MSSQL --- MSSQL体系结构一览
声明
笔记内容为个人学习整理,绝大部分内容来源于网络。
文章内含有自己的总结、拓展与试验,仅作为个人学习资料,转载请联系原作者。
文章末尾有含原文出处,本文尚未获得所有的原作者授权,但是我不要脸。
MSSQL体系结构
在接触一个新数据库的时候,深入了解RDBMS的系结构可以更好的理解SQL语句的执行过程,分析各种问题。
- 协议层(Protocols)
- 关系引擎(Relational Engine),也成为查询处理器(Query Processor)
- 存储引擎(Storage Engine)
- SQLOS
- MSSQL体系结构
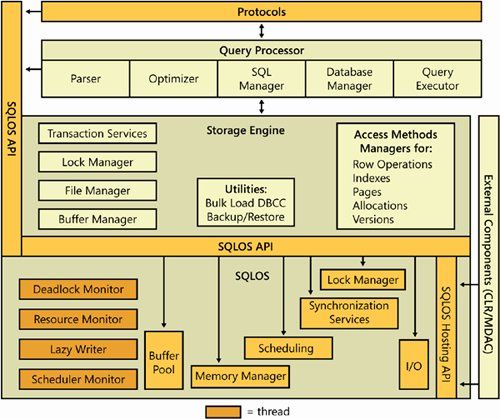
(图片来自 博客园-匠心十年 )
协议层
所谓的协议层就是Client与Server进行通信所使用的连接层。
Client(程序、SSMS、ODBC等)访问数据库的时候,首先会通过SNI(SQL Server Network Interface)选择建立通信的协议,然后与Server进行通信。
实际上在SQL Server当中不仅仅是Client可以连接Server实例,不同实例之间也可以通过连接服务器(Link Server)来达到互相访问的目的,实现跨实例查询。
通信连接建立成功以后,程序会把需要执行的SQL语句转换成TDS(TDS:Tabular Data Stream 即表格格式数据流协议)协议包,然后通过连接的通信协议发送到Server。
Server协议层收到请求之后会把请求转换成查询处理器可以处理的形式。
可使用协议
- TCP/IP – 应用最广泛的协议
- `Named Pipes – 仅为局域网(LAN)提供服务
- Shared Memory – 仅本机
- VIA – 已废除(MSSQL 2008版本的配置管理器中还有,但是2012当中已经看不到了)
具体连接协议可以通过SQL Server进行配置,可以根据不同的连接环境选择不同的连接协议。
如果客户端并未指定使用哪种协议进行连接,则可配置遍历尝试所有协议进行连接。
协议配置方法
打开SQL Server配置管理器(SQL Server Configuration Manager),选择SQL Server网络配置,选择需要配置的实例名(默认是MSSQLSERVER),可以看到有哪些协议可以使用,可以选择禁用或启用,也可以单击右键进行端口和IP的详细配置。
想要了解更多可以点击这个连接
- 博客园-魏政-配置:SQLServer允许远程连接
关系引擎(Relational Engine)
关系引擎(Relational Engine)也称为查询处理器(Query Processor)
主要包含 3 个部分:
- 命令解析器(Command Parser)
- 查询优化器(Query Optimizer)
- 查询执行器(Query Executor)
这一层会将上层传来的TDS包解析回SQL(T-SQL)语句,传递给命令解析器(Command Parser)。
命令解析器(Command Parser)
检查T-SQL语法的正确性,并讲T-SQL语句转换成可以进行操作的内部格式,即查询树(Query Tree)
查询树是结构化查询语言SQL(Structured Query Language)的内部表现形式。
- 数据操纵语言 DML(Data Manipulation Language)是 SQL 语言的子集,
- 包括 INSERT, UPDATE, DELETE 三种核心指令。
- 数据定义语言 DDL(Data Definition Language)管理表和索引结构,
- 包括 CREATE, DROP, ALTER, TRUNCATE 等命令。
- 数据控制语言 DCL(Data Control Language)负责授权用户访问和处理数据,
- 包括 GRANT, REVOKE 等命名。
T-SQL 即 Transact-SQL 则是在 SQL 基础上扩展了过程化编程语言的功能,如流程控制等。
SQLCLR(SQL Server Common Language Runtime)使用 .NET 程序集来扩展功能。
查询优化器(Query Optimizer)
从命令解析器处得到查询树(Query Tree),判断查询树是否可被优化,然后将从许多可能的方式中确定一种最佳方式,对查询树进行优化。
- 无法优化的语句,包括控制流和DDL等,将被编译成内部形式。
- 可优化的语句,例如DML等,将被坐上标记等待优化
优化步骤
- 进行规范查询
- 将单个查询分解成多个细粒度的查询,并进行优化。
- 查询优化是基于成本(Cost-based)的考量,选择效益最高的执行计划。
- 查询优化器会根据内部记录的性能指标(如CPU、内存、IO等)来选择消耗最低的计划,并将该计划传递给查询执行器。
查询优化器使用启发式算法(Pruning Heuristics),以确保评估优化及查询的时间消耗不会比直接执行未优化查询的时间更长。
查询优化器返回的结果是执行计划(Execution Plan)。
查询执行器(Query Executor)
按照查询优化器产生的执行计划执行SQL。在执行计划中承当所有命令的调度程序,并跟踪每个命令执行的过程。
大多数命令需要与存储引擎进行交互,以检索或修改数据等。

存储引擎(Storage Engine)
SQL Server 存储引擎中包含负责访问和管理数据的组件,主要包括:
- 访问方法(Access Methods)
- 锁管理器(Lock Manager)
- 事务服务(Transaction Services)
- 实用工具(Controlling Utilities)
- 访问方法(Access Methods)
- 包含创建、更新和查询数据的具体操作,下面列出了一些访问方法类型:
- 行和索引操作(Row and Index Operations):
- 负责操作和维护磁盘上的数据结构,也就是数据行和 B 树索引。
- 包含创建、更新和查询数据的具体操作,下面列出了一些访问方法类型:
页分配操作(Page Allocation Operations):
每个数据库都是 8KB 磁盘页的集合,这些磁盘页分布在多个物理文件中。SQL Server 使用 13 种磁盘页面结构,包括数据页面、索引页面等。
版本操作(Versioning Operations):
用于维护行变化的版本,以支持快照隔离(Snapshot Isolation)功能等。
访问方法并不直接检索页面,它向缓冲区管理器(Buffer Manager)发送请求,缓冲区管理器在其管理的缓存中扫描页面,或者将页面从磁盘读取到缓存中。在扫描启动时,会使用预测先行(Look-ahead Mechanism)机制对页面中的行或索引进行验证。
锁管理器(Lock Manager)
用于控制表、页面、行和系统数据的锁定,负责在多用户环境下解决冲突问题,管理不同类型锁的兼容性,解决死锁问题,以及根据需要提升锁(Escalate Locks)的功能。
事务服务(Transaction Services)
用于提供事务的 ACID 属性支持。
ACID 属性包括:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
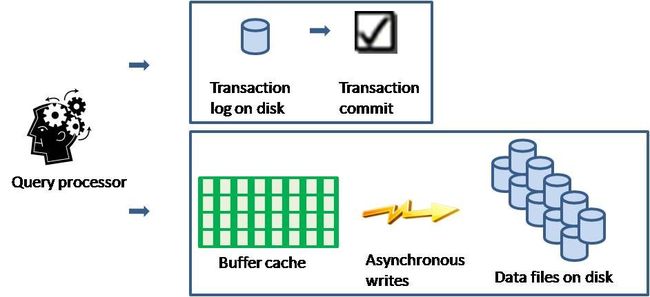
预写日志(Write-ahead Logging)
功能确保在真正发生变化的数据页写入磁盘前,始终先在磁盘中写入日志记录,使得任务回滚成为可能。写入事务日志是同步的,即 SQL Server 必须等它完成。但写入数据页可以是异步的,所以可以在缓存中组织需要写入的数据页进行批量写入,以提高写入性能。
几乎所有的RDBMS都采用了Write-ahead Logging技术来实现事务的回滚。这个特性也使得在RDBMS当中,只要日志存在且完整,即使数据文件丢失,也能够根据之前的完整备份+日志复原数据库。几乎所有的高可用都是利用的这一特性。
并发模型(Concurrency)
SQL Server 支持两种并发模型来保证事务的 ACID 属性:
- 悲观并发(Pessimistic Concurrency)假设冲突始终会发生,通过锁定数据来确保正确性和并发性。
- 乐观并发(Optimistic Concurrency)假设不会发生冲突,在碰到冲突再进行处理。
在乐观并发模型中,用户读数据时不锁定数据。在执行更新时,系统进行检查,查看另一个用户读过数据后是否更改了数据。
如果另一个用户更改了数据,则产生一个错误,接收错误信息的用户将回滚事务。
该模型主要用在数据争夺少的环境中,以及锁定数据的成本超过回滚事务的成本时。
隔离级别(Isolation Level)
SQL Server 提供了 5 种隔离级别,在处理多用户并发时可以支持不同的并发模型。
- Read Uncommitted:仅支持悲观并发
- 脏数据可读。
- Repeatable Read:仅支持悲观并发
- 避免脏读,不可重复读,允许幻读。
- Serializable:仅支持悲观并发
- 串行化读。
- 执行效率慢,使用时慎重。
Snapshot: 支持乐观并发
- 当读取数据时,可以保证读操作读取的行是事务开始时可用的最后提交版本。
- 这意味着这种隔离级别可以保证读取的是已经提交过的数据,并且可以实现可重复读,也能确保不会幻读。
- SQL Server 2005以后的版本支持。
- 这种隔离级别使用的不是共享锁,而是行版本控制。
- 当读取数据时,可以保证读操作读取的行是事务开始时可用的最后提交版本。
Read Committed:默认隔离级别,依据配置既可支持悲观并发也可支持乐观并发。
避免脏读,但可以出现不可重复读和幻读
名词解释
| 名称 | 解释 |
|---|---|
| 串行化读 | 事务只能一个一个执行,避免了脏读、不可重复读、幻读 |
| 不可重复读 | 事务对数据进行了更新或删除操作,另一事务两次查询的数据不一致。 |
| 读脏数据 | 事务对数据进行了增删改,但未提交,有可能回滚,另一事务却读取了未提交的数据。 |
| 幻像读 | 事务对数据进行了新增操作,另一事务两次查询的数据不一致。 |
实用工具(Controlling Utilities)
包含用于控制存储引擎的工具,如批量加载(Bulk-load)、DBCC 命令、全文本索引管理(Full-text Index Management)、备份和还原命令等。
SQLOS
SQLOS 是一个单独的应用层,位于 SQL Server 引擎的最低层。SQLOS 的主要功能包括:
- 调度(Scheduling)
- 内存管理(Memory Management)
- 同步(Synchronization)
- 提供 Spinlock, Mutex, ReaderWriterLock 等锁机制。
- 内存代理(Memory Broker)
- 提供 Memory Distribution 而不是 Memory Allocation。
- 错误处理(Exception Handling)
- 死锁检测(Deadlock Detection)
- 扩展事件(Extended Events)
- 异步 I/O(Asynchronous IO)
原文出处及授权
- 博客园-听风吹雨
- 博客园-匠心十年