Hadoop学习与使用
Hadoop基础
1. 大数据解决方案
Hadoop是一个开源框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。它的目的是从单一的服务器到上千台机器的扩展,每一个台机都可以提供本地计算和存储。
“90%的世界数据在过去的几年中产生”。
由于新技术,设备和类似的社交网站通信装置的出现,人类产生的数据量每年都在迅速增长。美国从一开始的时候到2003年产生的数据量为5十亿千兆字节。如果以堆放的数据磁盘的形式,它可以填补整个足球场。在2011年创建相同数据量只需要两天,在2013年该速率仍在每十分钟极大地增长。虽然生产的所有这些信息是有意义的,处理起来有用的,但是它被忽略了。
1.1 什么是大数据?
大数据是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。
1.2 大数据能做什么?
大数据包括通过不同的设备和应用程序所产生的数据。下面给出的是一些在数据的框架下的领域。
-
黑匣子数据:这是直升机,飞机,喷气机的一个组成部分,它捕获飞行机组的声音,麦克风和耳机的录音,以及飞机的性能信息。
-
社会化媒体数据:社会化媒体,如Facebook和Twitter保持信息发布的数百万世界各地的人的意见观点。
-
证券交易所数据:交易所数据保存有关的“买入”和“卖出”,客户由不同的公司所占的份额决定的信息。
-
电网数据:电网数据保持相对于基站所消耗的特定节点的信息。
-
交通运输数据:交通数据包括车辆的型号,容量,距离和可用性。
-
搜索引擎数据:搜索引擎获取大量来自不同数据库中的数据。因此,大数据包括体积庞大,高流速和可扩展的各种数据。它的数据为三种类型。
-
结构化数据:关系数据。
-
半结构化数据:XML数据。
-
非结构化数据:Word, PDF, 文本,媒体日志。
1.3 数据分析的目的
- 通过保留了社交网络如Facebook的信息,市场营销机构了解可以他们的活动,促销等广告媒介的响应。
- 利用信息计划生产在社会化媒体一样喜好并让消费者对产品的认知,产品企业和零售企业。
- 使用关于患者以前的病历资料,医院提供更好的和快速的服务。
1.4 大数据技术分类
大数据的技术是在提供更准确的分析,这可能影响更多的具体决策导致更大的运行效率,降低成本,并减少了对业务的风险。
为了利用大数据的力量,需要管理和处理的实时结构化和非结构化的海量数据,可以保护数据隐私和安全的基础设施。
目前在市场上的各种技术,从不同的供应商,包括亚马逊,IBM,微软等来处理大数据。尽管找到了处理大数据的技术,我们研究了以下两类技术:
1.4.1 数据存储
这些包括像MongoDB系统,提供业务实时的能力,这里主要是数据捕获和存储互动工作。
NoSQL大数据系统的设计充分利用已经出现在过去的十年,而让大量的计算,以廉价,高效地运行新的云计算架构的优势。这使得运营大数据工作负载更容易管理,更便宜,更快的实现。
一些NoSQL系统可以提供深入了解基于使用最少的编码无需数据科学家和额外的基础架构的实时数据模式。
1.4.2 数据分析
这些包括,如大规模并行处理(MPP)数据库系统和MapReduce提供用于回顾性和复杂的分析,可能触及大部分或全部数据的分析能力的系统。
MapReduce提供分析数据的基础上,MapReduce可以按比例增加从单个服务器向成千上万的高端和低端机的互补SQL提供的功能,这是系统的一种新方法。
这两个类技术是互补的,并经常一起部署。
1.5 大数据技术操作分类
-
数据采集( Extract )
从硬件设备产生的文件数据、流解构、非结构数据,经过统一采集,开源数据采集方案有:
Apache Flume
Apache Kafka
-
数据清洗(Transform)
经过数据采集到的数据经常是非解构化的数据、空值数据、无效数据等,需要按需要进行去重、去空、去脏数据、数据字段补全等操作得到想要的结果数据,进行下一步的存储与计算操作。常见的开源方案有:
Flink
Kafka
Spark
Flume
-
数据存储(Load)
加上上面两个步骤通常被称为数据处理ETL过程,数据存储指经过数据采集、清洗后得到的理想数据进行入库保存操作,常见的数据存储方案有:
分布是数据存储(Hadoop, Cassandra, Ceph ,HBase,GreenPlum )
-
数据高效读取分析
数据入库后需要对数据进行高效(毫秒级)的查询与简单分析,一些是采用类SQL方案,一些是NoSQL方案。
类SQL:
- Apache Hive
- Impala
- GreenPlum
- Fusion Storage(MPP)
NoSQL:
- MongoDB
- HBase
-
数据分析计算
数据分析计算通常较为复杂,通过数据仓库的SQL或NoSQL的API无法进行处理分析,需要进行异常复杂的计算分析、迭代计算,这时就需要分布式处理计算的解决方案来完成,按数据处理方式分为下面两种:
-
离线批处理
通常数据分析分批进行,可按时间或数量进行分批,如一天处理一次,每1PB处理一次,这种处理方案决定了其处理的吞吐量非常大,但是数据时效性不高,数据要隔1天才能看到计算结果。常用的开源解决方案有:
- Apache Hadoop MapReduce
- Apache Spark
- Apache Flink DataSet
-
实时流处理
流处理是数据处理间隔时间非常短,通常为秒级甚至毫秒级,数据来一条处理一条或1s处理一个微批数据。其计算机制决定了其数据计算时效性很高,但吞吐量不高,常用的开源方案有:
- Apache Spark Streamming
- Apache Spark Structured Streaming
- Apache Flink DateStream
- Apache Kafka Stream
-
机器学习
根据捕获的数据进行自动迭代计算,自动判断计算结果来进行下一步的处理。
常用的Spark、Flink都有机器学习模块
-
-
数据展示与可视化
数据经过简单或复杂的处理计算后进行图像化展示,为商业决策提供直观的依据,常见的数据展示工具有:
- JupyteR
- Google Chart
- D3.js
- NBI
2. Hadoop大数据解决方案
2.1成熟的大数据解决方案技术栈
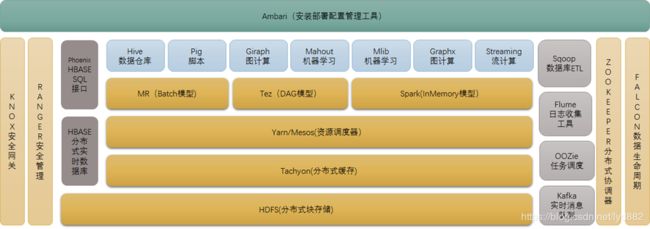
hdfs为底层的高可用分布式存储,是其他组件的底层基础,熟练掌握hadoop,也是大数据从业者的基本需要。
整个技术体系包含了数据处理的各个场景:
-
HDFS
分布式文件存储系统
-
HBase
一种NoSQL列式存储数据库
-
YARN
分布式任务调度系统
-
Flume
日志收集系统,具备ETL能力
-
Sqoop
数据ETL开源组件
-
Hive
HDFS上的SQL数据仓库,底层为hadoop 的MR,所以sql性能不高
-
Pig
用来替代hadoop MapReduce的更高级级抽象,用少量脚本来代替复杂的MapReduce代码,使分析更高效
-
Impala
Cloudera 公司研发的基于hdfs、hbase的数据提供高性能、低延迟交互式SQL查询工具,底层为内存计算模型(C++编写),不同于hive的MR模型,自动集成在CDH版hadoop中
-
Spark
开源的分布式内存计算框架,支持多种数据源,高性能、高吞吐量,支持批处理、流处理、图计算、机器学习
-
Oozie
基于DAG模型的工作流调度系统,从一个数据处理过程到下一个过程的调度与监控,如Fume->HBase->Spark->Hive等数据流程需要一个调度系统来依次流水线执行,且失败可重试
2.2 Hadoop功能
-
分布式文件存储,高可用、容错
-
数据计算,MapReduce模型,批处理与流处理
-
任务调度,Yarn任务调度器
-
应用日志监控
3. 系统架构
3.1 核心组件
3.1.1 HDFS
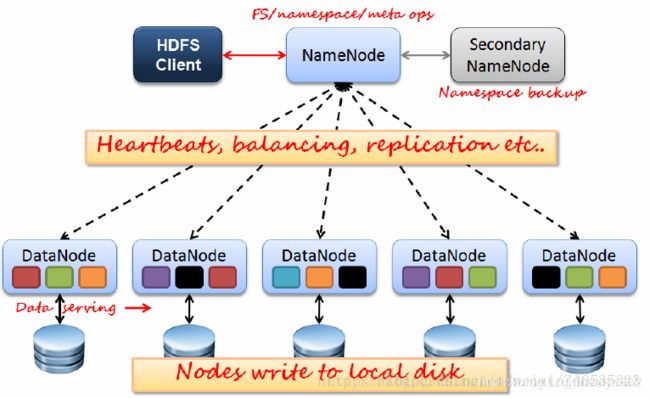
HDFS采用Master/slave架构模式,1一个Master(NameNode/NN) 带 N个Slaves(DataNode/DN)。
从内部来看,数据块存放在DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
-
NameNode
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN,edit log)的管理 -
DataNode
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况 -
Secondary NameNode
NameNode在内存中管理所有文件的元数据,并以编辑日志文件的形式持久化,每次启动NameNode时会将编辑日志与fsimage合并成新的fsimage,但在大多数情况下,NameNode不会经常重启,这样长时间会出现非常大的edit log文件,重启时会很消耗时间甚至启动失败,而且一旦NameNode磁盘挂掉无法使用,编辑日志很容易丢失导致数据无法恢复至最新状态,所以需要Secondary NameNode定期做个编辑日志聚合更能与备份功能,就是数据检查点快照功能
在单机NameNode部署下需要这个组件,来聚合旧fsimage与edit Log生成新的fsimage,并将新的fsimage通过http传回NameNode,实现镜像更新与容错,防止数据丢失
-
**QJM (Quorum Journal Manager) **
在单机NameNode模式下,需要Secondary NameNode系统检查点快照来实现数据容灾,但在集群部署模式下,就需要QJM+备用NameNode 来完成系统检查点功能,QJM也叫JournalNode,2.0版本引入,是用Zookeeper的Znode来存放编辑日志,备用NameNode来定期读取编辑日志完成检查点快照功能。同时还能在主NameNode故障情况下,自动切换至备用NameNode,实现集群高可用。2.0版本只能有两个NameNode,一个Active,一个StandBy状态,Active状态的NameNode提供服务。3.0版本后可支持2+个NameNode
还有一种高可用采用NFS,网络文件系统来实现,但是容错性不如采用QJM的方案,因为一旦NameNode网络故障,就无法完成编辑日志上传,数据会丢失,而采用QJM的方案,集群有2n+1个ZK节点,只要故障节点数在半数以下,hdfs操作就会成功,数据编辑日志就会成功上传,其他备用NameNode便会完成检查点快照功能
3.1.2 Yarn
-
ResourceManager
yarn中的master节点,资源管理器,通常与namenode在同一台机器上。由两部分组成:调度器、应用程序管理器。有以下功能:
- 响应客户端应用提交请求
- 启动、监控ApplicationMaster应用容器
- 资源管理、分配
- 管理、监控NodeManager
-
NodeManager
yarn中的slave节点,节点管理器,实际应用所在的计算节点,有以下功能:
- 及时响应ResourceManger,并报告节点状态,资源使用状态
- 管理Container生命周期
- 创建ApplicationMaster的Container,并响应其请求
- 容器状态监控,并反馈给ResourceManger
- 执行MapReduce shuffle任务
-
ApplicationMaster
应用程序启动器,在客户端提交应用时,ResourceManager响应,在某个NodeManager上启动一个容器,容器内执行的就是ApplicationMaster,接下来的该应用容器资源请求,任务分配,执行都由其来调度
-
Container
NodeManager节点上的应用资源抽象,如cpu、内存、网络、磁盘IO,目前只支持cpu和内存抽象分配。实际就是一个个应用进程。容器内执行一系列Task,如MapReduce。
容器由NodeManager管理生命周期。
3.1.2 Yarn中MapReduce计算流程
一种批处理计算模型,数据计算为抽象为两个阶段:
-
map阶段
单条记录加工处理,一条数据记录经过map方法映射成key,value,partition 相同的key为一组
-
reduce阶段
按组,多条记录统计处理,一组数据调用一次reduce方法,在方法内进行迭代计算

计算向数据移动实现流程:
- MR-Client将计算的数据/配置/jar/上传到HDFS存储通知ResourceManager,RM收到请求申请AppMaster
- RM选择一台不忙的节点通知NM启动一个Container,在里面启动一个MRAppMaster
- 启动MRAppMaster,从hdfs下载切片清单(jar或配置),向RM申请计算所需的资源(容器数,cpu核心数,内存数)
- RM根据自己掌握的资源情况得到一个确定清单,通知可用的NM来启动container
- container启动后会反向注册到已经启动的MRAppMaster进程(可供AppMaster使用资源会注册)
- MRAppMaster(起到任务调度角色)最终将任务Task发送给container(消息)
- container收到消息,到hdfs下载client上传的jar文件到本地,反射相应的Task类为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
- 计算框架都有Task失败重试的机制(有最大失败次数限制)
注:每个client任务唯一对应一个AppMaster即每个任务有独立任务调度器,互相不影响(减轻单点压力,单点故障问题)
如果nodeManager挂掉会导致分布在该节点的任务执行失败,RM心跳会监控到任务失败,重新在其它节点分配资源重新执行
3.1.3 MapReduce 过程
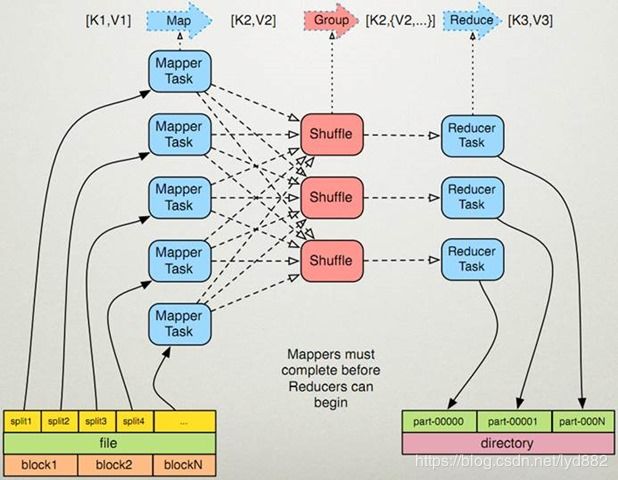
-
实现流程:
- split对应map,处理读取数据源,控制并行度,split是逻辑的,解耦与原数据源的关联
- map的输出映射成K,V,K,V会参与分区计算,根据key算出Partition -> K,V,P
- 一个Map对应一个maptask进程,map输出会写入文件,写入时中间会有100M的buffer缓存,缓存区满后按partion排序后再对key进行排序,二次排序处理后,写入临时文件
- map输出的多个临时文件最终合并为一个大文件
注:进行partition排序和key排序为了同分区的同一组key会排在一起,减少reduce端的IO复杂度
-
数据读取:
> 通过InputFormat决定读取的数据的类型,然后拆分成一个个InputSplit,每个InputSplit对应一个Map处理,RecordReader读取InputSplit的内容给Map
-
map shuffle处理过程:
- 当Map程序开始产生结果时,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
每个Map任务都有一个循环内存缓冲区(默认100MB),当缓存的内容达到80%时,后台线程开始将内容写到文件,此时Map任务可以继续输出,如果缓冲区满了,Map任务则需要等待 - Sort Shuffle, 需要特别注意的是: 每次map数据达到缓冲区的阀值时,都会将结果输出到一个文件,在Map结束时,可能会产生大量的文件,因此在Map完成前,会将这些文件进行合并和排序。
- 当Map程序开始产生结果时,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
如果文件的数量超过3个,则合并后会再次运行Combiner(1、2个文件就没有必要了)如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
- 一旦Map完成,则通知任务管理器,此时Reduce就可以开始拉取对应的结果集数据进行迭代计算,将结果写入文件
- 在写入文件之前,先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)
4. 集群部署
hadoop的集群部署有两种部署方式,一种是普通集群模式,另一种是高可用(HA)集群模式,还有根据是否使用kerberos安全认证分为安全模式部署和非安全模式部署,一般我们个人开发使用虚拟机搭建集群用普通非安全部署模式就行,HA模式太耗用硬件资源(至少两台NameNode,每个NN内存至少1g)
4.1 部署前准备
-
下载合适的版本,现在用的最多的就是2.7+的稳定版本,个人学习推荐使用较新的3.1版本,公司未来肯定要升级到3.x版本的。点我下载
-
下载Oracle jdk1.8,版本要对应cpu和操作系统版本,hadoop3.x使用jdk1.8开发编译,不支持jdk1.7,暂时也不支持jdk11,点击查看版本支持
-
集群准备,资源根据本机合理配置,操作系统ubuntu18.04 Server
虚拟机名 角色 资源配置 h1 NameNode , DataNode, ResourceManager cpu4,内存4g h2 Secondary NameNode,DataNode, NodeManager cpu4,内存4g h3 DataNode, NodeManager cpu4,内存2g -
虚拟机可使用拷贝功能来复制成3台机器
-
三台机器安装ssh,并开放ufw ssh防火墙端口
4.2 系统配置
以下5步每台机器都要配置
4.2.1 开放防火墙端口
4.2.2 安装时间同步服务ntp
4.2.3 创建一个用户hadoop及所属组bigdata
4.2.4 hadoop用户ssh免密登录配置
4.2.5 安装jdk1.8
4.2.6 hadoop配置
-
ssh到h1,解压hadoop压缩包并拷贝至/home/hadoop/,修改文件所有者为hadoop:bigdata
-
配置全局环境变量,vim /etc/profile,增加HADOOP_HOME环境变量
export JAVA_HOME=/opt/jdk1.8.0_162 export SCALA_HOME=/opt/scala-2.11.8 export HADOOP_HOME=/home/hadoop/hadoop-3.1.3 export HIVE_HOME=/home/hive/apache-hive-3.1.2-bin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HOME=/home/spark/spark-2.4.4-bin-hadoop2.7 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$SCALA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar配置后source /etc/profile,或在.bashrc中配置 source /etc/profile,重新登录都会自动添加全局环境变量
-
hadoop配置文件
-
hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_162 export HDFS_NAMENODE_USER="hadoop" export HDFS_DATANODE_USER="hadoop" export HDFS_SECONDARYNAMENODE_USER="hadoop" export YARN_RESOURCEMANAGER_USER="hadoop" export YARN_NODEMANAGER_USER="hadoop" #hadoop namenode使用并行gc,堆内存1g export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx1g" -
core-site.xml
<configuration> <property> <name>fs.defaultFSname> <value>hdfs://h1:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/hdfs/tmpvalue> property> <property> <name>io.file.buffer.sizename> <value>131072value> property> configuration> -
hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dirname> <value>/opt/hdfs/namenodevalue> <description>namenode上存储hdfs名字空间元数据 ,文件事务编辑日志位置description> property> <property> <name>dfs.datanode.data.dirname> <value>/opt/hdfs/datanodevalue> <description>datanode上数据块的物理存储位置description> property> <property> <name>dfs.blocksizename> <value>268435456value> property> <property> <name>dfs.namenode.handler.countname> <value>100value> property> <property> <name>dfs.replicationname> <value>2value> property> <property> <name>dfs.permissionsname> <value>falsevalue> property> <property> <name>dfs.namenode.http-addressname> <value>h1:50070value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>h2:50090value> property> configuration> -
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname> <value>org.apache.hadoop.mapred.ShuffleHandlervalue> property> <property> <name>yarn.resourcemanager.addressname> <value>h1:8032value> property> <property> <name>yarn.resourcemanager.scheduler.addressname> <value>h1:8030value> property> <property> <name>yarn.resourcemanager.resource-tracker.addressname> <value>h1:8031value> property> <property> <name>yarn.resourcemanager.admin.addressname> <value>h1:8033value> property> <property> <name>yarn.resourcemanager.webapp.addressname> <value>h1:8088value> property> <property> <name>yarn.nodemanager.resource.memory-mbname> <value>4096value> property> <property> <name>yarn.nodemanager.resource.cpu-vcoresname> <value>4value> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>604800value> <discription>聚合日志保留的时间7天discription> property> <property> <name>yarn.log-aggregation.retain-check-interval-secondsname> <value>-1value> <discription>检查聚合日志超时间隔时间,默认为上面属性的1/10discription> property> <property> <name>yarn.scheduler.minimum-allocation-mbname> <value>200value> <discription>单个任务可申请最少内存,默认1024MB,稍微大一点,避免小的计算浪费资源discription> property> <property> <name>yarn.scheduler.maximum-allocation-mbname> <value>8192value> <discription>单个任务可申请最大内存,默认8192MBdiscription> property> <property> <name>yarn.nodemanager.vmem-pmem-rationame> <value>3value> <discription>虚拟内存比率discription> property> <property> <name>yarn.resourcemanager.scheduler.classname> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue> <discription>容量任务调度策略,还有fair,fifo,默认fifodiscription> property> <property> <name>yarn.acl.enablename> <value>truevalue> property> <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log.server.urlname> <value>http://h1:19888/jobhistory/logsvalue> property> <property> <name>yarn.resourcemanager.nodes.exclude-pathname> <value>/home/hadoop/hadoop-3.1.3/etc/hadoop/excludesvalue> property> configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.jobhistory.addressname> <value>h1:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>h1:19888value> <discription>历史记录服务WebUI配置discription> property> <property> <name>mapred.job.trackername> <value>http://h1:9001value> property> <property> <name>mapreduce.jobhistory.intermediate-done-dirname> <value>/mr-history/tmpvalue> property> <property> <name>mapreduce.jobhistory.done-dirname> <value>/mr-history/donevalue> property> <property> <name>mapreduce.map.memory.mbname> <value>1536value> property> <property> <name>mapreduce.map.java.optsname> <value>-Xmx1024Mvalue> property> <property> <name>mapreduce.reduce.memory.mbname> <value>3072value> property> <property> <name>mapreduce.reduce.java.optsname> <value>-Xmx2560Mvalue> property> <property> <name>mapreduce.task.io.sort.mbname> <value>512value> property> <property> <name>mapreduce.task.io.sort.factorname> <value>100value> property> <property> <name>mapreduce.reduce.shuffle.parallelcopiesname> <value>50value> property> configuration> -
workers
h1 h2 h3 -
capacity-scheduler.xml ,Yarn容量调度策略配置,配置资源队列较复杂,可先不配,使用默认
-
-
将hadoop分发到h2,h3
scp -r hadoop-3.1.3/ hadoop@h2:/home/hadoop/ scp -r hadoop-3.1.3/ hadoop@h3:/home/hadoop/ -
格式化hdfs,会自动创建配置里说明的文件夹
hdfs namenode -format -
启动集群,若配置了ssh互信,使用start-all.sh启动集群
sh sbin/start-all.sh或者
sh sbin/start-dfs.sh sh sbin/start-yarn.sh -
启动历史记录服务history-server
nohup mapred historyserver & -
查看状态
hadoop@h1:~/hadoop-3.1.3/sbin$ jps 3217 NodeManager 2385 DataNode 3012 ResourceManager 2775 SecondaryNameNode 3562 JobHistoryServer 2186 NameNode 6333 Jps查看hdfs报告,正常的如下,会显示hdfs信息,正常的: Live datanodes (3)
hadoop@h1:~$ hdfs dfsadmin -report Configured Capacity: 157718839296 (146.89 GB) Present Capacity: 120217907200 (111.96 GB) DFS Remaining: 118859407360 (110.70 GB) DFS Used: 1358499840 (1.27 GB) DFS Used%: 1.13% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 192.168.1.11:9866 (h1) Hostname: h1 Decommission Status : Normal Configured Capacity: 52572946432 (48.96 GB) DFS Used: 32768 (32 KB) Non DFS Used: 12301234176 (11.46 GB) DFS Remaining: 37570707456 (34.99 GB) DFS Used%: 0.00% DFS Remaining%: 71.46% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 27 06:29:57 UTC 2020 Last Block Report: Thu Feb 27 05:08:11 UTC 2020 Num of Blocks: 0 Name: 192.168.1.12:9866 (h2) Hostname: h2 Decommission Status : Normal Configured Capacity: 52572946432 (48.96 GB) DFS Used: 679235584 (647.77 MB) Non DFS Used: 8595632128 (8.01 GB) DFS Remaining: 40597106688 (37.81 GB) DFS Used%: 1.29% DFS Remaining%: 77.22% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 27 06:29:58 UTC 2020 Last Block Report: Thu Feb 27 02:08:58 UTC 2020 Num of Blocks: 315 Name: 192.168.1.13:9866 (h3) Hostname: h3 Decommission Status : Normal Configured Capacity: 52572946432 (48.96 GB) DFS Used: 679231488 (647.77 MB) Non DFS Used: 8501149696 (7.92 GB) DFS Remaining: 40691593216 (37.90 GB) DFS Used%: 1.29% DFS Remaining%: 77.40% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Feb 27 06:29:58 UTC 2020 Last Block Report: Thu Feb 27 04:21:18 UTC 2020 Num of Blocks: 315 -
如果不正常,查看对应日志 hadoop-3.1.3/logs/,
-
查看WebUI页面
hdfs管理页面: http://h1:50070/explorer.html
Yarn管理页面: http://h1:8088/cluster/nodes
job-history页面: http://h1:19888/jobhistory
-
使用word-count应用测试集群功能
#hdfs上新建文件夹,数据输入目录 hadoop fs -mkdir input2 #查看文件夹 hadoop fs -ls #将home文件夹中的file1文件夹内的文件放到input2中,文件可随意选取,里面要有内容 hadoop fs -put ~/file1/file*.txt input2 #允许wordcount示例程序,输出到output3中,需要自定义,更改文件夹名称 hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.1.jar wordcount input2 output3 #将结果输出,更改路径 hadoop fs -cat output3/part-r-00000如果正确输出了output3内的内容,则验证集群功能正常,否则查看具体控制台日志,或在yarn页面查日志
-
集群部署完成!
4.3 hdfs NameNode本地存储目录
查看dfs.namenode.dir目录
hadoop@h1: cd /opt/hdfs/namenode/current
hadoop@h1:/opt/hdfs/namenode/current$ ll
-rw-rw-r-- 1 hadoop hadoop 42 Mar 18 18:57 edits_0000000000000009080-0000000000000009081
-rw-rw-r-- 1 hadoop hadoop 42 Mar 18 19:57 edits_0000000000000009082-0000000000000009083
-rw-rw-r-- 1 hadoop hadoop 42 Mar 18 20:57 edits_0000000000000009084-0000000000000009085
-rw-rw-r-- 1 hadoop hadoop 42 Mar 18 21:57 edits_0000000000000009086-0000000000000009087
-rw-rw-r-- 1 hadoop hadoop 1048576 Mar 18 22:22 edits_inprogress_0000000000000009088
-rw-rw-r-- 1 hadoop hadoop 55058 Mar 18 20:57 fsimage_0000000000000009085
-rw-rw-r-- 1 hadoop hadoop 62 Mar 18 20:57 fsimage_0000000000000009085.md5
-rw-rw-r-- 1 hadoop hadoop 55058 Mar 18 21:57 fsimage_0000000000000009087
-rw-rw-r-- 1 hadoop hadoop 62 Mar 18 21:57 fsimage_0000000000000009087.md5
-rw-rw-r-- 1 hadoop hadoop 5 Mar 18 21:57 seen_txid
-rw-rw-r-- 1 hadoop hadoop 216 Mar 18 09:59 VERSION
VERSION文件中是hdfs集群ID,与datanode节点的一致
edits打头的都是编辑日志,存放hdfs操作记录
fsimage打头的是hdfs系统内所有数据的元数据镜像,以记录存储,包含操作时间戳
fsimage_0000000000000009087与fsimage_0000000000000009087有相同的后缀,表示镜像已经合并了此编辑日志
edits_inprogress_0000000000000009088 ,inprogress表示最新的hdfs操作编辑日志,还未合并到镜像image文件中
查看编辑日志
-
查看fsimage的内容
hadoop@h1:/opt/hdfs/namenode/current$ hdfs oiv -p XML -i fsimage_0000000000000092691 -o fsimage.xml查看fsimage.xml内容
<inode><id>16390id><type>DIRECTORYtype><name>hadoopname><mtime>1573632987865mtime><permission>hadoop:supergroup:0733permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16391id><type>DIRECTORYtype><name>tmpname><mtime>1574349881522mtime><permission>hadoop:supergroup:0755permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16392id><type>DIRECTORYtype><name>dataname><mtime>1573633085636mtime><permission>hadoop:supergroup:0755permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16393id><type>DIRECTORYtype><name>warehousename><mtime>1584258144342mtime><permission>hive:supergroup:0733permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16394id><type>DIRECTORYtype><name>tmpname><mtime>1574181359521mtime><permission>hive:supergroup:0733permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16395id><type>DIRECTORYtype><name>logname><mtime>1573635074698mtime><permission>hive:supergroup:0733permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16396id><type>DIRECTORYtype><name>hadoopname><mtime>1573638733110mtime><permission>hadoop:supergroup:0700permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16397id><type>DIRECTORYtype><name>hivename><mtime>1574180726739mtime><permission>hive:supergroup:0700permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16419id><type>DIRECTORYtype><name>tb_testname><mtime>1573641045699mtime><permission>hive:supergroup:0755permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16420id><type>DIRECTORYtype><name>libname><mtime>1573646660543mtime><permission>spark:supergroup:0755permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16421id><type>DIRECTORYtype><name>logname><mtime>1584277759259mtime><permission>spark:supergroup:0755permission><nsquota>-1nsquota><dsquota>-1dsquota>inode> <inode><id>16422id><type>FILEtype><name>activation-1.1.1.jarname><replication>2replication><mtime>1573646396028mtime><atime>1584261796385atime><preferredBlockSize>268435456preferredBlockSize><permission>spark:supergroup:0644permission><blocks><block><id>1073741825id><genstamp>1001genstamp><numBytes>69409numBytes>block> blocks> <storagePolicyId>0storagePolicyId>inode> <inode><id>16423id><type>FILEtype><name>aircompressor-0.10.jarname><replication>2replication><mtime>1573646396068mtime><atime>1584261795745atime><preferredBlockSize>268435456preferredBlockSize><permission>spark:supergroup:0644permission><blocks><block><id>1073741826id><genstamp>1002genstamp><numBytes>134044numBytes>block> blocks> -
查看editsLog编辑日志文件内容
hadoop@h1:/opt/hdfs/namenode/current$ hdfs oev -i edits_inprogress_0000000000000009088 -o edit.xml查看edit.xml内容
<EDITS> <EDITS_VERSION>-64EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENTOPCODE> <DATA> <TXID>9086TXID> DATA> RECORD> <RECORD> <OPCODE>OP_END_LOG_SEGMENTOPCODE> <DATA> <TXID>9087TXID> DATA> RECORD> EDITS>在hdfs上创建一个目录
hadoop@h1: ~$ hdfs dfs -mkdir /test/liyuan #再次查看编辑日志,生成edit2.xml hadoop@h1:/opt/hdfs/namenode/current$ hdfs oev -i edits_inprogress_0000000000000009088 -o edit2.xml再次查看最新编辑日志inprogress
<EDITS> <EDITS_VERSION>-64EDITS_VERSION> <RECORD> <OPCODE>OP_START_LOG_SEGMENTOPCODE> <DATA> <TXID>9088TXID> DATA> RECORD> <RECORD> <OPCODE>OP_MKDIROPCODE> <DATA> <TXID>9089TXID> <LENGTH>0LENGTH> <INODEID>18069INODEID> <PATH>/test/liyuanPATH> <TIMESTAMP>1584541324873TIMESTAMP> <PERMISSION_STATUS> <USERNAME>hadoopUSERNAME> <GROUPNAME>supergroupGROUPNAME> <MODE>493MODE> PERMISSION_STATUS> DATA> RECORD> EDITS>与之前的比较发现多了一个操作RECODE,为创建该目录的操作日志记录
4.4 DataNode本地存储目录
目录解构如下:
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073742313
│ │ │ ├── blk_1073742313_1001.meta
│ │ │ ├── blk_1073742315
│ │ │ └── blk_1073742315_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
————————————————
in_use.lock表示DataNode正在对文件进行操作
rbw(replica been written)表示正在有用户进行数据写入操作
blk是数据块,.meta是数据块的元数据及校验
4.4 hdfs数据写入过程
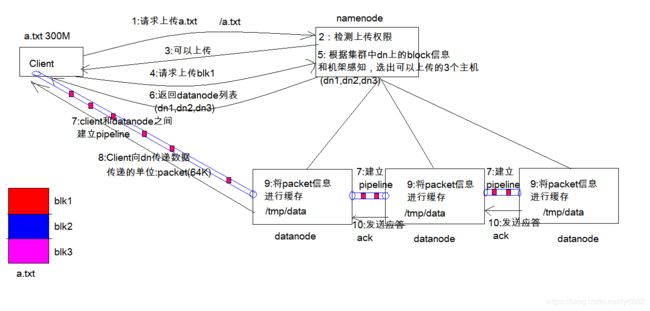
- Client 发起文件上传请求, 通过 RPC 与 NameNode 建立通讯, NameNode 检查目标文件是否已存在, 父目录是否存在, 返回是否可以上传
- Client 请求第一个 block 该传输到哪些 DataNode 服务器上
- NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配, 返回可用的DataNode 的地址如: A, B, C, Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在 HDFS 上存放三份, 存储策略为本地一份, 同机架内其它某一节点上一份, 不同机架的某一节点上一份。
- Client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline), A 收到请求会继续调用 B, 然后 B 调用 C, 将整个 pipeline 建立完成, 后逐级返回client
- Client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存), 以packet 为单位(默认64K), A 收到一个 packet 就会传给 B, B 传给 C. A 每传一个 packet 会放入一个应答队列等待应答
- 数据被分割成一个个 packet 数据包在 pipeline 上依次传输, 在 pipeline 反方向上, 逐个发送 ack(命令正确应答), 最终由 pipeline 中第一个 DataNode 节点 A 将 pipelineack 发送给 Client
- 当一个 block 传输完成之后, Client 再次请求 NameNode 上传第二个 block 到服务 1
4.5 hdfs数据读取过程
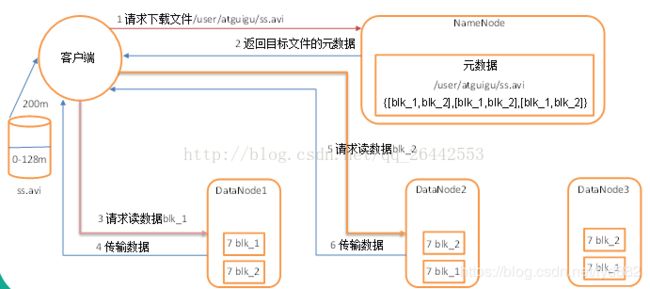
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流
5. 集群管理与使用
5.1 管理命令
查看帮助,获取所有命令:
hadoop@h1:~$ hdfs dfsadmin -help
hdfs dfsadmin performs DFS administrative commands.
Note: Administrative commands can only be run with superuser permission.
The full syntax is:
hdfs dfsadmin
[-report [-live] [-dead] [-decommissioning] [-enteringmaintenance] [-inmaintenance]]
[-safemode ]
[-saveNamespace [-beforeShutdown]]
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes]
[-setQuota ...]
[-clrQuota ...]
[-setSpaceQuota [-storageType ] ...]
[-clrSpaceQuota [-storageType ] ...]
[-finalizeUpgrade]
[-rollingUpgrade []]
[-upgrade ]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh [arg1..argn]
[-reconfig ]
[-printTopology]
[-refreshNamenodes datanode_host:ipc_port]
[-getVolumeReport datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth ]
[-getBalancerBandwidth ]
[-fetchImage ]
[-allowSnapshot ]
[-disallowSnapshot ]
[-shutdownDatanode [upgrade]]
[-evictWriters ]
[-getDatanodeInfo ]
[-metasave filename]
[-triggerBlockReport [-incremental] ]
[-listOpenFiles [-blockingDecommission] [-path ]]
[-help [cmd]]
常用的有:
- hdfs dfsadmin -report
查看hdfs状态,前面4.2.6使用过
- hdfs dfsadmin -safemode
进入安全模式,安全模式禁止写入,在备份数据、增删节点时很有用,防止数据丢失
- hdfs dfsadmin -refreshNodes
刷新datanode数据块状态,在新增节点,删除节点很有用
- hdfs dfsadmin -fetchImage localDir
获取最新的系统镜像快照,在恢复集群时很有用
- hdfs dfsadmin -shutdownDatanode
关闭某个datanode节点,不用ssh到该机器上手动关闭了,增删节点很有用
- hdfs dfsadmin -setBalancerBandwidth 104857600
数据rebanlance传输带宽限制,要调大
5.2 文件操作命令
查帮助,获取所有命令:
hadoop@h1:~$ hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
这些命令和shell中的命令功能基本一致,有几个需要注意:
-
hdfs dfs -put …
当上传文件时: 文件上传命令,当dst文件已存在,不会进行覆盖
当上传文件夹时: 只会上传成功dst/localdir/中没有的文件,已存在的文件不会覆盖
-
hdfs dfs -get …
文件从hdfs下载到本地
-
hdfs dfs -find … …
查找文件
-
hdfs dfs -du [-s] [-h] [-v] [-x] dir/file
查看文件/夹大小,-s是忽略子文件夹,-h是按M/G显示
hadoop@h1:~$ hdfs dfs -du -s -h /test/data/hdfs-site 4.1 K 8.1 K /test/data/hdfs-site -
hdfs dfs -cat file
输出文件内容
5.3 增删节点
5.3.1 增加新节点
- hdfs进入安全模式,禁止新数据写入,防止数据丢失
- 新节点机器安装JDK/JVM,配置环境变量
- 新节点设置ntp时间同步服务,与主节点时间同步
- 配置HADOOP_HOME,HADOOP_CONF_DIR环境变量
- 创建hadoop账户,并生成ssh rsa公钥,拷贝至主节点
- 将主节点hadoop完整目录远程拷贝至新节点,目录要对应一致
- 新节点启动DataNode, NodeMnager服务
- 主节点dfsadmin刷新datanodes
- 查看集群状态,命令或页面查看是否添加成功
- 将新节点添加至$HADOOP_HOME/etc/hadoop/workers文件中,下次重启会自动启动改机器
- 启动Rebalancer,数据再平衡
- hdfs离开安全模式
5.3.2 下线节点
-
hdfs进入安全模式,防止数据丢失
-
hdfs-site.xml配置新增
<property> <name>dfs.hosts.excludename> <value>/home/hadoop/hadoop-3.1.3/etc/hadoop/excludesvalue> property> -
yarn-site.xml新增
<property> <name>yarn.resourcemanager.nodes.exclude-pathname> <value>/home/hadoop/hadoop-3.1.3/etc/hadoop/excludesvalue> property> -
mapred-site.xml新增
<property> <name>mapred.hosts.excludename> <value>/home/hadoop/hadoop-3.1.2/etc/hadoop/excludesvalue> <final>truefinal> property> -
创建改excludes文件,将即将下线机器host加进去
-
hdfsadmin刷新datanodes
-
等待集群数据block备份转移完成
-
下线机器关闭hdfs datanode和yarn NodeManager
-
将$HADOOP_HOME/etc/hadoop/workers文件中该下线主机host删除,并同步至集群所有节点
-
hdfs离开安全模式
5.4 数据Rebanlance
集群环境下数据不均衡,有的占用少,有的占用多,尤其是机器磁盘资源大小不一时出现这种问题,甚至数据无法写入报错
查看hdfs数据占用百分比,有的达到90%,有的才50%,这时就需要进行数据再平衡
启动数据再平衡有两种方式:
-
- hdfs balancer [option]命令
hadoop@h1:~/hadoop-3.1.3/sbin$ hdfs balancer -help Usage: hdfs balancer [-policy <policy>] the balancing policy: datanode or blockpool [-threshold <threshold>] Percentage of disk capacity [-exclude [-f <hosts-file> | <comma-separated list of hosts>]] Excludes the specified datanodes. [-include [-f <hosts-file> | <comma-separated list of hosts>]] Includes only the specified datanodes. [-source [-f <hosts-file> | <comma-separated list of hosts>]] Pick only the specified datanodes as source nodes. [-blockpools <comma-separated list of blockpool ids>] The balancer will only run on blockpools included in this list. [-idleiterations <idleiterations>] Number of consecutive idle iterations (-1 for Infinite) before exit. [-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.-threshold为数据平衡目标,节点间数据占用百分比插值要小于这个值,默认10,设置越大,平衡进行越快;越小集群越均衡耗时也越长
-policy 为平衡策略,datanode级别或blockpool级别,默认datanode级别
-exclude/include是平衡的排除/包含的datanode节点host文件
-
- $HADOOP_HOME/sbin/start-balancer.sh启动脚本,参数与hdfs balancer一致
-
启动平衡前要设置好最大传输带宽, 单位是字节,104857600(100M),多个datanode都要设置
hdfs dfsadmin -fs hdfs://h1:9000 -setBalancerBandwidth 104857600 hdfs dfsadmin -fs hdfs://h2:9000 -setBalancerBandwidth 104857600或者在hdfs-site.xml中增加配置<备注:104857600 / (1024 * 1024) = 100M/s>
<property> <name>dfs.datanode.balance.bandwidthPerSecname> <value>104857600value> property> -
启动集群再平衡命令:
nohup hdfs balancer -threshold 15 -policy datanode >> banlancer.log & -
建议定期做个数据balancer
6. 故障与恢复
首先无论什么故障,第一肯定要去查各种日志,可从以下几个方向查日志:
- 包括HADOOP_HOME/logs下的日志
- hdfs和yarn管理页面WebUI查看状态及日志
- 系统日志/var/log
接着可以查看集群状态:
- hdfs dfsadmin -report
- hdfs、yarn管理页面查看状态
常见故障大致分成以下几类:
6.1 硬件故障,磁盘故障、空间不够,突然掉电
6.2 配置错误或不合理
6.3 内存不够,JVM堆
6.4 NameNode故障
6.5 DataNode故障
6.6 网络故障
6.7 Yarn故障,提交应用失败
6.8 hdfs常规操作失败
6.9 hdfs空间使用异常、数据分布不均衡
6.10 数据无故丢失
7. 生态圈
hadoop不仅仅是个分别式文件系统,也是一个完整的大数据生态圈,内部几乎包含了大数据处理的方方面面,形成一个成熟的大数据技术栈,最常见的有:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wlx7jzQd-1591974507520)(D:\markdown\imags\1219922-20190510232151425-1083708783.jpg)]
7.1 Apache Hive
7.2 Apache HBase
7.3 Apache Spark
7.4 Apache Flink
7.5 Apache Pig
7.6 Apache Flume
7.7 Apache Sqoop
7.8 Apache Kafka
7.9 Cloudera Impala
7.10 JanusGraph
7.11 HugeGraph
7.12 Oozie
参考与引用:
https://blog.csdn.net/qq_38202756/article/details/82262453