spark2.3.2+Yarn+Carbondata Thrift Server 配置carbondata1.5
Carbondata简介
Apache Carbondata 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高查询效率。
Apache Carbondata 中文文档地址: http://carbondata.iteblog.com
Apache Carbondata 英文文档: http://carbondata.apache.org/
GitHub 源码地址 https://github.com/apache/carbondata/
1.是基于CDH集成Carbondata
安装mysql
https://blog.csdn.net/nszkadrgg/article/details/78666628 tar 包的安装方式
https://blog.csdn.net/nszkadrgg/article/details/85052693 rpm 包的安装方式
https://blog.csdn.net/a774630093/article/details/79270080 yum 的安装方式
安装CDH
https://blog.csdn.net/nszkadrgg/article/details/80022704 CDH5.10离线安装
2.编译个安装Carbondata基于CDH
https://github.com/apache/carbondata/tree/master/build Carbondata编译文档
下载Spark2.3.2的版本
https://archive.apache.org/dist/spark/spark-2.3.2/

解压下载好的 Spark2.3.2

下载maven 配置环境变量

配置的环境变量 vim /etc/profile
记得 source /etc/profile 让配置的环境变量生效
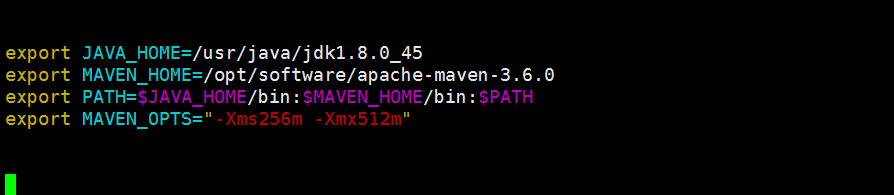
maven环境变量是否生效的验证

jdk1.8 环境变量的配置

验证JDK1.8是否安装成功

https://blog.csdn.net/cjf_wei/article/details/78700321 安装thrift 很重要,按照里面的步骤来安装,thrift 选择0.9.3的版本,其他的组件就是文章中写的版本来安装。
Carbondata 编译
下载 Carbondata,选择branch-1.5的分支,然后Clone or download

解压 carbondata包,然后进入目录
编译命令报了如下的错误,然后 mvn clean

然后修改里面的pom.xml文件
删除 然后:wq 保存退出
然后再次进入carbondata目录进行编译。
命令:
mvn clean package -DskipTests -Pspark-2.3 -Dspark.version=2.3.2 -Phadoop-2.8 -Phive -Phive-thriftserver -Pyarn -Dyarn.version=2.6.0-cdh5.15.2 -Dhadoop.version=2.6.0-cdh5.15.2 package -Pbuild-with-format
编译CarbonData,使用Spark 2.3.2,CDH hadoop 2.6: 别人编译通过的
mvn -DskipTests -Pspark-2.3 -Phadoop-2.8 -Pbuild-with-format -Pmv -Dspark.version=2.3.2 -Dhadoop.version=2.6.0-cdh5.15.0 clean package

[WARNING] The requested profile "hive" could not be activated because it does not exist.
[WARNING] The requested profile "hive-thriftserver" could not be activated because it does not exist.
[WARNING] The requested profile "yarn" could not be activated because it does not exist.
[ERROR] Failed to execute goal on project carbondata-examples: Could not resolve dependencies for project org.apache.carbondata:carbondata-examples:jar:1.5.3-SNAPSHOT: Failed to collect dependencies at org.alluxio:alluxio-core-client-hdfs:jar:1.8.1: Failed to read artifact descriptor for org.alluxio:alluxio-core-client-hdfs:jar:1.8.1: Could not transfer artifact org.alluxio:alluxio-core-client-hdfs:pom:1.8.1 from/to alimaven (http://maven.aliyun.com/nexus/content/groups/public/): Timeout while waiting for concurrent download of /opt/repo/org/alluxio/alluxio-core-client-hdfs/1.8.1/alluxio-core-client-hdfs-1.8.1.pom.part to progress -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command

[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 25:22 min
[INFO] Finished at: 2019-02-23T17:35:21+08:00
[INFO] ------------------------------------------------------------------------
[WARNING] The requested profile "hive" could not be activated because it does not exist.
[WARNING] The requested profile "hive-thriftserver" could not be activated because it does not exist.
[WARNING] The requested profile "yarn" could not be activated because it does not exist.
[ERROR] Failed to execute goal org.scala-tools:maven-scala-plugin:2.15.2:compile (default) on project carbondata-examples: wrap: org.apache.commons.exec.ExecuteException: Process exited with an error: 1(Exit value: 1) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn
[root@cdh01 carbondata-branch-1.5]# mvn clean package -DskipTests -Pspark-2.3 -Dspark.version=2.3.2 -Phadoop-2.8 -Phive -Phive-thriftserver -Pyarn -Dyarn.version=2.6.0-cdh5.15.2 -Dhadoop.version=2.6.0-cdh5.15.2 package -Pbuild-with-format
编译成功!

然后找到编译后源码包的位置
[root@cdh01 scala-2.11]#cd /opt/software/carbondata-branch-1.5/assembly/target/scala-2.11

carbondata的部署
先到spark包的目录
[root@cdh01 software]# cd spark-2.3.2-bin-2.6.0-cdh5.15.2/
新建carbonlib包
[root@cdh01 spark-2.3.2-bin-2.6.0-cdh5.15.2]# mkdir carbonlib
已经编译好的carbondata 放入 carbonlib包中
[root@cdh01 spark-2.3.2-bin-2.6.0-cdh5.15.2]# cd carbonlib/
[root@cdh01 carbonlib]# ll
total 91344
-rw-r--r--. 1 root root 93533271 Feb 26 09:15 apache-carbondata-1.5.3-SNAPSHOT-bin-spark2.3.2-hadoop2.6.0-cdh5.15.2.jar
到spark 的conf 目录,修改参数
[root@cdh01 spark-2.3.2-bin-2.6.0-cdh5.15.2]# cd conf/
[root@cdh01 conf]# ll
total 56
-rw-r--r--. 1 root root 4094 Feb 26 09:22 carbon.properties
-rw-r--r--. 1 root root 4094 Feb 26 09:22 carbon.properties.template
-rw-rw-r--. 1 root root 996 Sep 16 20:13 docker.properties.template
-rw-rw-r--. 1 root root 1105 Sep 16 20:13 fairscheduler.xml.template
-rw-rw-r--. 1 root root 2025 Sep 16 20:13 log4j.properties.template
-rw-rw-r--. 1 root root 7801 Sep 16 20:13 metrics.properties.template
-rw-rw-r--. 1 root root 862 Feb 26 09:30 slaves.template
-rw-r--r--. 1 root root 1292 Feb 26 09:30 spark-defaults.conf
-rw-rw-r--. 1 root root 1292 Sep 16 20:13 spark-defaults.conf.template
-rwxr-xr-x. 1 root root 4298 Feb 26 09:21 spark-env.sh
-rwxrwxr-x. 1 root root 4221 Sep 16 20:13 spark-env.sh.template
复制文件
[root@cdh01 conf]# cp carbon.properties.template carbon.properties
[root@cdh01 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@cdh01 conf]# cp spark-env.sh.template spark-env.sh
添加主机名 修改后保存退出
[root@cdh01 conf]# vim slaves.template
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# A Spark Worker will be started on each of the machines listed below.
cdh01
[root@cdh01 conf]# vim spark-defaults.conf
添加如下参数
spark.master=yarn-client
spark.yarn.dist.files=/opt/spark-2.3.2-bin-2.6.0-cdh5.15.2/conf/carbon.properties
spark.yarn.dist.archives=/opt/spark-2.3.2-bin-2.6.0-cdh5.15.2/carbonlib/carbondata.tar.gz
spark.executor.extraJavaOptions="-Dcarbon.properties.filepath = carbon.properties"
spark.executor.extraClassPath=carbondata.tar.gz/carbonlib/*
spark.driver.extraClassPath=/opt/spark-2.3.2-bin-2.6.0-cdh5.15.2/carbonlib/*
spark.driver.extraJavaOptions="-Dcarbon.properties.filepath = $SPARK_HOME/conf/carbon.properties"
# 如果你的 CarbonData 实例仅用于查询,你可以在 spark 配置文件设置 spark.speculation = true 属性
spark.speculation = true
# # 这个值可以设置成 executor 核总数的 1 到 2倍。在一个聚合场景里,将这个值从 200 减少到 32,查询时间从 17 秒减少到 9 秒。
# #spark.sql.shuffle.partitions=40
spark.sql.shuffle.partitions=32
# #增加每个spark任务处理的数据量,可以减少spark的任务个数,可以减少文件数
set mapred.min.split.size=1342177280
修改carbon.properties 加入以下参数
[root@cdh01 conf]# vim carbon.properties
carbon.storelocation=hdfs://192.168.1.130:8020/user/hive/warehouse/carbon.store
carbon.task.distribution=merge_small_files
hive 的metadata db(很重要)
是把hive-site.xml 放在编译后的conf文件中吧,这个我漏了写了,是,要从cdh的配置中拷出来,放的位置/opt/spark-2.3.2-bin-2.6.0-cdh5.15.2/conf
修改 spark-env.sh 添加以下环境变量(参数都结合你资源的情况来进行调整)
export SPARK_MASTER_IP=cdh01
export SCALA_HOME=/opt/software/scala-2.11.8
export SPARK_WORKER_MEMORY=3g
export JAVA_HOME=/usr/java/jdk1.8.0_45
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/etc/hadoop
添加启动脚本
[root@cdh01 hadoop-hdfs]# pwd
/var/lib/hadoop-hdfs
[root@cdh01 hadoop-hdfs]# vim startup.sh
sh /opt/software/spark-2.3.2-bin-2.6.0-cdh5.15.2/bin/spark-submit \
--class org.apache.carbondata.spark.thriftserver.CarbonThriftServer \
--num-executors 2 --driver-memory 3g --executor-memory 6g --executor-cores 2 \
/opt/software/spark-2.3.2-bin-2.6.0-cdh5.15.2/carbonlib/apache-carbondata-1.5.3-SNAPSHOT-bin-spark2.3.2-hadoop2.6.0-cdh5.15.2.jar \
hdfs://192.168.137.130:8020/user/hive/warehouse/carbon.store #carbondata元数据的位置
以上参数添加完了以后保存
chmod +x startup.sh 执行了以后变成绿色就可以了
然后启动
[root@cdh01 hadoop-hdfs]# sh startup.sh
报了一下错误,这我们要修改cdh yarn 服务的资源
java.lang.IllegalArgumentException: Required executor memory (6144+614 MB) is above the max threshold (1041 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:318)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:166)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164)
at org.apache.spark.SparkContext.
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.CarbonSession$CarbonBuilder$$anonfun$2.apply(CarbonSession.scala:241)
at org.apache.spark.sql.CarbonSession$CarbonBuilder$$anonfun$2.apply(CarbonSession.scala:233)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.CarbonSession$CarbonBuilder.getOrCreateCarbonSession(CarbonSession.scala:233)
at org.apache.spark.sql.CarbonSession$CarbonBuilder.getOrCreateCarbonSession(CarbonSession.scala:169)
at org.apache.carbondata.spark.thriftserver.CarbonThriftServer$.main(CarbonThriftServer.scala:74)
at org.apache.carbondata.spark.thriftserver.CarbonThriftServer.main(CarbonThriftServer.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2019-02-26 13:38:45 INFO AbstractConnector:318 - Stopped Spark@7d3c09ec{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2019-02-26 13:38:45 INFO SparkUI:54 - Stopped Spark web UI at http://cdh01:4040
2019-02-26 13:38:45 WARN YarnSchedulerBackend$YarnSchedulerEndpoint:66 - Attempted to request executors before the AM has registered!
2019-02-26 13:38:45 INFO YarnClientSchedulerBackend:54 - Stopped
2019-02-26 13:38:45 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!
2019-02-26 13:38:45 INFO MemoryStore:54 - MemoryStore cleared
2019-02-26 13:38:45 INFO BlockManager:54 - BlockManager stopped
2019-02-26 13:38:45 INFO BlockManagerMaster:54 - BlockManagerMaster stopped
2019-02-26 13:38:45 WARN MetricsSystem:66 - Stopping a MetricsSystem that is not running
2019-02-26 13:38:45 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:54 - OutputCommitCoordinator stopped!
2019-02-26 13:38:45 INFO SparkContext:54 - Successfully stopped SparkContext
Exception in thread "main" java.lang.IllegalArgumentException: Required executor memory (6144+614 MB) is above the max threshold (1041 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:318)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:166)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:164)
at org.apache.spark.SparkContext.
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2493)
at org.apache.spark.sql.CarbonSession$CarbonBuilder$$anonfun$2.apply(CarbonSession.scala:241)
at org.apache.spark.sql.CarbonSession$CarbonBuilder$$anonfun$2.apply(CarbonSession.scala:233)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.CarbonSession$CarbonBuilder.getOrCreateCarbonSession(CarbonSession.scala:233)
at org.apache.spark.sql.CarbonSession$CarbonBuilder.getOrCreateCarbonSession(CarbonSession.scala:169)
at org.apache.carbondata.spark.thriftserver.CarbonThriftServer$.main(CarbonThriftServer.scala:74)
at org.apache.carbondata.spark.thriftserver.CarbonThriftServer.main(CarbonThriftServer.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:894)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2019-02-26 13:38:45 INFO ShutdownHookManager:54 - Shutdown hook called
2019-02-26 13:38:45 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-3633c790-3350-4aab-a175-d0ee0d3a224a
2019-02-26 13:38:45 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-5c91ab1f-a2be-405f-8a00-c48adfa050f9
修改hive的端口,hive的端口默认是10000,我们修改20000,carbondata Thrift Server 默认的端口是20000,这样就避免的端口的冲突。

点击yarn

选择配置,根据资源的情况我们给我yarn 最大6G,然后保存
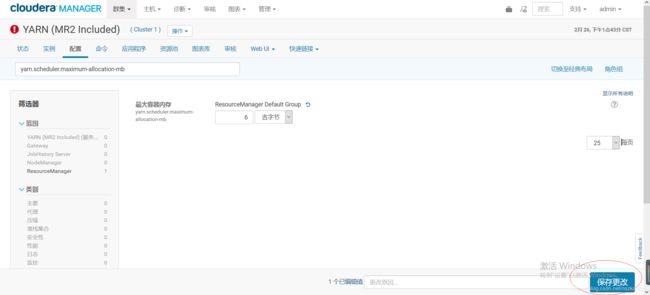
修改yarn nodemanager 的内存,然后保存,然后会有提示重新启动yarn的服务,记住下一步的时候那个单选按钮一个要勾上。
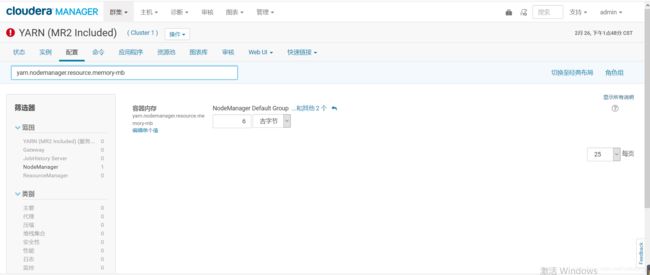
然后重启yarn 。
以上是我在我自己电脑的虚拟机上配置的自己的电脑资源小,下来我用公司的电脑进行一下测试。
首先我们启动 carbondata Thrift Server
后台的启动方式nohup ~/startup.sh
查看日志 tail -f
测试机集群的资源,配置的时候我使用我本地的参数安装和编译的,我本地的机器资源小,查询速度不明显。

启动以后我们在yarn的界面查看任务,在Running中,有一个ApplicationMaster,点击进去。
通过beeline的方式连接carbonThriftServer,切换到hdfs用户,如果没有添加hdfs用户,用root用户也行。
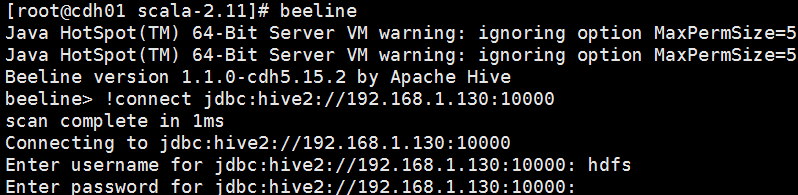
连接上了,show database。
创建carbondata的hive表时,我们可以看看官网表的优化机制,可以加快查询速度。
http://carbondata.iteblog.com/data-management-on-carbondata.html carbondata的中文文档,主要还是以英文文档为主。
在创建表中有一个使用指南。
1.字典编码设置,这个参数是需要你查询结果小于10w条记录的时候推荐使用。
TBLPROPERTIES ('DICTIONARY_INCLUDE'='column1, column2')
2.倒排序索引配置,默认情况下,倒排序索引是默认启用的,有可能有助于提高压缩率和查询速度,特别是对除于有利位置的低基数列。建议使用用例,对于高基数列,你可以禁用倒排序索引以提高数据加载性能,使用频率高的字段放在最后。
TBLPROPERTIES ('NO_INVERTED_INDEX'='column1, column3')
TBLPROPERTIES (
'MAJOR_COMPACTION_SIZE'='2048', # Major compaction 大小可以使用这个参数进行配置。segments 大小总和低于此阈值的将会被合并。此值的单位为 MB
'AUTO_LOAD_MERGE'='true', # 数据加载的时候启用压缩。
'COMPACTION_LEVEL_THRESHOLD'='4,3', #该属性在 minor compaction 时使用,决定要合并多少个 segments。比如:如果将这个属性设置为 2, 3,那么每 2 个 segments 会触发一次 Level 1 的 minor compaction。每 3 个 Level 1 的 compacted segment 将会进一步压缩成新的 segment。
'COMPACTION_PRESERVE_SEGMENTS'='10', # 如果用户想防止一些 segments 被压缩,可以通过设置这个参数。比如 carbon.numberof.preserve.segments = 2,那么 2 个最新的 segments 总是被排除在压缩之外。默认没有 segments 被保留。如果用户想防止一些 segments 被压缩,可以通过设置这个参数。比如 carbon.numberof.preserve.segments = 2,那么 2 个最新的 segments 总是被排除在压缩之外。默认没有 segments 被保留。
'ALLOWED_COMPACTION_DAYS'='5', #压缩属性,在指定的天数内加载的 segment 将被合并。如果配置为 2,仅在 2 天内加载的 segment 被合并,2 天之前的 segment 不会被合并。默认没有被启用
NO_INVERTED_INDEX=' id,name,age',
'SORT_COLUMNS'='id, #就是使用频率最高的放在最后面,最低的放在最前面,比如where后面的条件。
name,
age
'SORT_SCOPE'='GLOBAL_SORT');
'SORT_SCOPE'='GLOBAL_SORT'这会增加数据的查询性能,特别是高并发查询。如果你特别关心加载资源的隔离时使用,因为系统使用 Spark 的 GroupBy 对数据进行排序,我们可以通过 Spark 来控制资源。
这是我创建表的语句,第二张小表也是一样。
加载数据的方式 (load数据一定要放在hdfs中,在本地load 数据会提示文件不存在)
load data inpath '/opt/20181201.csv' into table jwdss.carbon_yw_data_detail_10 partition (driverdate='20181201') OPTIONS('GLOBAL_SORT_PARTITIONS'='2','HEADER'='false');
HEADER'='false' 解释
如果你加载不带文件头的 CSV 文件并且文件头和表的模式一致,这时候你可以在加载数据的 SQL 里面加上 'HEADER'='false',这时候用户就不需要指定文件头。默认情况下这个属性的值是 'true'。 false: CSV 文件不带文件头;true: CSV 文件带文件头。
GLOBAL_SORT_PARTITIONS=2 解释
(GLOBAL_SORT_PARTITIONS'='2')和(GLOBAL_SORT_PARTITIONS'='1')
但是load上传文件大小小于block size时,这个参数是不是就不起作用了
同样的数据量,分区多,文件肯定多。
类似spark中的repartition(4) 这样就有4个分区
也就是说,我将多个小的分区合并成大的分区,我设置成2,就是2个大的分区
比如1G文件,hdfs block size 是128M,那么就有8个分区,此时设置为2,那就会把4个分区的数据合并为1个。
导出数据的方式,(导出成csv文件)
beeline -u jdbc:hive2://192.168.1.100:10000 --showHeader=false --verbose=true --outputformat=csv2 -e "select * from test.test_6 where driverdate='20181201'">>/opt/middle_20181201_.csv
![]()
现在查询时间是15秒。
carbondata优化(数据加载完成之后在做一下的优化会生效)
CREATE TABLE 大表(
age STRING,
city STRING,
name STRING,
cost STRING,
earnings STRING)
STORED BY 'carbondata'
row format delimited fields terminated by ','
TBLPROPERTIES (
'MAJOR_COMPACTION_SIZE'='512',
'AUTO_LOAD_MERGE'='true',
'COMPACTION_LEVEL_THRESHOLD'='4,3',
'SORT_COLUMNS'='earnings,cost,name,city,age',
'NO_INVERTED_INDEX'='earnings,cost,name,city,age',
'SORT_SCOPE'='GLOBAL_SORT');
CREATE TABLE 小表(
id STRING,
city STRING,
name STRING,
cost STRING,
earnings STRING)
STORED BY 'carbondata'
row format delimited fields terminated by ','
TBLPROPERTIES (
'MAJOR_COMPACTION_SIZE'='512',
'AUTO_LOAD_MERGE'='true',
'COMPACTION_LEVEL_THRESHOLD'='4,3',
'SORT_COLUMNS'='earnings,cost,name,city,id',
'NO_INVERTED_INDEX'='earnings,cost,name,city,id',
'SORT_SCOPE'='GLOBAL_SORT');
以上是建表的优化
加载数据的优化
load data inpath '/opt/1.csv' into table kldss.大表 OPTIONS('GLOBAL_SORT_PARTITIONS'='1','HEADER'='false');
load data inpath '/opt/1.csv' into table kldss.小表 OPTIONS('GLOBAL_SORT_PARTITIONS'='1','HEADER'='false');
创建表完成后,load 数据完成后执行下面三个
show segments for table table; #显示表中的分片 该命令用于获取CarbonData表的段
ALTER TABLE tableCOMPACT 'MAJOR'; #启动手动压缩,压缩会提高查询的速度
clean files for table table; #删除Compacted 压缩文件
压缩
ALTER TABLE test COMPACT 'MINOR' (有三种方式,具体的可以看文档)。
在压缩完成之后清理 segments
清理已经压缩的 segments:
CLEAN FILES FOR TABLE test.test_6;
还有carbondata 支持update和delete
clean files for table xxx 删除数据的时候会产生很多deletedelta文件,会影响删除的速度,可以删除表的deletedelta文件。
locks文件什么时候会自动删除? 无效或被删除的segment lock才会被删除,默认是2天前的好像,在加载数据的时候会产生。
最后我新建了两张表,数据还是不变,看看查询的速度,查询速度不到两秒(大表1700W,小表4000条)

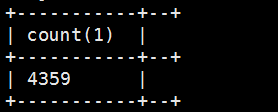
优化前的速度
![]()
优化后的查询速度。
![]()
还有一种场景,load数据和inset into table partition (date='20101212') select cloumn from table 的查询速度是一样的,这个我做过测试。
遇到的一些问题
1.carbondata数据加载,要上传到hdfs,本地现在无法加载数据,会报文件找不到
答:是的现在只能把csv文件上传到hdfs,才可以加载数据到carbondata的表中。
2.添加分区字段
答:alter table carbon_yw_data_detail_4 if not exists add partition (driverdate='20180808');
3.压缩可以显着地提高查询性能,有三种类型的 Compaction ALTER TABLE [db_name.]table_name COMPACT 'MINOR/MAJOR/CUSTOM' (具体可以看官网)
答:show segments for table test; #显示表中的分片 该命令用于获取CarbonData表的段
ALTER TABLE test COMPACT 'MAJOR'; #启动手动压缩,压缩会提高查询的速度
clean files for table test; #删除Compacted 压缩文件
4.是不是一个segment可以包含多个.carbondata文件?
答:是的,在hdfs上可以看到,这个是的,可以多个,看node数,分区数,然后会有一个carbonindexmerge文件,这个是该segment的索引文件,一个segment可能会有多个carbondata文件,看配置和加载数据的大小。
5.carbon.compaction.level.threshold=4,3
答:对多批次导入数据,可以做压缩,这样索引效果会更好。每4个合并一次,每4个合并后的3个再合并一次。
insert into 50次压缩一次 连续5次在压缩一次 carbon.compaction.level.threshold=50,5
这个y合并的是x的segment,进行5次x合并后就触发y合并,就是对原始segment达到50时进行x合并,当x的segment达到5时,触发y合并 这么理解对吗,是的。这样理解是吧,没合并前这个segment是level1,合并一次就是level2了,那个3就代表3个level2会进行合并,支持表级别和配置级别。
6.GLOBAL_SORT: 这会增加数据的查询性能,特别是高并发查询。如果你特别关心加载资源的隔离时使用,
答:因为系统使用 Spark 的 GroupBy 对数据进行排序,我们可以通过 Spark 来控制资源。
7.物化视图,可以优化查询的速度。
答:使用物理化视图,就是可以把where后面的条件放到dataMap中,然后where条件就不需要全表扫描,具体的类CompactionSupportGlobalSortParameterTest.scala.
8. carbondata数据导出csv文件。
答:beeline -u jdbc:hive2://192.168.1.100:10000 --showHeader=false --verbose=true --outputformat=csv2 -e "select * from test
where jwd=1 and driverdate=20181201">>/opt/cs1.csv.
9.carbondata数据导出csv文件,数据要上传hdfs
答:load data inpath '/opt/20181202.csv' into overwrite table test partition (driverdate='20181202') OPTIONS('GLOBAL_SORT_PARTITIONS'='2','HEADER'='false');
10.删除分区的时候,在表中可以删除,show partitions test 是没有已经删除的分区,但是在hdfs中是有的。
答:clean files for table test; 然后刷新hdfs界面就不会显示已经删除的分区了。
删除分区的命令 ALTER TABLE test DROP PARTITION (driverdate='20181202')
11.(GLOBAL_SORT_PARTITIONS'='2')和(GLOBAL_SORT_PARTITIONS'='1')
答:但是load上传文件大小小于block size时,这个参数是不是就不起作用了同样的数据量,分区多,文件肯定多。类似spark中的repartition(4) 这样就有4个分区也就是说,我将多个小的分区合并成大的分区,我设置成2,就是2个大的分区,是的。比如1G文件,hdfs block size 是128M,那么就有8个分区,此时设置为2,那就会把4个分区的数据合并为1个。
12. locks文件什么时候会自动删除?
答:无效或被删除的segment lock才会被删除,默认是2天前的好像,在加载数据的时候会产生。
13.删除数据的时候会产生deletedelta
答:clean files for table xxx; 删除表的deletedelta文件
14. carbon.compaction.level.threshold 参数针对的是segment数和分区不分区没有关系
答:针对的是分割segment,alter table major是根据分割segment size来的,你说的那个4,如果开启自动和,当load第四次后,就会自动把前4个segment compact。
15.是不是一个segment可以包含多个.carbondata文件。
答:是的一个segment可能会有多个carbondata文件,看配置和加载数据的大小。
16.hive 的metadata db
答:是把hive-site.xml 放在编译后的conf文件中吧,这个我漏了写了,是,要从cdh的配置中拷出来,放的位置/opt/spark-2.3.2-bin-2.6.0-cdh5.15.2/conf
17.drop partition时,会不会同delete一样产生一些文件
答:会的
18.clean files 与load 冲突。
答:不会
19.carbondata 查询union all
答:这个我测试过两张大表union all 总共8000W条数据查询速度4秒(load 加载数据和inset select 查询的速度是一致的)
20.streaming怎么部署
答:这个问题我还没有解决。