Linux环境Tomcat部署Solr+导入Mysql数据+Ik分词+java使用solrj检索高亮实现代码全过程+suggest推荐
环境介绍:
阿里云CentOS 7.3
Apache Tomcat8.5
(安装路径:/usr/local/tomcat8.5)
Apache Solr7.5
(部署路径:/usr/local/tomcat8.5/webapps/solr)
(下载地址:http://www.apache.org/dyn/closer.lua/lucene/solr/7.5.0)
Apache Mysql 5.7.23
Solr不用过多介绍 用来实现全文检索功能 网上的Solr教程实在太少了 就出一套从安装到Java实现代码的过程吧!自己也踩了很多坑把使用的过程记录下来也给有需要的人学习一下,以前只是记录自己实现的过程,过程有很多种更便捷的方式去做,但是我这里就不写了,大家跟着这样下面这样做是觉得能实现功能的。Win系统登录Linux终端可以下载Git 或者其它。
一、Linux安装solr7.5并部署到Tomcat
进入/usr/local目录
cd /usr/local
下载solr
wget http://mirror.bit.edu.cn/apache/lucene/solr/7.5.0/solr-7.5.0.tgz
解压Solr文件
tar -zxvf solr-7.5.0.tgz
重命名为(solr)
mv -f solr-7.5.0 solr
Tips:
solr/bin/solr start -force 也可以运行
NOTE: Please install lsof as this script needs it to determine if Solr is listening on port 8983.
启动后可以看到端口是8983
输入服务器IP:8983可以访问solr admin页面(别忘记打开端口不然访问不到哦)
继续操作部署到Tomcat中这里我的tomcat目录路径/usr/local/tomcat8.5
首先tomcat建立一个solr文件夹并且进入到该目录
mkdir /usr/local/tomcat8.5/webapps/solr
cd /usr/local/tomcat8.5/webapps/solr
把solr中webapp拷贝到我们的tomcat拷贝过来
cp -f /usr/local/solr/server/solr-webapp/webapp/* .
创建一个solr core目录新增的core可以放在这里(不是非要放在tomcat路径下,看个人存储)
mkdir solr-home
cd solr-home
把Solr的数据拷贝过来
cp -r /usr/local/solr/server/solr/* .
创建core名字为doc_work等一下会用到
mkdir doc_work
cd doc_work
cp -r /usr/local/solr/server/solr/configsets/_default/conf/* .
编辑web.xml解决solr访问admin ui权限问题
vim ../WEB-INF/web.xml
在第一个filter前添加下面代码 env-entry-value地址换成上面一步自己创建的路径 solr-home
solr/home
/usr/local/tomcat8.5/webapps/solr/solr-home
java.lang.String
将这里代码注释掉
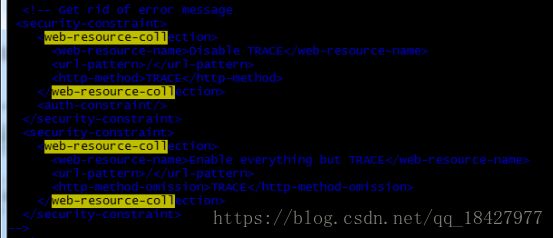
复制JAR包
cd ../WEB-INF/lib/
cp -r /usr/local/solr/server/lib/ext/ .
cp -r /usr/local/solr/server/lib/metrics*.jar .
cp -r /usr/local/solr/dist/solr-dataimporthandler-extras-7.5.0.jar .
cp -r /usr/local/solr/dist/solr-dataimporthandler-7.5.0.jar .
cp -r /usr/local/solr/dist/solr-clustering-7.5.0.jar .
创建classes目录把log4j.xml拷贝进去
mkdir ../classes
cd ../classes
cp -r /usr/local/solr/server/resources/log4j2.xml .
cp -r /usr/local/solr/server/lib/ext/* /usr/local/tomcat8.5/lib/
现在就算部署好Solr了我们启动Tomcat
浏览器访问:http://换成你的IP地址/solr/index.html
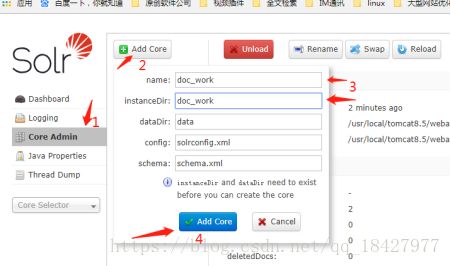
name instanceDir换成刚才创建的core目录名称,其它默认不变(这几个是什么意思不用介绍了吧 一眼就看懂了)
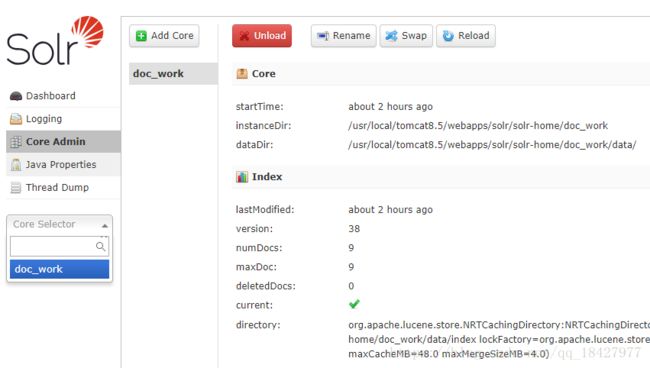
创建成功后可以在这里看到,如果你失败了不要怀疑什么肯定是你的插入姿势不对 google吧
二、导入mysql数据
有时候我们有很大的数据量需要直接导入,那么就在这里了,完成上面一步才能继续操作这里。
因为要用到Mysql所以我们要把连接的驱动放到Tomcat下Solr目录Lib包中(ps:这里驱动版本和你的Mysql版本你要确保能用哦)
mysql-connector-java-5.1.45.jar我下载好并且已经放进去了
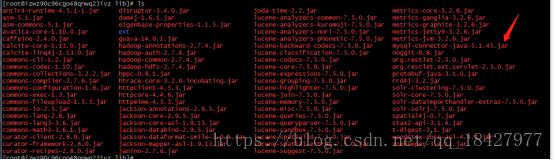
在doc_work目录下创建 data-config.xml
创建直接vim data-config.xml 或者 vi data-config.xml命令即可
vim data-config.xml
复制并修改以下内容到vim保存(把下面jdbc连接名户名密码换成自己的,还有要查询的表以及字段,要记住这里的field name等下还要用到)
下面把data-config.xml引用添加到solrconfig.xml
vim solrconfig.xml
输入“/requestHandler” 回车 搜索代码块把下面代码放在一块方便管理。
data-config.xml
编辑managed-schema把刚才新增的data-config.xml中entity fileld字段添加到这里哦
这里的Name和data-config.xml中的Name对应 type自己对应吧 属性意思自行Google了解
这就算完成配置了 然后就是重启tomcat
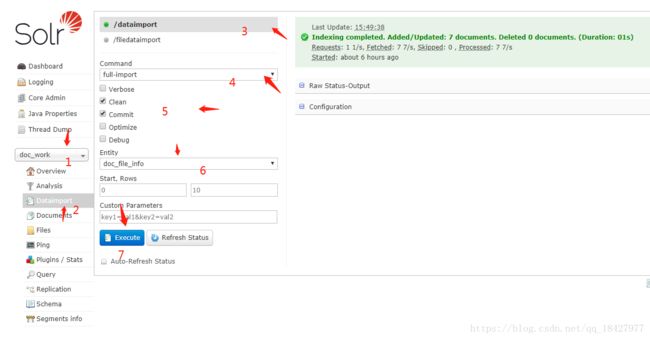
更深入的了解Google一下都有。然后查询数据看一下
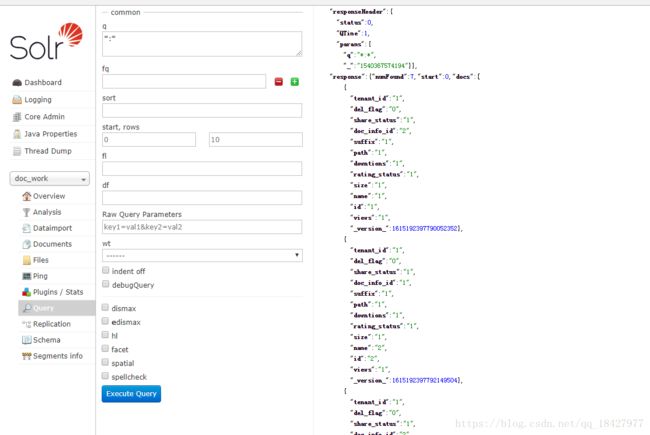
可以看到7条数据进来了 so easy
三、配置IK分词查询
为什么要用就不用说了,Solr也有自带中分分词但是觉得没Ik还用
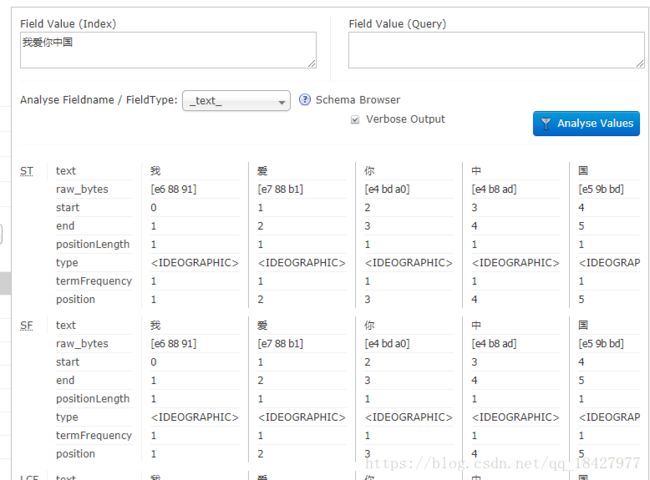
看一下普通的分词↓
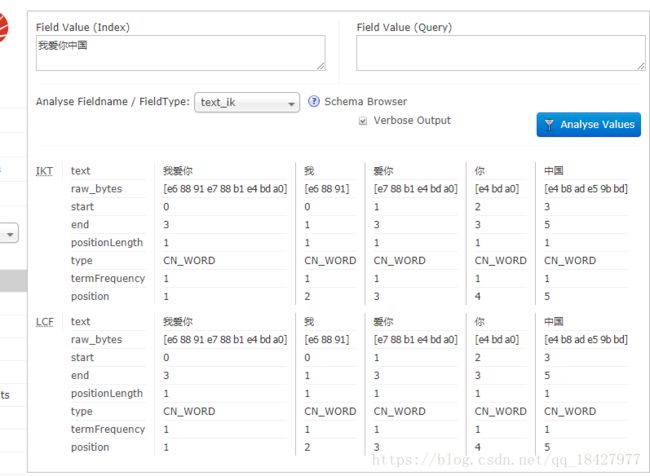
Ik分词是这样的 ↓
我们需要引用JAR包
下载地址:https://search.maven.org/remotecontent?filepath=com/github/magese/ik-analyzer-solr7/7.x/ik-analyzer-solr7-7.x.jar
还是放在你的Solr部署在tomcat的lib路径
在我们创建的core(doc_work)目录下找到managed-schema编辑添加
vim managed-schema
代码和上面一下输入/fieldType向下搜索一下放到一块的位置方便管理
添加该代码保存 哦对了 需要用ik分词的field type属性改成text_ik即可
例如:
完成以上步骤重启Tomcat即可使用
tips:
使用Ik的扩展配置在Solr目录下创建IKAnalyzer.cfg.xml
内容:
IK Analyzer 扩展配置
my.dic;
stopword.dic;
Tips:
my.dic即为扩展分词库,分词库可以为多个 以分号隔开即可。停止词库一样。
新增my.dic和stopword.dic文件。文件格式必需是:无BOM的UTF-8格式
这才算完成Ik分词的配置
四、使用solrj上传检索pdf word txt等文件
这部分写的是java中使用solrj并且服务器solr配置
先看solr配置吧。等会贴上来java Demo(spring boot +solrj实现检索)
doc_work目录下 编辑添加一下代码保存
创建 tika-data-config.xml
vim tika-data-config.xml
添加内容
把这两个里面的包拷贝到我们的solr-home目录下
cp -r /usr/local/solr/dist/ /usr/local/tomcat8.5/webapps/solr/solr-home
cp -r /usr/local/solr/contrib/ /usr/local/tomcat8.5/webapps/solr/solr-home
编辑solrconfig.xml找到lib dir 这里几个修改成我们自己的路径
vim solrconfig.xml
我这修改成:
编辑solrconfig.xml添加tika-data-config.xml引用
vim solrconfig.xml
内容:
tika-data-config.xml
编辑managed-schema增加字段(ps:已有的不用加了)
vim managed-schema
内容:
完成之后重启Tomcat
下面是使用solrj完成检索不解释了一个Demo写的很不好主要是打通过程直接上代码:
添加JAR(至于其他的spring包和其他用的包这里就不说了)
org.apache.solr
solr-solrj
7.5.0
application.yml
spring:
data:
solr:
host: http://你的IP/solr/doc_work
这里输入会有提示不要直接复制哈 省的空格什么错误
@Autowired
private SolrClient solrClient;
@RequestMapping(path = "/search")
public ModelAndView index(HttpServletRequest request) throws IOException, SolrServerException {
ModelAndView model = new ModelAndView();
String key = request.getParameter("key");
SolrQuery query = new SolrQuery();
query.set("q", "filename:" + key);
//query.set("q", "fileName:" + key + " " + "text:" + key);
query.set("fl", "filename,size,filepath,author,text,id");
query.setHighlight(true);
query.addHighlightField("text");
query.addHighlightField("filename");
//标记,高亮关键字前缀
query.setHighlightSimplePre("");
//后缀
query.setHighlightSimplePost("");
QueryResponse response2 = solrClient.query(query);
SolrDocumentList list2 = response2.getResults();
Map>> hi = response2.getHighlighting();
List fileList = new ArrayList();
for (SolrDocument document : list2) {
Map> fieldMap = hi.get(document.get("id"));
List text = fieldMap.get("text");
List fileName = fieldMap.get("filename");
List filePath = (List) document.get("filepath");
String size = (String) document.get("size");
String author = (String) document.get("author");
FileInfo file = new FileInfo(null == fileName || fileName.size() == 0 ? (String) document.get("filename") : fileName.get(0), filePath.get(0), author, null == text || text.size() == 0 ? (String) document.get("text") : text.get(0), size);
file.setSize(ByteUtils.formatByteSize(Long.valueOf(file.getSize())));
fileList.add(file);
}
model.setViewName("index");
model.addObject("fileList", fileList);
return model;
}
@RequestMapping("/addFileIndex")
@ResponseBody
public RespModule addFileIndex(MultipartHttpServletRequest request) {
RespModule respModule = new RespModule();
try {
FileMeta fileMeta = uploadupFile(request, "userfiles/file/");
ContentStreamUpdateRequest updateRequest = new ContentStreamUpdateRequest("/update/extract");
updateRequest.addFile(new File(fileMeta.getFileUrl()), fileMeta.getFileType());
updateRequest.setParam("literal.id", fileMeta.getFileName());
updateRequest.setParam("literal.filename", fileMeta.getFileName());
updateRequest.setParam("literal.filepath", fileMeta.getFileUrl());
updateRequest.setParam("literal.size", fileMeta.getFileSize());
updateRequest.setParam("text", "attr_content");
updateRequest.setAction(AbstractUpdateRequest.ACTION.COMMIT, true, true);
solrClient.request(updateRequest);
QueryResponse rsp = solrClient.query(new SolrQuery("*:*"));
SolrDocumentList solrDocumentList = rsp.getResults();
ListIterator listIterator = solrDocumentList
.listIterator();
while (listIterator.hasNext()) {
SolrDocument solrDocument = listIterator.next();
System.out.println(solrDocument.getFieldValue("filename"));
}
} catch (Exception e) {
respModule.setCode(ServiceErrorCode.ERROR.getErrorCode());
e.printStackTrace();
}
return respModule;
}
/**
* Localhost Upload
* @return
*/
public FileMeta uploadupFile(MultipartHttpServletRequest request, String pathStr) {
// SimpleDateFormat formatter = new SimpleDateFormat("yyyyMMddHHmmss");
FileMeta fileMeta = null;
Iterator itr = request.getFileNames();
MultipartFile mpf = null;
String savePath = request.getSession().getServletContext().getRealPath("/") + pathStr + DateUtils.formatDate(new Date(), "yyyyMMdd") + "/";
//String saveUrl = request.getContextPath() + "/" + pathStr + DateUtils.formatDate(new Date(), "yyyyMMdd") + "/";
if (itr.hasNext()) {
mpf = request.getFile(itr.next());
String originalFilename = mpf.getOriginalFilename();
fileMeta = new FileMeta();
fileMeta.setFileName(originalFilename);
fileMeta.setOldName(originalFilename);
fileMeta.setFileSize(String.valueOf(mpf.getSize()));
fileMeta.setFileType(mpf.getContentType());
try {
fileMeta.setBytes(mpf.getBytes());
fileMeta.setFileUrl(savePath + originalFilename);
FileUtils.createFile(savePath + originalFilename);
FileCopyUtils.copy(mpf.getBytes(), new FileOutputStream(savePath + originalFilename));
} catch (IOException e) {
e.printStackTrace();
System.out.println(e.getMessage());
}
}
return fileMeta;
}
上传的方法是这个addFileIndex
PostMan上传一下
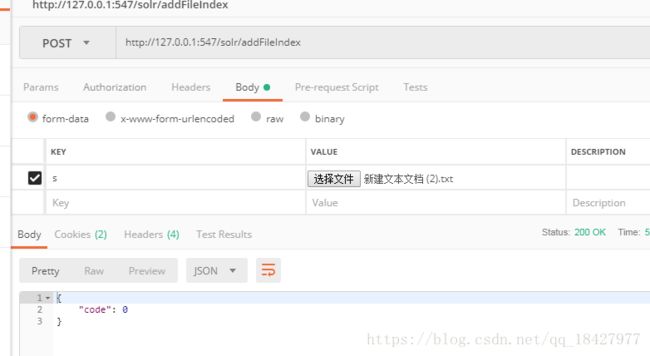
我们看一下 solr admin 后台

这里没有test没有txt里的内容 初步判断是文件在我本地 服务器没读到 本来是好的这个我后续更新一下
以上代码看看就知道意思了 所需要的工具类等我就不写了 主要是个实现的过程思路
下面是搜索的页面一个简单的Demo就是这样(Demo很烂 别喷 如果有需要的话我还是会把源码上传到gitee or github分享一下给你们的)

以上solr配置稍加变通在服务器可扫描盘admin Ui导入数据和导入mysql数据类似(自行百度)
五、suggest推荐
实现类似某宝搜索推荐类似的功能
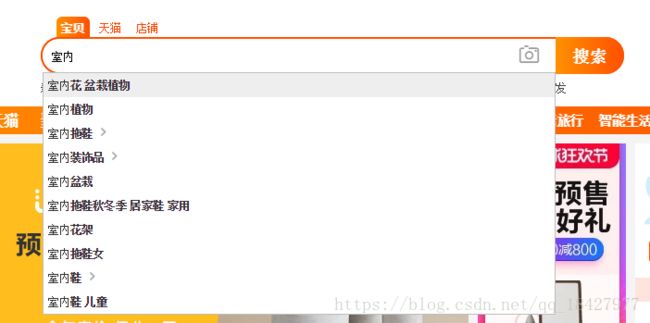
待更新,未完。