩放
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0- 2000 平方英尺,而房间数量的值则是 0-5,以两个参数分别为横纵坐标,绘制代价函数的等 高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
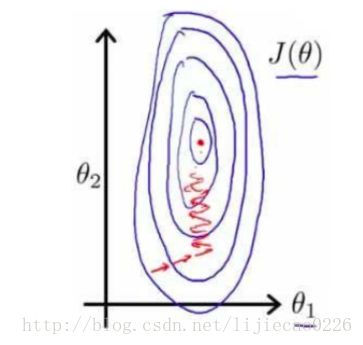
解决方法是尝试将所有特诊的尺度都尽量缩放到-1到1之间。如图:
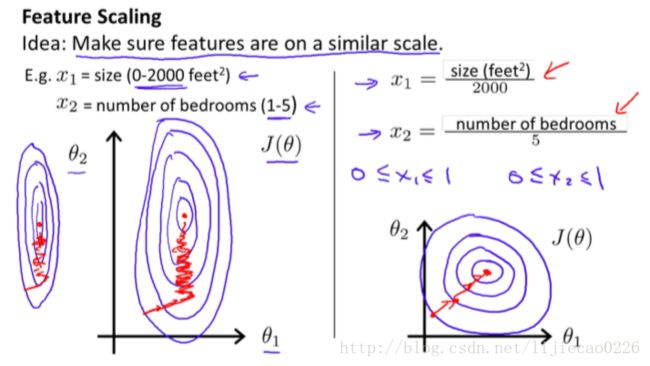
归一化的公式为:
其中 μn是平均值,sn是标准差。
4.2 学习率
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能 前预知,我们 可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。
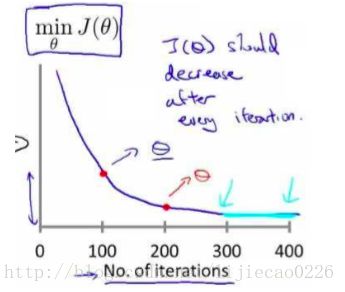
梯度下降算法的每次迭代受到学习率的影响,如果学习率 α 过小,则达到收敛所需的迭 代次数会非常高;如果学习率 α 过大,每次迭代可能不会减小代价函数,可能会越过局部最 小值导致无法收敛。
通常可以考虑尝试些学习率: α=0.01,0.03,0.1,0.3,1,3,10。