每个程序员都应该了解的内存知识

AlfredCheung
|
|
| 其它翻译版本(1) |

Tina买了好多鱼
|
|
| 其它翻译版本(1) |
AlfredCheung
|
|
| 其它翻译版本(1) |
AlfredCheung
|

キョン
|

knarfytrebil
|
knarfytrebil
|

Tocy
|
AlfredCheung
|
AlfredCheung
|
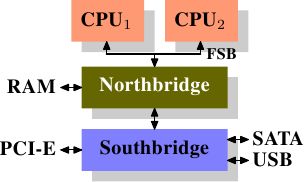
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
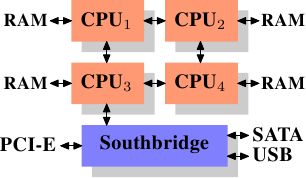
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
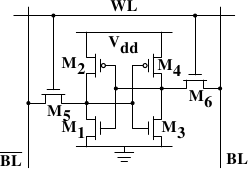
AlfredCheung
|


王政
|
![[Formulas]](http://img.e-com-net.com/image/info8/8a86e6413000476aa20928d7fb60d6cb.jpg)
王政
|
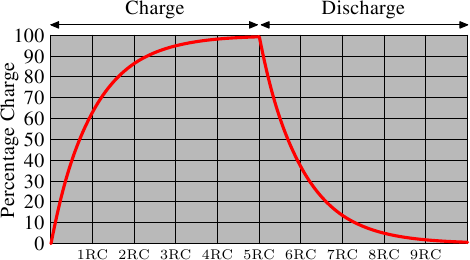

唐柯德
|
唐柯德
|
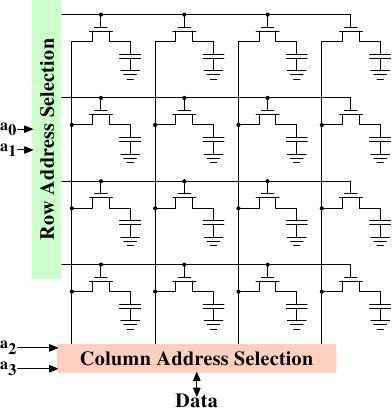
キョン
|

Fun.S
|
Tina买了好多鱼
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
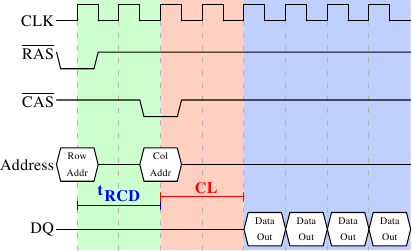
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
|
| 其它翻译版本(1) |
AlfredCheung
|
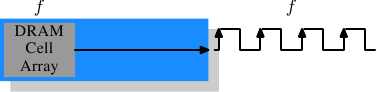
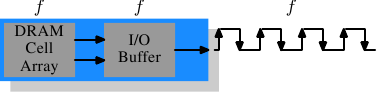
AlfredCheung
|
AlfredCheung
|
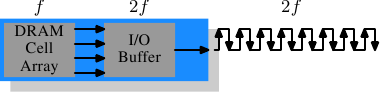
AlfredCheung
|
AlfredCheung
|
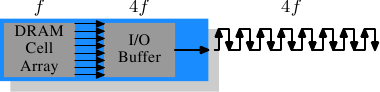
AlfredCheung
|
Fun.S
|
|
| 其它翻译版本(1) |
AlfredCheung
|
AlfredCheung
|
Fun.S
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

hanQ
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
|
| 其它翻译版本(1) |
AlfredCheung
|

elilien
|
AlfredCheung
|

elilien
|
AlfredCheung
|

AlfredCheung
|


我勒个去真烦人
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|

2007robot
|

sundaqing
|

RoyChen
|

928171481
|

daleshen128
|
AlfredCheung
|
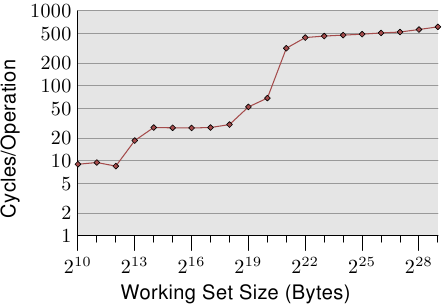
AlfredCheung
|
daleshen128
|
|
| 其它翻译版本(1) |
daleshen128
|
|
| 其它翻译版本(1) |

daleshen128
|
daleshen128
|

daleshen128
|

daleshen128
|
daleshen128
|

daleshen128
|
AlfredCheung
|
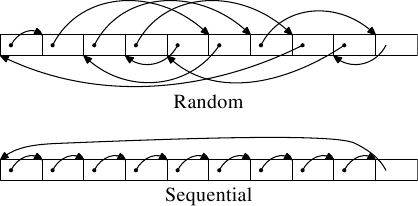
sundaqing
|
sundaqing
|
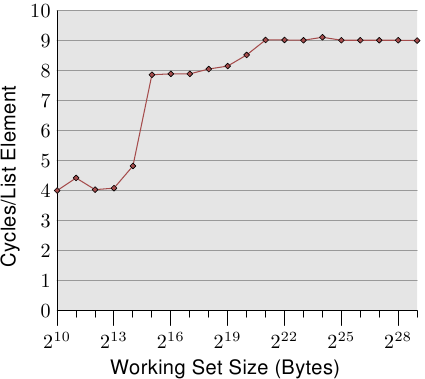

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
sundaqing
|

artistjuran
|
artistjuran
|

AlfredCheung
|
AlfredCheung
|
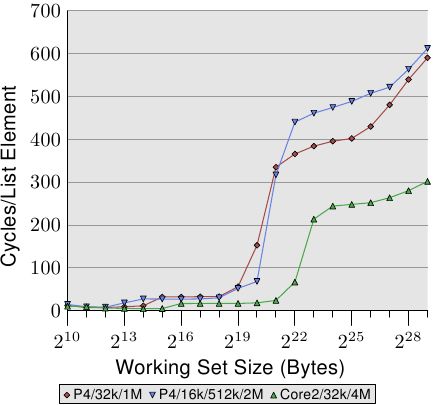
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|


AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

等PM
|
等PM
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|

AlfredCheung
|

AlfredCheung
|

AlfredCheung
|
AlfredCheung
|

KevinJen
|
|
| 其它翻译版本(1) |

AlfredCheung
|
|
| 其它翻译版本(1) |
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

李东华
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
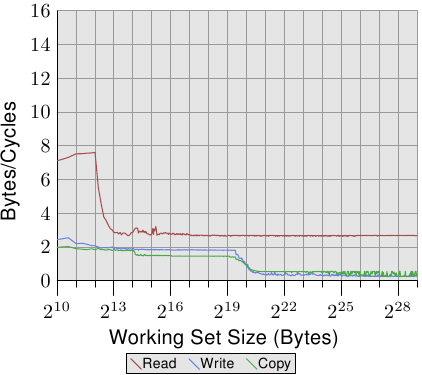
AlfredCheung
|

AlfredCheung
|

AlfredCheung
|
AlfredCheung
|
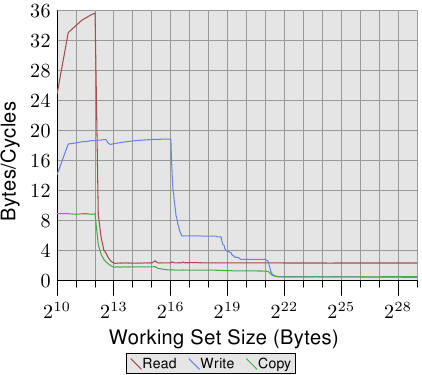
AlfredCheung
|
AlfredCheung
|
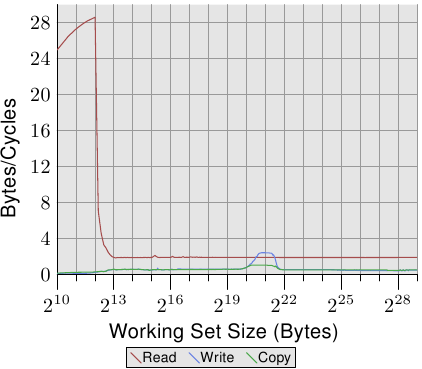

super0555
|
AlfredCheung
|
AlfredCheung
|

等PM
|

Khiyuan
|
AlfredCheung
|
AlfredCheung
|
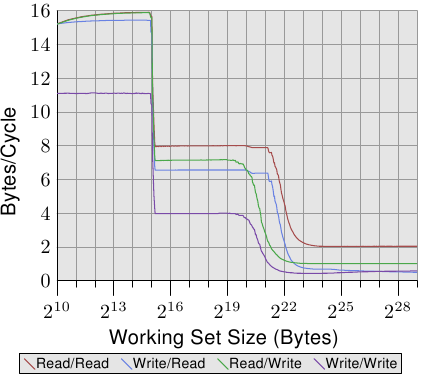
AlfredCheung
|
AlfredCheung
|
AlfredCheung
|

super0555
|
super0555
|
super0555
|
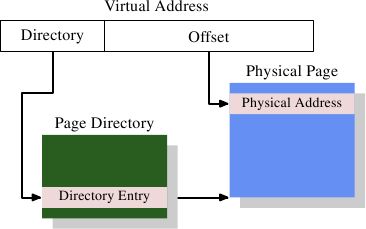
super0555
|
super0555
|
super0555
|
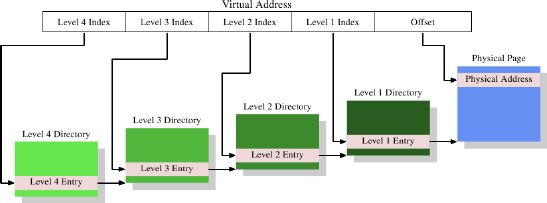
super0555
|
super0555
|
|
| 其它翻译版本(1) |
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
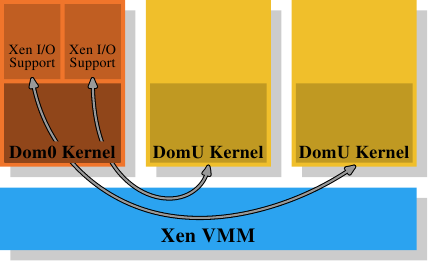
super0555
|
super0555
|
super0555
|
super0555
|
super0555
|
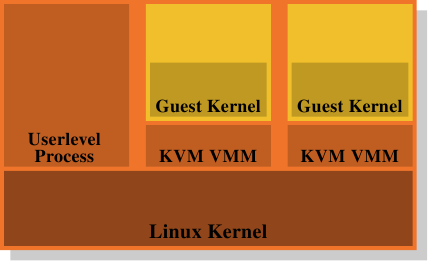
super0555
|