Apache Kafka核心组件和流程-协调器(消费者和组协调器)-设计-原理(入门教程轻松学)
本入门教程,涵盖Kafka核心内容,通过实例和大量图表,帮助学习者理解,任何问题欢迎留言。
目录:
- kafka简介
- kafka安装和使用
- kafka核心概念
- kafka核心组件和流程--控制器
- kafka核心组件和流程--协调器
- kafka核心组件和流程--日志管理器
- kafka核心组件和流程--副本管理器
- kafka编程实战
上一节介绍了kafka工作的核心组件--控制器。本节将介绍消费者密切相关的组件--协调器。它负责消费者的出入组工作。大家可以回想一下kafka核心概念中关于吃苹果的场景,如果我邀请了100个人过来吃苹果,如果没有人告诉每个吃苹果的人哪个是他的盘子,那岂不是要乱了套?协调器做的就是这个工作。当然还有更多。
2 协调器
顾名思义,协调器负责协调工作。本节所讲的协调器,是用来协调消费者工作分配的。简单点说,就是消费者启动后,到可以正常消费前,这个阶段的初始化工作。消费者能够正常运转起来,全有赖于协调器。
主要的协调器有如下两个:
1、消费者协调器(ConsumerCoordinator)
2、组协调器(GroupCoordinator)
此外还有任务管理协调器(WorkCoordinator),用作kafka connect的works管理,本教程不做讲解。
kafka引入协调器有其历史过程,原来consumer信息依赖于zookeeper存储,当代理或消费者发生变化时,引发消费者平衡,此时消费者之间是互不透明的,每个消费者和zookeeper单独通信,容易造成羊群效应和脑裂问题。
为了解决这些问题,kafka引入了协调器。服务端引入组协调器(GroupCoordinator),消费者端引入消费者协调器(ConsumerCoordinator)。每个broker启动的时候,都会创建GroupCoordinator实例,管理部分消费组(集群负载均衡)和组下每个消费者消费的偏移量(offset)。每个consumer实例化时,同时实例化一个ConsumerCoordinator对象,负责同一个消费组下各个消费者和服务端组协调器之前的通信。如下图:
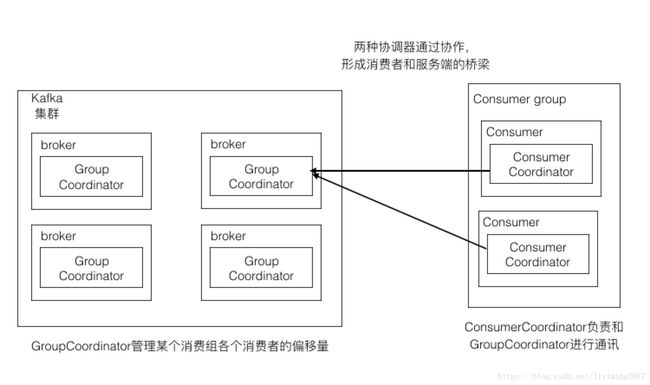
2.1 消费者协调器
消费者协调器,可以看作是消费者做操作的代理类(其实并不是),消费者很多操作通过消费者协调器进行处理。
消费者协调器主要负责如下工作:
1、更新消费者缓存的MetaData
2、向组协调器申请加入组
3、消费者加入组后的相应处理
4、请求离开消费组
5、向组协调器提交偏移量
6、通过心跳,保持组协调器的连接感知。
7、被组协调器选为leader的消费者的协调器,负责消费者分区分配。分配结果发送给组协调器。
8、非leader的消费者,通过消费者协调器和组协调器同步分配结果。
消费者协调器主要依赖的组件和说明见下图:
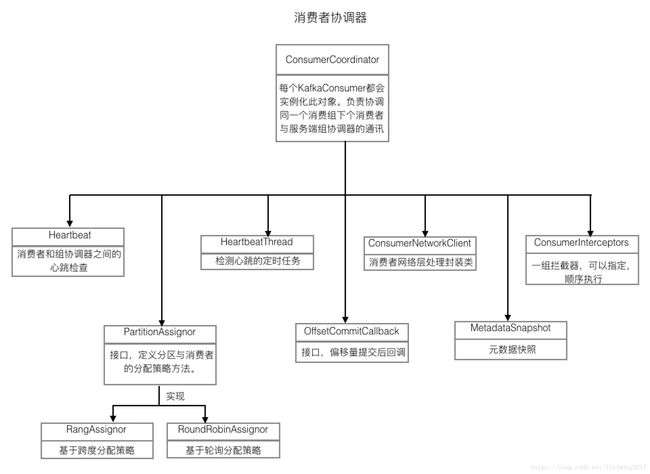
可以看到这些组件和消费者协调器担负的工作是可以对照上的。
2.2 组协调器
组协调器负责处理消费者协调器发过来的各种请求。它主要提供如下功能:
- 在与之连接的消费者中选举出消费者leader
- 下发leader消费者返回的消费者分区分配结果给所有的消费者
- 管理消费者的消费偏移量提交,保存在kafka的内部主题中
- 和消费者心跳保持,知道哪些消费者已经死掉,组中存活的消费者是哪些。
组协调器在broker启动的时候实例化,每个组协调器负责一部分消费组的管理。它主要依赖的组件见下图:

这些组件也是和组协调器的功能能够对应上的。具体内容不在详述。
2.3 消费者入组过程
下图展示了消费者启动选取leader、入组的过程。

消费者入组的过程,很好的展示了消费者协调器和组协调器之间是如何配合工作的。leader consumer会承担分区分配的工作,这样kafka集群的压力会小很多。同组的consumer通过组协调器保持同步。消费者和分区的对应关系持久化在kafka内部主题。
2.4 消费偏移量管理
消费者消费时,会在本地维护消费到的位置(offset),就是偏移量,这样下次消费才知道从哪里开始消费。如果整个环境没有变化,这样做就足够了。但一旦消费者平衡操作或者分区变化后,消费者不再对应原来的分区,而每个消费者的offset也没有同步到服务器,这样就无法接着前任的工作继续进行了。
因此只有把消费偏移量定期发送到服务器,由GroupCoordinator集中式管理,分区重分配后,各个消费者从GroupCoordinator读取自己对应分区的offset,在新的分区上继续前任的工作。
下图展示了不提交offset到服务端的问题:

开始时,consumer 0消费partition 0 和1,后来由于新的consumer 2入组,分区重新进行了分配。consumer 0不再消费partition2,而由consumer 2来消费partition 2,但由于consumer之间是不能通讯的,所有consumer2并不知道从哪里开始自己的消费。
因此consumer需要定期提交自己消费的offset到服务端,这样在重分区操作后,每个consumer都能在服务端查到分配给自己的partition所消费到的offset,继续消费。
由于kafka有高可用和横向扩展的特性,当有新的分区出现或者新的消费入组后,需要重新分配消费者对应的分区,所以如果偏移量提交的有问题,会重复消费或者丢消息。偏移量提交的时机和方式要格外注意!!
下面两种情况分别会造成重复消费和丢消息:
- 如果提交的偏移量小于消费者最后一次消费的偏移量,那么再均衡后,两个offset之间的消息就会被重复消费
- 如果提交的偏移量大于消费者最后一次消费的偏移量,那么再均衡后,两个offset之间的消息就会丢失
以上两种情况是如何产生的呢?我们继续往下看。
2.4.1 偏移量有两种提交方式
1、自动提交偏移量
设置 enable.auto.commit为true,设定好周期,默认5s。消费者每次调用轮询消息的poll() 方法时,会检查是否超过了5s没有提交偏移量,如果是,提交上一次轮询返回的偏移量。
这样做很方便,但是会带来重复消费的问题。假如最近一次偏移量提交3s后,触发了再均衡,服务器端存储的还是上次提交的偏移量,那么再均衡结束后,新的消费者会从最后一次提交的偏移量开始拉取消息,此3s内消费的消息会被重复消费。
2、手动提交偏移量
设置 enable.auto.commit为false。程序中手动调用commitSync()提交偏移量,此时提交的是poll方法返回的最新的偏移量。
我们来看下面两个提交时机:
- 如果poll完马上调用commitSync(),那么一旦处理到中间某条消息的时候异常,由于偏移量已经提交,那么出问题的消息位置到提交偏移量之间的消息就会丢失。
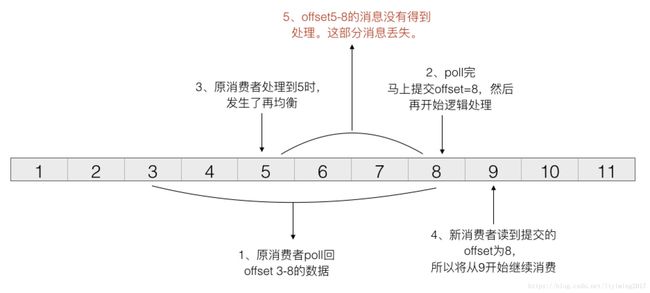
- 如果处理完所有消息后才调用commitSync()。有可能在处理到一半的时候发生再均衡,此时偏移量还未提交,那么再均衡后,会从上次提交的位置开始消费,造成重复消费。

比较起来,重复消费要比丢消息好一些,所以我们程序应采用第二种方式,同时消费逻辑中,要能够检查重复消费。
commitSync()是同步提交偏移量,主程序会一直阻塞,偏移量提交成功后才往下运行。这样会限制程序的吞吐量。如果降低提交频次,又很容易发生重复消费。
这里我们可以使用commitAsync()异步提交偏移量。只管提交,而不会等待broker返回提交结果
commitSync只要没有发生不可恢复错误,会进行重试,直到成功。而commitAsync不会进行重试,失败就是失败了。commitAsync不重试,是因为重试提交时,可能已经有其它更大偏移量已经提交成功了,如果此时重试提交成功,那么更小的偏移量会覆盖大的偏移量。那么如果此时发生再均衡,新的消费者将会重复消费消息。
commitAsync也支持回调,由于上述原因,回调中最好不要因为失败而重试提交。而是应该记录错误,以便后续分析和补偿。
2.4.2 偏移量提交的最佳实践
关于偏移量的提交方式和时机,上文已经有了大量的讲解。但看完后好像还不知道应该怎么提交偏移量才是最合适的。是不是觉得无论怎么提交,都无法避免重复消费?没错,事实就是这样,我们只能采用合理的方式,最大可能的去降低发生此类问题的概率。此外做好补偿处理。
一般来说,偶尔的提交失败,不去重试,是没有问题的。因为一般是因为临时的问题而失败,后续的提交总会成功。如果我们在关闭消费者或者再均衡前,确保所有的消费者都能成功提交一次偏移量,也可以保证再均衡后,消费者能接着消费数据。
因此我们采用同步和异步混合的方式提交偏移量。
- 正常消费消息时,消费结束提交偏移量,采用异步方式
- 如果程序报错,finally中,提交偏移量,采用同步方式,确保提交成功
- 再均衡前的回调方法中,提交偏移量,采用同步方式,确保提交成功
这样既保证了吞吐量,也保证了提交偏移量的安全性。另外由于再均衡前提交偏移量,降低了重复消费可能。
kafka还提供了提交特定偏移量的方法。我们可以指定分区和offset进行提交。分区和offset的值可以从消息对象中取得。
另外,如果担心一次取回数据量太大,可能处理到一半的时候出现再均衡,导致偏移量没有提交,重复消费。那么可以每n条提交一次。
而当n=1时,也就是处理一条数据就提交一次,会把重复消费的可能降到最低。同时由于增加了和服务端的通讯,效率大大降低。
其实即使这样,也是可能重复消费的,试想如下场景:
- 消费者拉取到数据后,开始逻辑处理
- 处理第一条offset=2,成功了,提交offset=3
- 开始处理offset=3的消息,处理完成后,但提交offset=4前,此消费者突然意外挂掉了,所以也没能进入异常处理。偏移量没能成功提交。
- 消费者进行了再均衡,新的消费者接手此分区进行消费,取到的offset还是上一次提交的3,那么将会重复消费offset=3的消息。
所以我们应平衡重复消费发生的概率和程序的效率,来设置提交的时机。同时程序逻辑一定做好重复消费的检查工作!
2.5 回顾
本节从协调器讲起,首先介绍了消费者协调器和组协调器,以及他们是如何配合工作的。从消费偏移量的管理展开,详细介绍了偏移量的提交,及提交的最佳实践。本节没有涉及代码部分,所有知识点相关的代码将在最后一章中统一给出。现在的要求只是理解知识点。
下一步:开始《kafka核心组件和流程--日志管理器》的学习