SAPRK 笔记 (六) 根据ip规则求归属地和广播变量
根据ip规则求归属地
现有日志数据根据日志数据解析用户归属地 , 这是一条日志中第二个是ip,现在我们可以根据ip求用户的归属地
20090121000132095572000|125.213.100.123|show.51.com|/shoplist.php?phpfile=shoplist2.php&style=1&sex=137|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Mozilla/4.0(Compatible Mozilla/4.0(Compatible-EmbeddedWB 14.59 http://bsalsa.com/ EmbeddedWB- 14.59 from: http://bsalsa.com/ )|http://show.51.com/main.php|
那怎样通过ip求? 我们可以根据ip规则去进行匹配
不通过广播变量我们应该怎么做
首先我们读取日志文件将ip拿到,通过二分法查找ip规则找到对应的ip取的归属地 ,
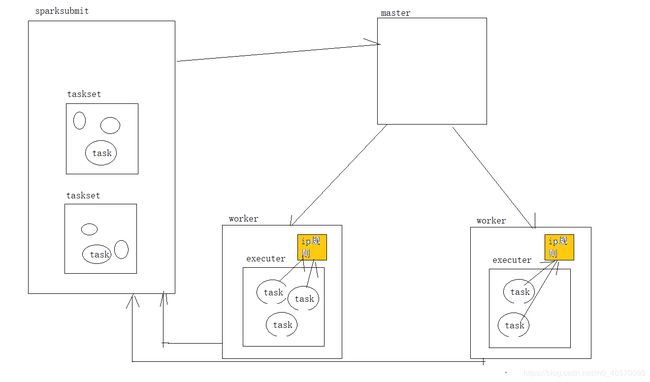
task执行在executer端 需要读取ip规则,每个task都要去读取,因为ip规则不是很大,我们将它放在内存中让task去读取他,
IP规则放到每个executer中,我们可以将ip规则放到一个单例中,在executer端初始化与之匹配 拿取归属地
工具类
package cn.spark.ipText
import scala.collection.mutable.ArrayBuffer
object IpUtils {
/**
* 将IP地址转成十进制
*
* @param ip
* @return
*/
def ip2Long(ip: String): Long = {
//1.2.2.4
val fragments = ip.split("[.]")
var ipNum = 0L
for (i <- 0 until fragments.length) {
ipNum = fragments(i).toLong | ipNum << 8L
}
ipNum
}
/**
* 二分法查找
*
*/
def binarySearch(lines: ArrayBuffer[(Long, Long, String, String)], ip: Long): Int = {
var low = 0 //起始
var high = lines.length - 1 //结束
while (low <= high) {
val middle = (low + high) / 2
if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2))
return middle
if (ip < lines(middle)._1)
high = middle - 1
else {
low = middle + 1
}
}
-1 //没有找到
}
def binarySearch(lines: Array[(Long, Long, String, String)], ip: Long): Int = {
var low = 0 //起始
var high = lines.length - 1 //结束
while (low <= high) {
val middle = (low + high) / 2
if ((ip >= lines(middle)._1) && (ip <= lines(middle)._2))
return middle
if (ip < lines(middle)._1)
high = middle - 1
else {
low = middle + 1
}
}
-1 //没有找到
}
}
package cn.spark.ipText
import java.io.{BufferedReader, InputStreamReader}
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataInputStream, FileSystem, Path}
import scala.collection.mutable.ArrayBuffer
object IpRule{
//将数据放在数组中相当于运行时放到内存
var arr = new ArrayBuffer[(Long, Long, String, String)]()
//从hdfs读取数据
val fileSystem: FileSystem = FileSystem.get(URI.create("hdfs://linux01:9000"), new Configuration())
val filePath: FSDataInputStream = fileSystem.open(new Path("/ip/ip.txt"))
val bufferedReader = new BufferedReader(new InputStreamReader(filePath))
//当数据不为空 初始化line
var line: String = null
do {
//读取数据
line = bufferedReader.readLine()
//当数据不为空
if (line != null) {
//按|切割拿取数据
val field = line.split("[|]")
val startNum = field(2).toLong
val endNum = field(3).toLong
val province = field(6)
val city = field(7)
//将数据放到元组中
val t = (startNum, endNum, province, city)
//将数据放到数组中
arr += t
}
} while (line != null)
//返回一个处理后的ip规则数据
def getaAllIpRegulation(): ArrayBuffer[(Long,Long,String,String)] = {
arr
}
}
package cn.spark.ipText
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
object IpDemo {
def main(args: Array[String]): Unit = {
val isLocal : Boolean = args(0).toBoolean
val conf = new SparkConf().setAppName(this.getClass.getSimpleName)
if (isLocal){
conf.setMaster("local[*]")
}
val sc = new SparkContext(conf)
//读取日志数据
val lines = sc.textFile(args(1))
val provinced: RDD[(String, Int)] = lines.map(line => {
//初始化ip规则数据,没有初始化就先进行初始化,初始化后就用以前的数据
val arr: ArrayBuffer[(Long, Long, String, String)] = IpRule.getaAllIpRegulation()
//按|切割拿取ip
val ipArr = line.split("[|]")
val ip = ipArr(1)
//将ip转换为10进制
val ipLong = IpUtils.ip2Long(ip)
//二分法查找到ip对应的IP规则数据
val index = IpUtils.binarySearch(arr, ipLong)
//拿取归属地
var province: String = "未知"
if (index != -1) {
province = arr(index)._3
}
(province, 1)
})
//有多少个相同归属地
val res = provinced.reduceByKey(_ + _).collect()
println(res.toBuffer)
sc.stop()
}
}
利用广播变量
下列序号对应
1 task 在hdfs或数据库读取日志数据
2 每个executer 端 task 读取部分ip规则
3 各个executer 将ip规则提交到Driver 端触发一次action
4 Driver端整合ip规则,分块广播给需要ip规则的 executer
5 executer 通过 BT 拿取自己没有的ip规则块 整合成全部的ip规则
Driver端将数据广播给需要数据的executer , executer 由于task的不同执行的任务不同,需要的数据不同,一个executer执行ip转换归属地一个executer 执行wordcount ,执行wordcount的executer就不用IP规则不需要加载ip规则, 这样可以减少了资源的浪费

package cn.spark.ipText
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object IpDemo2 {
def main(args: Array[String]): Unit = {
val isLocal : Boolean = args(0).toBoolean
val conf = new SparkConf().setAppName(this.getClass.getSimpleName)
if (isLocal){
conf.setMaster("local[*]")
}
val sc = new SparkContext(conf)
//读取ip规则
val lines1 = sc.textFile(args(1))
//提交ip规则到Driver端
val ipRulesInExecuter: Array[(Long,Long,String,String)] = lines1.map(line => {
//按|切割拿取数据
val rulesArr = line.split("[|]")
val startNum = rulesArr(2).toLong
val endNum = rulesArr(3).toLong
val province = rulesArr(6)
val city = rulesArr(7)
//将数据放到元组中
val t = (startNum, endNum, province, city)
//返回元组
t
}).collect()
//将ip规则广播出去
val inRulesRef: Broadcast[Array[(Long,Long,String,String)]] = sc.broadcast(ipRulesInExecuter)
//读取日志
val lines2 = sc.textFile(args(2))
val provinced: RDD[(String, Int)] = lines2.map(line => {
//获取ip
val ipArr = line.split("[|]")
val ip = ipArr(1)
//转换为10进制
val ipLong = IpUtils.ip2Long(ip)
//初始化IP规则数据,没有初始化就先进行初始化,初始化后就用以前的数据
val arr: Array[(Long, Long, String, String)] = inRulesRef.value
//二分法查找到ip对应的IP规则数据
val index = IpUtils.binarySearch(arr, ipLong)
//拿取归属地
var province: String = "未知"
if (index != -1) {
province = arr(index)._3
}
(province, 1)
})
//有多少个相同归属地
val res = provinced.reduceByKey(_ + _).collect()
println(res.toBuffer)
sc.stop()
}
}