双目视觉几大步骤的串联和重要矩阵
整个双目视觉系统流程为:采集图像对、双目立体标定、图像校正、立体匹配和三维重建。
1. 双目标定
双目标定主要输入图像采集的两幅棋盘格图像,输出两个摄像机的内参矩阵K、相对的R、T;
内参4个包括:焦距fx, fy,单位是像素pixel。
cx, cy是图像的中心像素坐标与图像原点像素坐标之间相差的横向和纵向像素数,单位pixel。cx、cy一般不是正好是图像分辨率的一半,其是有偏差的,一般越好的摄像头则其越接近于分辨率的一半。
也有的把dx和dy看成内参,表示x方向和y方向的一个像素的mm数,是实现图像物理坐标系与像素坐标系转换的关键,fx=f/dx,f是mm单位,除以dx得到pixel单位。
k1,k2,k3径向畸变系数,p1,p2是切向畸变系数。
外参6个包括:R(ω、δ、 θ)3个,T(Tx、Ty、Tz)3个,R、T组合成成的3*4的矩阵。
总的转换关系如下:
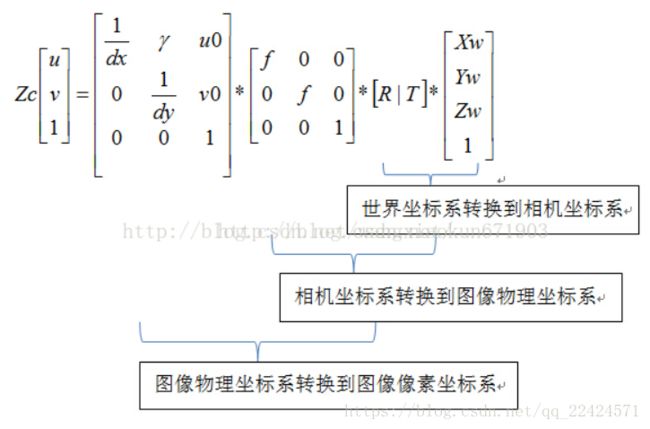
(1)世界坐标系通过外参矩阵转换到相机坐标系

(2) 相机坐标系通过内参矩阵转换到图像像素坐标系
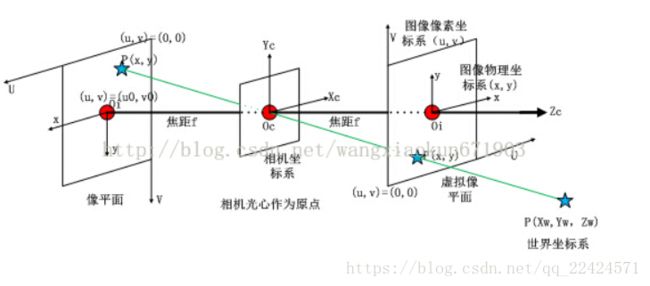
【1】在相机坐标系->图像物理坐标系的过程中发生畸变。

其中,k1,k2,k3径向畸变系数,p1,p2是切向畸变系数。
【2】相机坐标系通过焦距对角矩阵和畸变系数转换到图像物理坐标系;
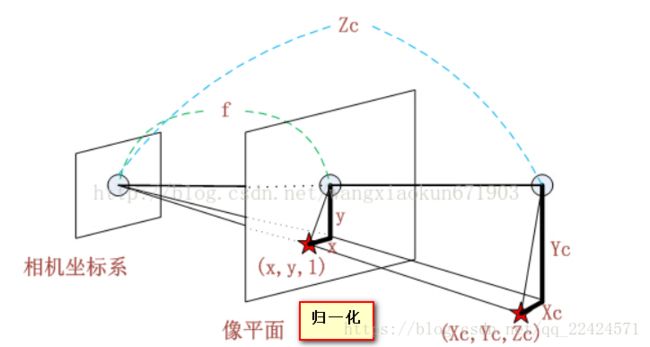

【3】图像物理坐标系通过像素转换矩阵转换到像素坐标系中。这一步是在同一个平面上做的,只不过先换了表示单位,又换了坐标原点的位置。

dx和dy表示:x方向和y方向的一个像素分别占多少个(可是小数)长度单位。u0,v0表示图像的中心像素坐标和图像原点像素坐标之间相差的横向和纵向像素数。
标定产生的几大关键矩阵:
【1】本质矩阵(Essentical Matrix):物理空间两个摄像机相关的旋转(R)和平移信息(T)。将左摄像机点P的物理坐标和右摄像机观测到的相同的点的位置关联起来。本质矩阵就是在归一化图像坐标下的基本矩阵。不仅具有基本矩阵的所有性质,而且还可以估计两相机的相对位置关系。
【2】基本矩阵(Fundamental Matrix):除了包含E的信息外,还包含了两个摄像机的内参数K,可以在像素坐标系将两个摄像机关联起来。
作用:给定一个图像上的一个点,被本质矩阵或基本矩阵相乘,其结果为此点在另一个图像上的对极线,在匹配时,可以大大缩小搜索范围;可用于求R 和 T。
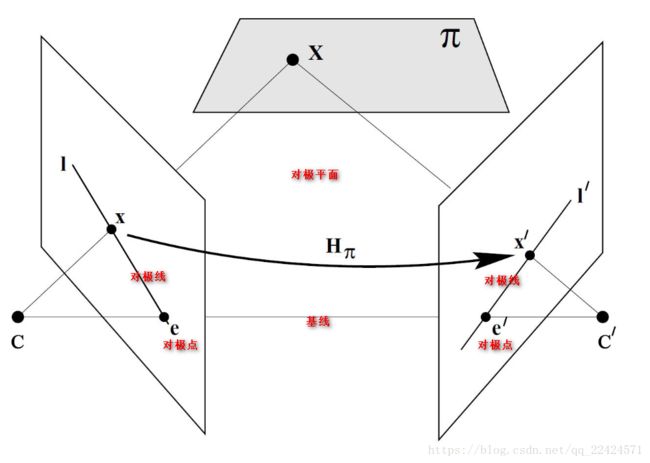
两者比较:
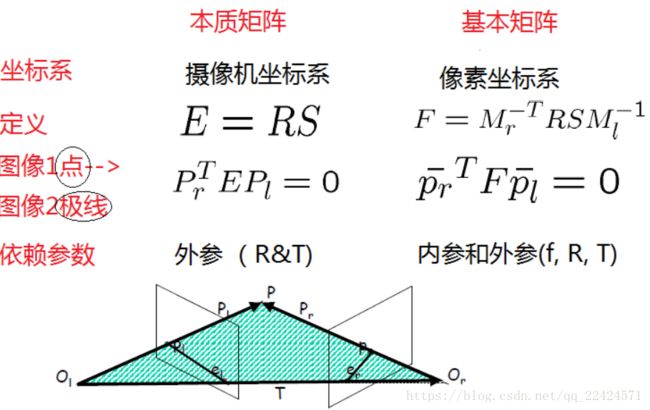
推导过程见:https://blog.csdn.net/x_r_su/article/details/54813929
2. 立体校正
立体校正是把拍摄的实景图片进行,消除畸变,最重要是行对准,为接下来的立体匹配提供源图片。
主要是利用标定生成的R、T实现。
3. 立体匹配
立体匹配目标是在两个或多个视点中匹配相应像素点,计算视差。通过建立一个能量代价函数,对其最小化来估计像素点的视差,求得深度。
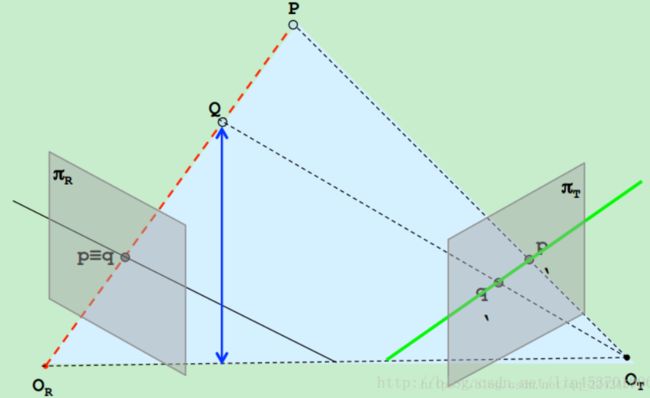
这里通过极线约束将匹配点搜索范围降到一维(校正过程)。
P和Q映射到左相机QR像面上的同一点p≡q,直线pq上的点对应点一定位于右像面的直线p’q’上,p’q’即为直线pq的极线,这就是极线约束。
4个步骤:匹配代价计算,代价聚合,计算视差,视差精化。
【1】匹配代价计算: 计算左右两图对应像素3个通道的灰度值差来决定匹配代价,常用的就是基于像素点匹配代价计算,一般有AD, SD,TAD;基于区域的匹配代价计算一般有SAD,SSD, STAD。匹配代价计算会生成一个disparity space image,也就是DSI。这个DSI是一个三维的空间,也就是每一个视差,得到一张代价图。假如视差范围是0~16,则会得到17幅代价图。视差搜索范围就是MiddleBurry网站上的stereo pair值,也就是说在视差范围内(比如0-16)内搜索匹配代价,得到17张匹配代价图,然后找到匹配代价最小的对应的视差值就是此像素对应的视差。
【2】代价聚合:一个滤波的过程,对每一幅代价图进行聚合,最简单的是采用boxfilter。第一步代价计算只是得到了图像上所有孤立像素的视差值,但是这些值都是孤立的,引入了过多噪声,比如一片区域的视差值都是10,可是引入噪声后就会导致这一片的视差值都不一样,那么就需要一个滤波的过程,也就是我们所说的局部立体匹配方法,即采用窗口卷积达到局部滤波的目的。
【3】计算视差:常用的是WTA算法(局部),对于图像中的同一个点,选出17幅代价图中匹配代价最小的那张图,该幅图对应的视差值就选取为最终的视差。或者在全局立体匹配中采用能量函数的方法,分为数据项和平滑项,数据项其实就是代价计算,平滑项就是代价聚合,只不过窗口大小是整幅图像,也可以试试如果把平滑项前面的系数lamda设为0,那么得到的结果和单纯代价计算的局部立体匹配是一样的。
【4】视差精化:也就是对得到的视差进行优化的过程,如:左右一致性检测、区域投票等;这步其实是很多立体匹配的遮羞布,比如用遮挡处理,中值滤波,左右一致性检测等,都能使最后的是视差图提升1%左右,它是很多论文的遮羞布。但是不可否认的是,立体匹配最关键的步骤仍然是代价计算和代价聚合步骤。
在立体匹配方法中,基于全局和局部的算法有些区别。不过基本步骤都差不多。有些时候,基于局部的算法,第一步和第二步是合并在一起进行的,基于全局的算法,会跳过第二步。