爬取抖音粉丝数据1(作品、喜欢、ID 、关注) 完整源代码

加密数据源代码: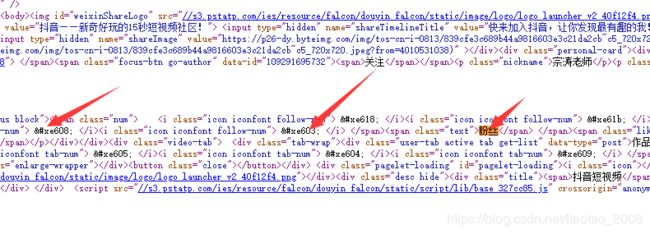
密码本如下:
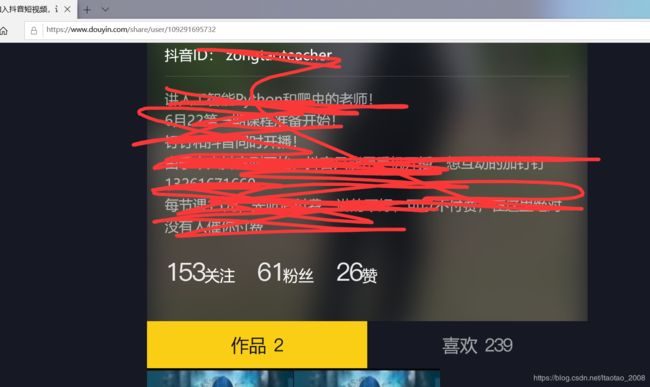
在这里插入图片描述

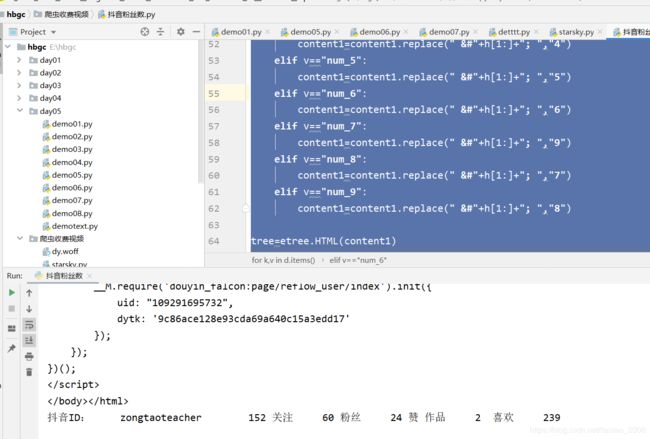
完整源代码:
import requests,re
from fontTools.ttLib import TTFont
import io
from lxml import etree
base_url=“https://www.douyin.com/share/user/109291695732”
headers={
“authority”:“www.douyin.com”,
“method”:“GET”,
“path”:"/share/user/58841646784",
“scheme”:“https”,
“accept”:“text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3”,
“accept-encoding”:“gzip, deflate, br”,
“accept-language”:“zh-CN,zh;q=0.9”,
“cache-control”:“max-age=0”,
“cookie”:"_ga=GA1.2.309264083.1587709411; _ba=BA0.2-20200424-5199e-wBTptwJ3WpFgvqUu8u6I; SLARDAR_WEB_ID=db37af0b-36d8-42f7-bf18-d9d2e9844223; _gid=GA1.2.346948988.1588147013",
“sec-fetch-mode”:“navigate”,
“sec-fetch-site”:“none”,
“sec-fetch-user”:"?1",
“upgrade-insecure-requests”:“1”,
“user-agent”:“Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36”,
}
content1=requests.get(url=base_url,headers=headers).content.decode(‘utf-8’)
print(content1)
url_p=re.compile(r’,url((.*?.woff))’)
w_list=re.findall(url_p,content1)
print(w_list)
for w in w_list:
print(w)
headers={
“Origin”:“https://www.douyin.com”,
“Referer”:“https://www.douyin.com/share/user/58841646784”,
“User-Agent”:“Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36”,
}
content=requests.get(url=“https:”+w_list[0]).content
with open(“dy.woff”,‘wb’)as f:
f.write(content)
font=TTFont(io.BytesIO(content))
d= font.getBestCmap()
for k,v in d.items():
print(hex(k),k,v)
h=hex(k)
if v=="num_":
content1=content1.replace(" &#"+h[1:]+"; ","1")
elif v=="num_1":
content1=content1.replace(" &#"+h[1:]+"; ","0")
elif v=="num_2":
content1=content1.replace(" &#"+h[1:]+"; ","3")
elif v=="num_3":
content1=content1.replace(" &#"+h[1:]+"; ","2")
elif v=="num_4":
content1=content1.replace(" &#"+h[1:]+"; ","4")
elif v=="num_5":
content1=content1.replace(" &#"+h[1:]+"; ","5")
elif v=="num_6":
content1=content1.replace(" &#"+h[1:]+"; ","6")
elif v=="num_7":
content1=content1.replace(" &#"+h[1:]+"; ","9")
elif v=="num_8":
content1=content1.replace(" &#"+h[1:]+"; ","7")
elif v=="num_9":
content1=content1.replace(" &#"+h[1:]+"; ","8")
tree=etree.HTML(content1)
name=tree.xpath(’//p[@class=“nickname”]/text()’) )