Hadoop 2.x 本地模式、伪分布模式、全分布模式的搭建
一、准备工作
1、安装Linux、JDK、关闭防火墙、配置主机名
配置主机名
vi /etc/hosts
本地模式和伪分布模式只需要添加一台主机名,全分布模式需要添加三台
本地模式和伪分布模式
192.168.100.11 bigdata11
全分布式
192.168.100.12 bigdata12
192.168.100.13 bigdata13
192.168.100.14 bigdata14
安装JDK
tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/training
设置JDK的环境变量
vi ~/.bash_proile
JAVA_HOME=/root/training/jdk1.8.0_144
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
生效环境变量:
source ~/.bash_profile
查看防火墙的状态
systemctl status firewalld.service
关闭防火墙
systemctl stop firewalld.service
注意:这种方式不是永久关闭防火墙的,开机防火墙会自动重启
永久关闭防火墙:
systemctl disable firewalld.service
解压:tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置Hadoop的环境变量: vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效Hadoop的环境变量
source ~/.bash_profile
2、Hadoop的目录结构
用tree命令查看目录结构,在CentOS / Red Hat 中是没有tree的,需要配置好yum源,用yum 源去安装
yum -y install tree
查看tree的版本
rqm -qa | grep tree

tree -d -L 3 /root/training/hadoop-2.7.3/

二、本地模式:只需要一台服务器
特点:没有HDFS、只能测试MapReduce程序
MapReduce处理的是本地Linux的文件数据
(1)vi hadoop-env.sh
在第25行 把JAVA_HOME 修改为您自己的JAVA_HOME目录
export JAVA_HOME=${JAVA_HOME}

我的JAVA_HOME目录为/root/training/jdk1.8.0_144
export JAVA_HOME=/root/training/jdk1.8.0_144
测试MapReduce程序:
1、创建目录 mkdir ~/input
2、运行
例子:cd /root/training/hadoop-2.7.3/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input/data.txt ~/output
注意:~/output为MapReduce的输出文件,此文件不能事先存在
自己写一个txt文件,在文件输入如下截图的内容

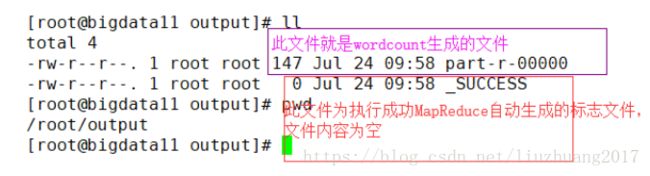
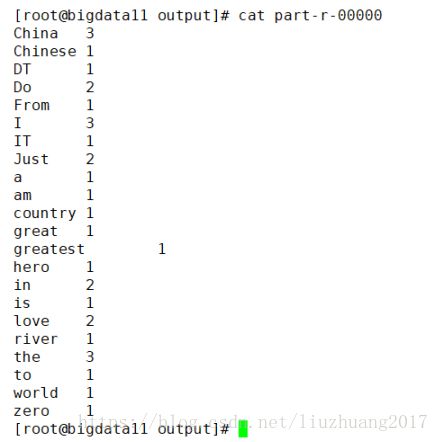
证明搭建本地模式的Hadoop成功
三、伪分布模式:一台(bigdata11)
特点:是在单机上,模拟一个分布式的环境,她具备Hadoop的主要功能
HDFS: namenode+datanode+secondarynamenode
Yarn: resourcemanager + nodemanager
vi ~/training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
原则:一般数据块的冗余度跟数据节点(DataNode)的个数一致;最大不超过3
在这个配置文件中的

先不设置是否开启权限检查
core-site.xml
mapred-site.xml 默认没有 cp mapred-site.xml.template mapred-site.xml
cp ~/training/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template ~/training/hadoop-2.7.3/etc/hadoop/mapred-site.xml
yarn-site.xml
格式化:HDFS(NameNode),一定要格式化HDFS,就相当于软盘一样,格式化了才能够正常使用
hdfs namenode -format
注意观察日志:
Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted.
![]()
启动停止Hadoop的环境
start-all.sh
stop-all.sh
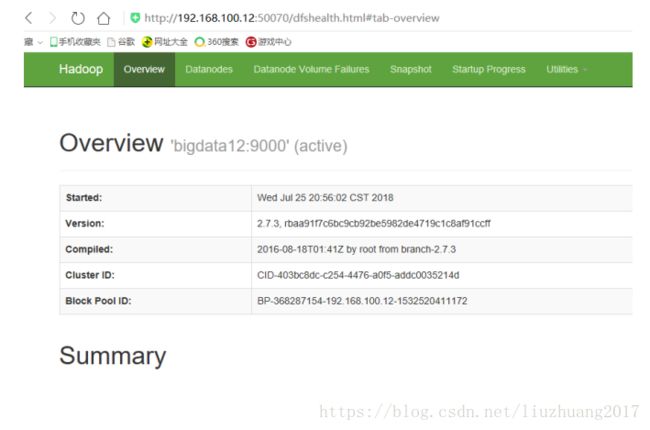
访问:通过Web界面
HDFS: http://192.168.100.11:50070
Yarn: http://192.168.100.11:8088

运行MapReduce程序
例子:
首先在HDFS上创建目录/input
hdfs dfs -mkdir /input
把Linux中的/root/input/data.txt文件上传到HDFS中的/input目录下
特别注意:Linux和HDFS目录的区别
hdfs dfs -put ~/input/test.txt /input
查看在HDFS上的目录
hdfs dfs -ls /
[root@bigdata11 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2018-07-18 19:16 /input
使用hdfs dfs -lsr / 查看子目录

在MapReduce上执行
首先进入到 /root/training/hadoop-2.7.3/share/hadoop/mapreduce这个目录,然后在此目录下执行MapReduce程序
cd /root/training/hadoop-2.7.3/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/test.txt /output/0725
注意:/input/data.txt 这个一定要是HDFS上的文件,不是Linux上的文件; /output/0407这个是HDFS不存在的文件,自动生成到指定的文件中

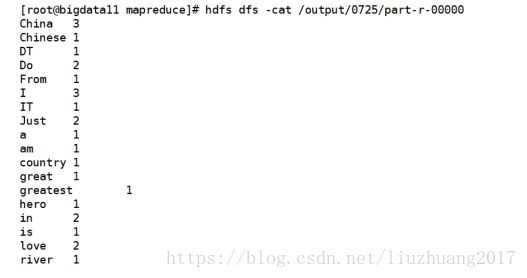
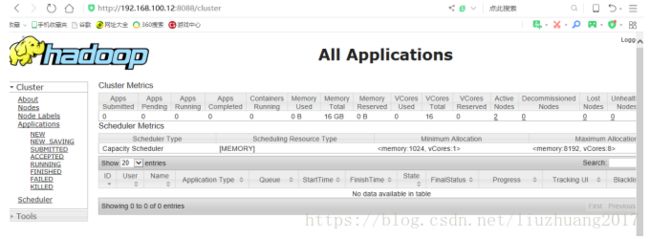
还可以通过web界面查看MapReduce任务
http://192.168.100.11:8088/cluster
(*)一定配置免密码登录:原理、配置
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub
四、全分布模式(至少3台服务器)
特点:正规的分布式环境,用于生产
1、准备工作
(*)关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
(*)安装JDK
(*)配置主机名 vi /etc/hosts
192.168.100.12 bigdata12
192.168.100.13 bigdata13
192.168.100.14 bigdata14
(*)配置免密码登录:两两之间的免密码登录
(1) 每台机器产生自己的公钥和私钥
ssh-keygen -t rsa 在每一台机器都要执行
(2) 每台机器把自己的公钥给别人 在三台机器上都要执行
ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata13
ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata14
(*)保证每台机器的时间同步
在puty工具或者Xshell工具上执行这一条命令
date -s "2018-07-17 09:15:15"是立即生效了,但是重启后,系统时间还是原来的。
如果时间不一样,执行MapReduce程序的时候可能存在问题
设置系统时间
date -s "2018-07-17 09:15:15"是立即生效了,但是重启后,系统时间还是原来的。
想要永久设置时间并且生效
date {查看目前本地的时间}
hwclock --show {查看硬件的时间}
如果硬件的时间是对不上,那就对硬件的时间进行修改
hwclock --set --date '2018-07-17 09:15:15' {设置硬件时间}
hwclock --hctosys {设置系统时间和硬件时间同步}
clock -w {保存时钟}
最后在通过重启,init 6 快速重启后,查看系统时间是否真正生效!!!!
2、在主节点上(bigdata12)安装
(1)解压设置环境变量
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置:bigdata12 ,bigdata13 ,bigdata14 环境变量
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效环境变量
source ~/.bash_profile
(2) 修改配置文件
hadoop-env.sh
JAVA_HOME=/root/training/jdk1.8.0_144 在第25行,把JAVA_HOME设置成自己路径
hdfs-site.xml
core-site.xml
mapred-site.xml 默认没有 cp mapred-site.xml.template mapred-site.xml
yarn-site.xml
需要指明从节点,编辑slaves文件,把其中的内容删掉,添加从节点的信息
vi slaves
bigdata13
bigdata14
(3)格式化NameNode: hdfs namenode -format
注意观察日志

(4) 把主节点上配置好的hadoop复制到从节点上
scp -r /root/training/hadoop-2.7.3/ root@bigdata13:/root/training
scp -r /root/training/hadoop-2.7.3/ root@bigdata14:/root/training
(5) 在主节点上启动 start-all.sh
注意:以上修改的这些配置文件都在/root/training/hadoop-2.7.3/etc/hadoop 下
(6)可以通过网页查看