语义分割之SegNet,Bayesian SegNet
天下难事,必作于易;
天下大事,必作于细;
是以圣人不以为大,故能成其大。
——《老子》
论文:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding
官网:http://mi.eng.cam.ac.uk/projects/segnet/#demo
Github:https://github.com/alexgkendall/caffe-segnet
https://github.com/alexgkendall/SegNet-Tutorial
主要贡献:
SegNet论文提出了max pooling的改进版,使用该pooling操作既可以进行下采样操作,也可以进行上采样操作。在下采样操作中同时输出pooling后的结果和pooling过程中的索引。在上采样操作中,利用下采样对应位置的索引,进行上采样操作,这样的优势在于记住了最亮特征像素的空间位置。
优点,
- 可以提高物体边界的分割效果
- 相比反卷积操作,减少了参数数量,减少了运算量,相比resize操作,减少了插值的运算量,而实际增加的索引参数也很少。
- 该pooling操作可以应用于任何基于编码-解码的分割模型。
Bayesian SegNet沿用了SegNet的网络结构,在此基础上网络结构增加了dropout层。后处理增加了贝叶斯决策。多次的前向运算,可以得到多个输出结果。对这些结果求均值就是最终预测的分割结果,求对应位置的像素的方差,就得到模型的不确定性图。当然也可以使用蒙特卡洛采样,得到最优的输出,可以将分割精度提升2-3%。
网络结构:
SegNet:

Bayesian SegNet:
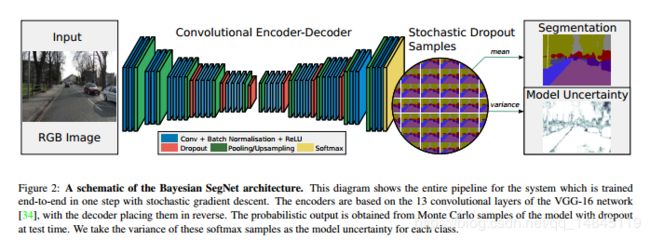
SegNet和DeconvNet的区别:
DeconvNet具有全连接层,会增加好多参数量,SegNet没有。
SegNet和Unet的区别:
Unet上采样使用反卷积,而SegNet使用自己提出的pooling。Unet没有conv5和maxpooling5,而SegNet有。
SegNet和Bayesian SegNet的区别:
Bayesian SegNet在SegNet模型的基础上在编码模块和解码模块都增加了dropout层,dropout_ratio都是0.5,其余部分结构完全一样。
网络的模型训练方式一样。但是后处理部分,区别很大。正常的网络训练都是在训练的时候加入dropout,在测试的时候去掉dropout。但是Bayesian SegNet在训练和测试的时候都需要加dropout。训练的时候加很好理解,测试的时候加,是为了保证每次输入相同的图像,但是得到的分割结果却不一样,有种模型集成的思想在里面。这样测试的时候,让同一张图片经过多次前向运算,就可以得到多个不同的分割结果输出。对这些结果求平均就是最终的分割结果,求方差就是模型预测的不确定性。分割结果权值求平均是一种思路,也可以使用蒙特卡洛算法,在多个预测的结果中,找到最优的结果。
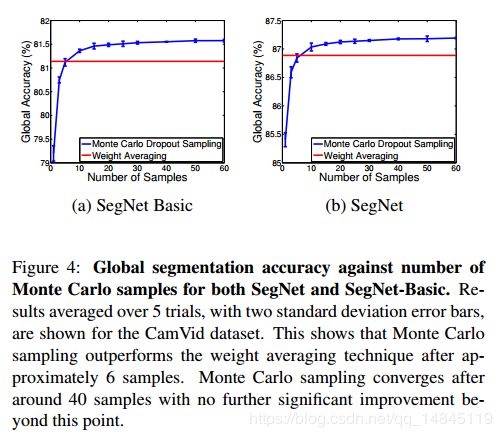
虽然使用权值求平均和蒙特卡洛采样都可以实现最终的结果。但是在精度上还是有区别。权值平均的方法,精度基本恒定。蒙特卡洛的方法在采样样本为6的时候,两种精度一样。大于6的时候,蒙特卡洛效果好于权值平均。大于40的时候,蒙特卡洛的精度基本保持恒定。小于6的时候,蒙特卡洛的效果比权值平均要差。
这整个过程的缺点就是需要对一张图进行多次的前向操作运算,那么这个该怎么改进呢?个人的一些见解,
- 论文的思路,使用显卡走并行运算
- 修改dropout层,使得可以同时输出多个的随机结果
- 修改网络结构,dropout部分修改为多个dropout分支结构,对多个分支的结果进行整合。
- 对于模型的不确定性,可以不使用多个输出求方差计算。而是像YOLO或者IOU-Net预测框的得分那样,预测每一个像素分类的不确定性得分。使用该得分和分割的结果得分做element-wise乘法操作,输出的结果作为最终的分割结果,实现op的loss传递。
SegNet中pooling和FCN中deconv对比:
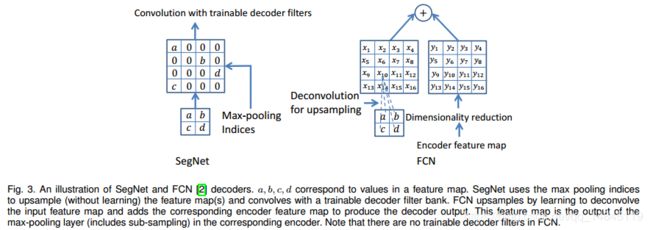
该上采样的pooling操作会根据对应位置的下采样的pooling的索引来生成上采样的特征图。直接根据索引位置插值就可以。
Deconv操作,会根据训练过程自己学习到上采样的参数。
模型不确定性:

- 每一个类别的边界都回表现出大的模型不确定性。
- 视觉不容易区别的物体,或者视觉上容易混淆的类别之间,表现出大的模型不确定性。
- 图片中一个类别出现的频率小,也回使得模型对该类别表现出模型不确定性。
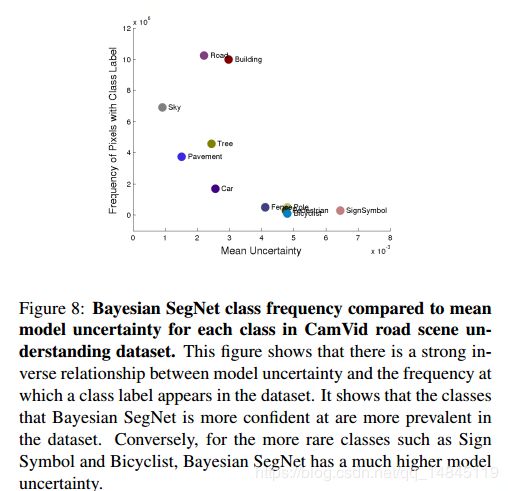
那么为什么需要这个不确定性的特征图呢?
大部分的分割场景可能不需要,只需要一个分割结果就可以,但是对于自动驾驶等需要知道分割准确性的场合,就需要这样一个不确定性特征图了。通过不确定性可以间接反馈分割的准确性。不确定性越大,准确性可能越低。
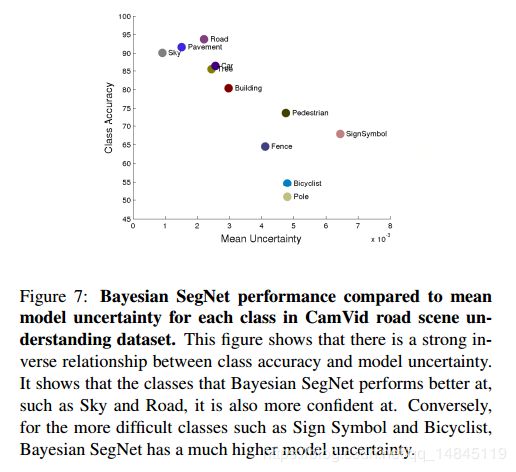
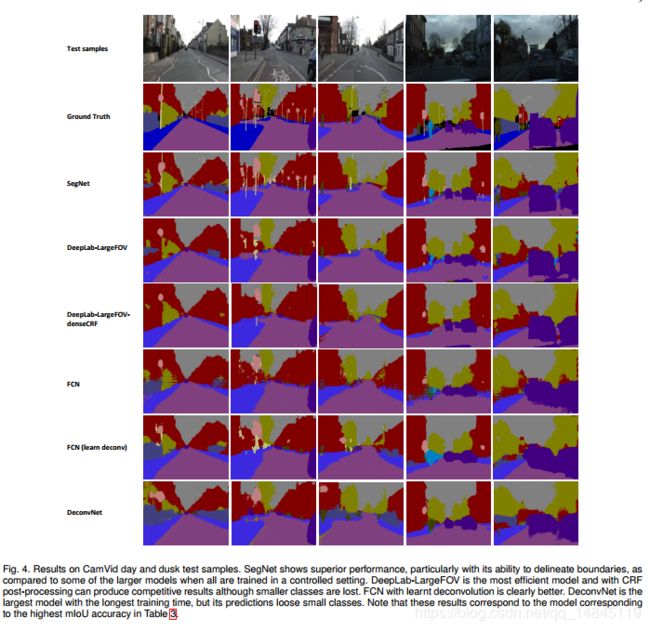
实验结果:

总结:
- 编码器部分的特征如果可以被很好的保存,例如本文的pooling操作,保存了其索引,可以取得很好的分割效果,尤其是在边缘部分。
- 本文的pooling操作可以解决推断过程中内存消耗大的问题。
- 对于给定的编码器,使用更大的解码器可以提升分割的精度。
- SegNet对边界细节分割效果非常好。
- Bayesian SegNet本质就是在SegNet基础上网络结构增加dropout,增加后处理操作。本质是一种模型集成。
后续探索:
- SegNet提出的pooling操作,为啥后续的分割框架算法没有采纳沿用下去?改进pooling和resize,deconv的实验区别,包括速度和精度,差别到底有多大?
- Bayesian SegNet的上文的几点改进想法验证,包括修改dropout op,修改网络结构分支,增加不确定性预测等。