李宏毅学习笔记37.GAN.08.Intelligent Photo Editing
文章目录
- 简介
- 前情回顾
- 具体实现
- 1.GAN+Autoencoder
- 2.Attribute Representation
- 具体实例
- Basic Idea
- Back to z
- 第一种
- 第二种
- 第三种
- Editing Photos
- 其他应用
- 高清图片处理Image super resolution
- 图像补全Image Completion
简介
公式输入请参考:在线Latex公式
有大神做了一个DEMO
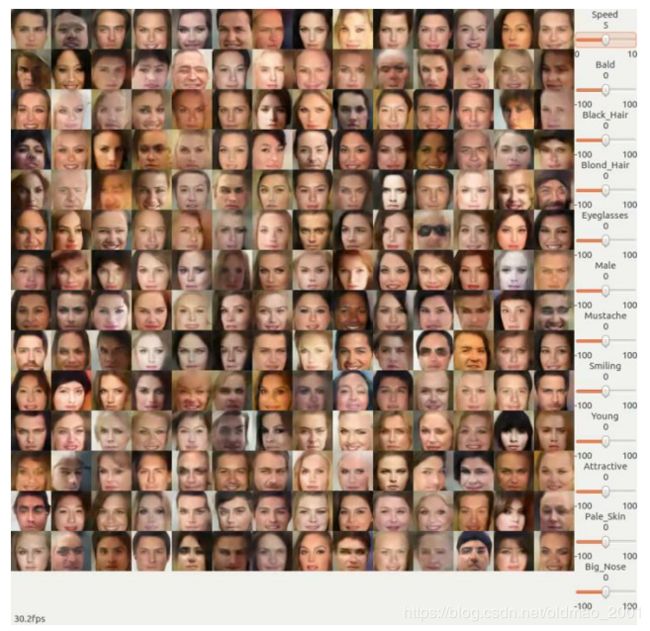
右边的bar是调整各种属性,例如:头发颜色,头发浓密,胡子,性别,皮肤颜色、笑的表情等,左边就会根据特定的属性值生成对应的图片。这节就是来学习这个demo的原理:Photo Editing
前情回顾
➢The input code determines the generator output.
➢Understand the meaning of each dimension to control the output.
之前学习GAN,我们知道,可以用一组随机向量来生成一个图片:
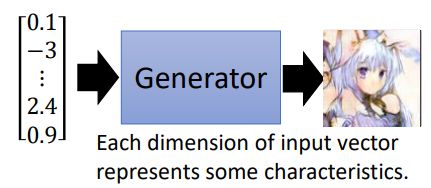
这个向量每一个维度实际上是对应了图片中不同的特征的,例如:
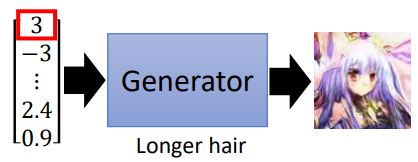

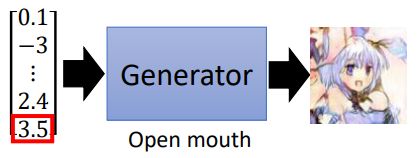
我们如果能知道每个维度对应图片哪个特征,就可以控制生成图片的输出。
具体实现
1.GAN+Autoencoder
• We have a generator (input z, output x)
通常我们可以训练一个generator,通过随机向量z来生成图片x

• However, given x, how can we find z?
从图片x中可以得到相应的特征标记,例如:头发颜色,头发浓密,胡子,性别,皮肤颜色、笑的表情等,如果我们能知道是什么样的z生成的x,就可以吧x中的某些维度和图片的特征联系起来。
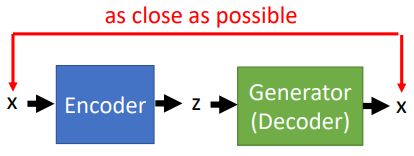
• Learn an encoder (input x, output z)
要知道z,就是要训练一个Encoder ,输入一张图片x,得到z,z经过上图中的Generator后可以还原回图片x。典型的Autoencoder结构:
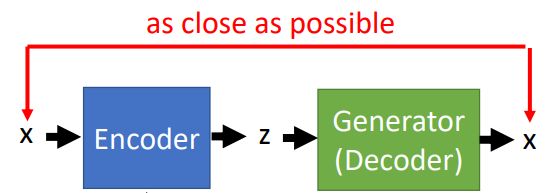
训练Encoder的时候,由于是要反推z,所以这里Generator中的参数是固定不变的。由于Encoder在上图中和Discriminator的功能相似,所以在实际计算的时候,可以用Discriminator来对Encoder进行初始化。
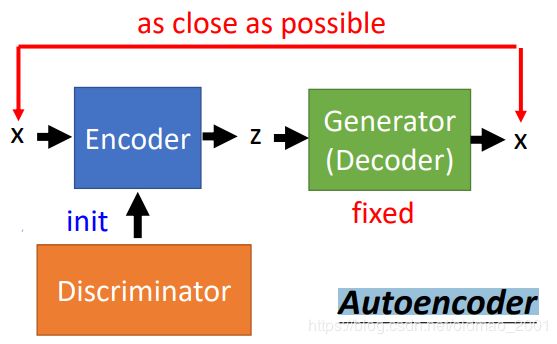
2.Attribute Representation
完成上面的工作,我们就训练好了一个Encoder,这个Encoder可以把图片还原为一个向量。也就是用这个Encoder可以找到生成某个图片的向量。
接下来把数据库中的图片整出来:

丢到Encoder中,得到这些图片对应的向量(注意蓝色和绿色的点就是向量)

对于左边的图片是长发,右边是短发,把两簇向量取平均后得到长短发的代表,然后相减:
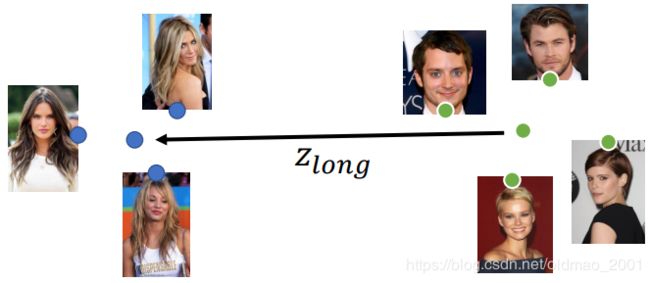
得到短发与长发的差异,也就是说短发向量加上上面的 z l o n g z_{long} zlong就变成长发。用数学公式描述这一过程为:
z l o n g = 1 N 1 ∑ x ∈ l o n g E n ( x ) − 1 N 2 ∑ x ′ ∉ l o n g E n ( x ′ ) z_{long}=\cfrac{1}{N_1}\sum_{x\in long}En(x)-\cfrac{1}{N_2}\sum_{x'\notin long}En(x') zlong=N11x∈long∑En(x)−N21x′∈/long∑En(x′)
其中En是Encoder,long代表长发。如果现在有一张短发的图片x,我们可以通过下面的步骤把其变成长发:
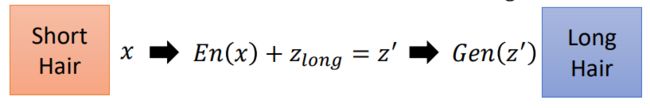
将x丢到Encoder中得到x对应的向量z,加上 z l o n g z_{long} zlong后变成 z ′ z' z′,经过Generator,就可以得到对应的长发图片。
具体实例
Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman and Alexei A. Efros. “Generative Visual Manipulation on the Natural Image Manifold”, ECCV, 2016.
Andrew Brock, Theodore Lim, J.M. Ritchie, Nick Weston, Neural Photo Editing with Introspective Adversarial Networks, arXiv preprint, 2017
Basic Idea
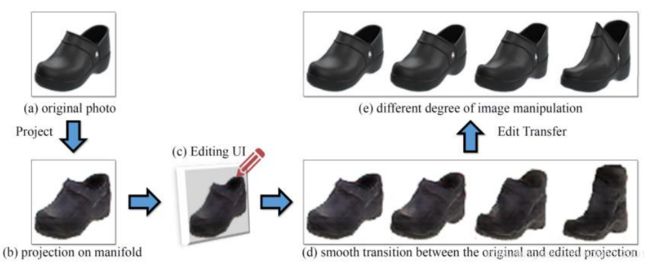
类似上图的编辑效果是如何做到的呢?原理就在下图中:
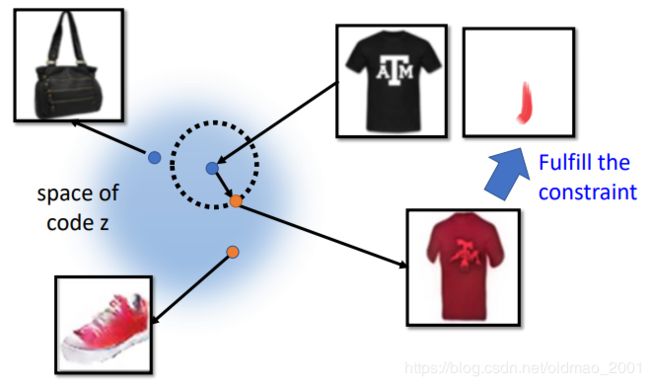
我们能找到生成商品图片的向量都是从z的向量空间中取的,那么如果我们将生成图片的z在一个小的范围内进行移动,这个商品的图片肯定不会变化太多,如果再加上编辑的约束,就会使得图片变成我们想要的样子。
Back to z
同样的,现在要考虑如何找到图片对应的code。
有三种方法:
第一种
把寻找code的过程看做最优化的过程
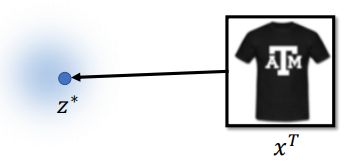
z ∗ = a r g min z L ( G ( z ) , x T ) z^*=arg\underset{z}{\text{min}}L(G(z),x^T) z∗=argzminL(G(z),xT)
要找z,通过G(z)后得到一个图片,我们希望这个图片和 x T x^T xT越接近越好,衡量接近(二者差距)程度用函数L表示。常见的衡量方法有:
Pixel-wise:逐像素比较
By another network:用一个NN来进行转化后比较。(把图片都丢到一个类似Encoder的网络可以得到向量表示。)
然后用梯度下降求解这个最优化方程。
第二种
就是本课中用的方法,训练一个Encoder来找z
第三种
将第一种和第二种方法相结合。
Using the results from method 2 as the initialization of method 1
这样可以避免GD过程中遇到局部最优点。
Editing Photos
可以找到图片对应的z之后,我们继续来看如何进行编辑,假设现在有一个图片(左边),和一个用户编辑的约束(右边):
图片对应的code是 z 0 z_0 z0,那么最后要满足下面的式子:

其中第一项:U代表用户做的编辑约束,这里要使得图片尽量的满足用户的编辑约束,例如用户用的红色点了一下,生成的新图片就是要红色基调,这里如何定义一个图片满足某个约束的函数由我们自己来弄。
第二项:是使得新生成的图片不能脱离原图片太远。
第三项:使得新生成的图片越真实越好。
其他应用
高清图片处理Image super resolution
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi, “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”, CVPR, 2016
Figure 2: From left to right: bicubic interpolation, deep residual network optimized for MSE, deep residual generative adversarial network optimized for a loss more sensitive to human perception, original HR image. Corresponding PSNR and SSIM are shown in brackets.[4x upscaling]
左一传统处理方法:不行
左二普通NN处理:效果可以,但是头饰,项圈细节还是模糊
左三GAN:效果可以,头饰,项圈细节清晰,但是这些细节和原图不一样,因为这些细节是GAN模型自己生成的,只要能骗过discriminator即可。
最后是原图
这个模型的数据比较好处理,就是找一堆高清图,处理模糊后就有数据了,因为图片清晰变模糊好弄。
图像补全Image Completion
这个模型的训练数据也好处理,随便找图片,然后挖空就有了。模型思想是:conditional GAN
http://iizuka.cs.tsukuba.ac.jp/projects/completion/en/

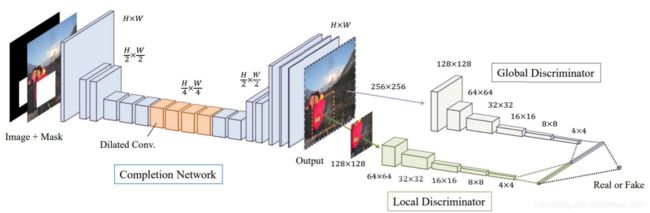

额,老G出没。。。
效果比较
