李宏毅学习笔记31.GAN.02.Conditional Generation by GAN
文章目录
- 简介
- Text-to-Image
- Traditional supervised approach
- Normal GAN
- Conditional GAN
- 算法
- Conditional GAN - Discriminator
- 作业实例
- Stack GAN
- Image-to-image
- 传统做法
- Conditional GAN
- Patch GAN
- Speech Enhancement
- 传统做法
- Conditional GAN
- Video Generation
简介
上节讲了GAN,GAN的主要作用是用来做生成对象,输入向量,得到对应的对象,但是生成的对象无法控制,因此本节来讨论如何考虑控制生成对象。Conditional GAN和GAN的Generator是一样的,差别就是在Discriminator。
公式输入请参考:在线Latex公式
先来看个文字生成图片的例子:
Text-to-Image
Traditional supervised approach
用传统的做法来怎么做?• Traditional supervised approach

以上是数据的例子,我们训练一个NN,然后输入一个文字,输出对应一个图片,我们希望图片与目标图片越接近越好。

这样做有什么问题?我们来看一下,例如文字:train对应的图片有很多张。例如下面的火车有正面,有侧面的,如果用传统的NN来训练,模型会想让火车长得像左边,又像一个右边的,这样的结果是不好的。模型会想产生多张图像的平均,结果就会很模糊。

Normal GAN
如果是用GAN来做:
先用Generator来生成图片,输入是两个:一个是条件,一个是从某个分布中sample出来的向量。

然后Discriminator来判断图片是否是生成的:

Generator will learn to generate realistic images ….
But completely ignore the input conditions.
这样做是有问题的,因为Discriminator只会根据生成的图片是否清晰,是否真实来进行判别,所以Generator 只会按这个标准来生成图片,而没有去按条件(例如:火车)来生成图片。
Conditional GAN
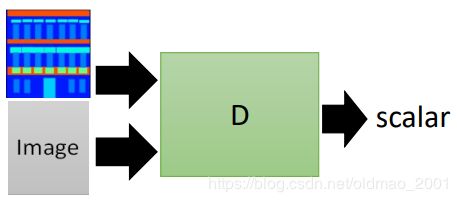
因此要改进为Conditional GAN,这个时候Generator的部分不变,但是Discriminator要改为:

这里的Discriminator吃两个输入:一个是条件,一个是要判断的图片对象。输出是一个向量,输出向量要判断两个事情:
x is realistic or not + c and x are matched or not
下面是输出向量的例子:

算法
·In each training iteration:
Learning Discriminator
·Sample m m m positive examples { ( c 1 , x 1 ) , ( c 2 , x 2 ) , ⋯ , ( c m , x m ) } \{(c^1,x^1),(c^2,x^2),\cdots,(c^m,x^m)\} {(c1,x1),(c2,x2),⋯,(cm,xm)} from database. 这里是Conditional GAN所以每个样本包含两个东西,都是image和text的pair。这个是真实样本,要给高分的
·Sample m m m noise samples { z 1 , z 2 , ⋯ , z m } \{z^1,z^2,\cdots,z^m\} {z1,z2,⋯,zm} from a distribution
·Obtaining generated data { x ~ 1 , x ~ 2 , ⋯ , x ~ m } , x ~ i = G ( c i , z i ) \{\tilde x^1,\tilde x^2,\cdots,\tilde x^m\},\tilde x^i=G(c^i,z^i) {x~1,x~2,⋯,x~m},x~i=G(ci,zi).这里是生成对象,要给低分
·Sample m m m objects { x ^ 1 , x ^ 2 , ⋯ , x ^ m } \{\hat x^1,\hat x^2,\cdots,\hat x^m\} {x^1,x^2,⋯,x^m} from database
·Update discriminator parameters θ d \theta_d θd to maximize
V ~ = 1 m ∑ i = 1 m l o g D ( c i , x i ) + 1 m ∑ i = 1 m l o g ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m l o g ( 1 − D ( c i , x ^ i ) ) \tilde V=\cfrac{1}{m}\sum_{i=1}^mlogD(c^i,x^i)+\cfrac{1}{m}\sum_{i=1}^mlog(1-D(c^i,\tilde x^i))+\cfrac{1}{m}\sum_{i=1}^mlog(1-D(c^i,\hat x^i)) V~=m1i=1∑mlogD(ci,xi)+m1i=1∑mlog(1−D(ci,x~i))+m1i=1∑mlog(1−D(ci,x^i))
θ d ← θ d + η ▽ V ~ ( θ d ) \theta_d\leftarrow \theta_d+\eta\triangledown\tilde V(\theta_d) θd←θd+η▽V~(θd)
这里和上节中的GAN算法就是多了最后一项,就是图片和文本不对应也是给低分。
Learning Generator
·Sample m m m noise samples { z 1 , z 2 , ⋯ , z m } \{z^1,z^2,\cdots,z^m\} {z1,z2,⋯,zm} from a distribution
·Sample m m m conditions { c 1 , c 2 , ⋯ , c m } \{c^1,c^2,\cdots,c^m\} {c1,c2,⋯,cm} from a database
·Update generator parameters θ g \theta_g θg to maximize
V ~ = 1 m ∑ i = 1 m l o g ( D ( G ( c i , z ) ) ) , θ g ← θ g + η ▽ V ~ ( θ g ) \tilde V=\cfrac{1}{m}\sum_{i=1}^mlog(D(G(c^i,z^))),\theta_g\leftarrow \theta_g+\eta\triangledown\tilde V(\theta_g) V~=m1i=1∑mlog(D(G(ci,z))),θg←θg+η▽V~(θg)
Conditional GAN - Discriminator
常见的Discriminator构架如下图,把x丢到一个NN里面得到一个向量表示,然后把文字丢到一个NN里面得到一个向量表示,把两个向量concat起来之后,丢到一个NN里面得到具体的分数。

但是有三个文章提出来的Discriminator构架貌似效果也还不错:
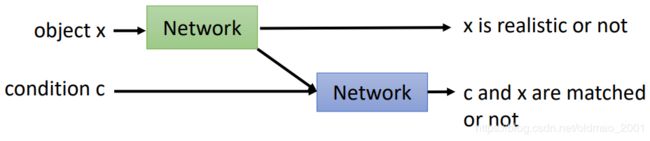
感觉有点像之前讲的魔主化的东西。把一个x丢到一个NN里面,出来一个结果:x是否是真实对象。另外还出来一个向量表示(embedding),然后把条件文本和刚才的向量表示丢到另外一个NN(这个NN同时看到两个东西)里面,得到对象和文本是否匹配的结果。
比起上面模型而言,上面模型虽然能work,但是给出的分数并没有告诉我们为什么得到这个分数。下面的模型则可以看出来,是不匹配,还是生成对象有问题。
[ Augustus Odena et al., ICML,2017]
[ Takeru Miyato, et al., ICLR,2018]
[ Han Zhang, et al., arXiv,2017]
作业实例
学生做的效果:


可以看到里面有些图片翻车,右下角那个图片的眼睛一个红一个蓝。
Stack GAN
先生成小图,再生成大图。
大概流程:先有一个Generator1吃文字描述(先要embedding变成 φ t \varphi_t φt)生成一个64×64的小图片,然后经过一个Discriminator1,判断小图片和文字是否匹配,如果匹配,进入Generator2,吃小图片和 φ t \varphi_t φt,然后得到大图片,然后经过一个Discriminator2,判断大图片和文字是否匹配
文献:Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas, “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks”, ICCV, 2017
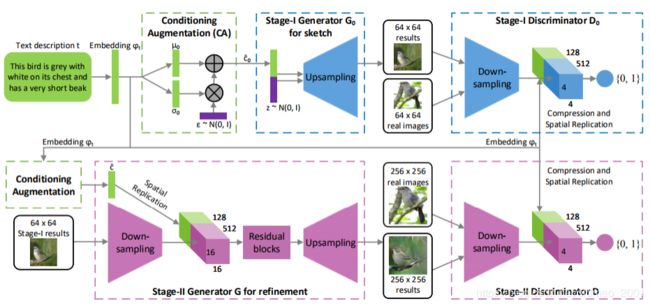
可以把以上过程重复多次,有论文生成1024×1024的超级大图。
Image-to-image

可以有很多用途,白天变黑夜,黑白变彩色等,例子:
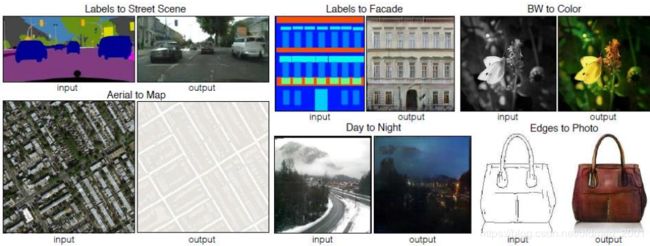
文献:https://arxiv.org/pdf/1611.07004
传统做法
先收集大量的样本:

然后训练模型:

在测试的结果却很模糊,原因在上面有讲:It is blurry because it is the average of several images.

Conditional GAN
Generator:
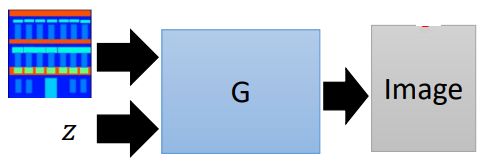
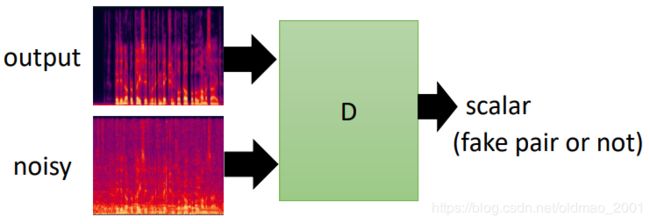
Discriminator,这里注意要吃两个东西,条件和要判断的对象:
看到使用条件GAN生成的结果更加清晰了,但是这里有点问题,就是左上角那里多了一些东西

因此可以针对这个进行改进,在Generator生成对象的时候加上限制,要使得生成的对象与真实对象越接近越好:

最后结果:

Patch GAN
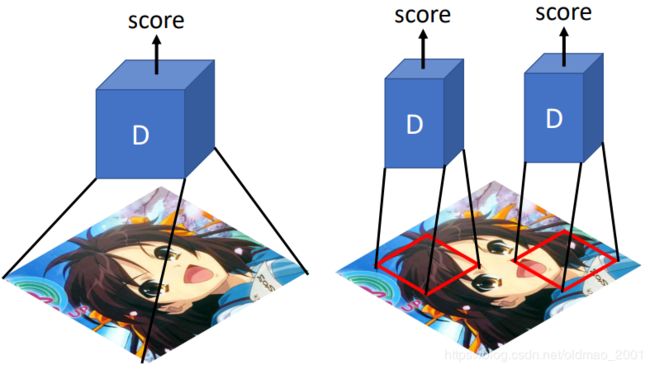
当用一个Discriminator来进行评估整个大张的图片的时候会有很多问题:容易overfitting,训练时间长。因此可以用多个Discriminator来进行评估。每个Discriminator检查的区域的大小是超参数。不能太小例如一个pixel那么整个图片就会糊掉。
文献:https://arxiv.org/pdf/1611.07004.pdf
Speech Enhancement
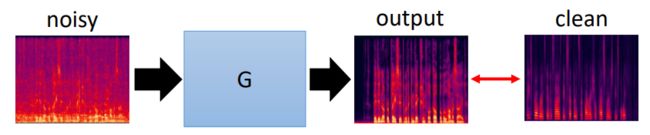
给一段声音去掉噪音

传统做法
先要有数据:

然后训练一个NN,注意这里会直接套CNN

效果当然不好,要用条件GAN
Conditional GAN

Generator:
Discriminator:
Video Generation
看一段影片,然后预测接下来发生什么事情。

还有用GAN来玩游戏,如果不用GAN,就是会有问题,例如角色往左或者往右都是正确的,那么用传统的学习得到的结果就是进行平均,然后角色就会定住不动。