Java编程思想 注解总结
注解(也被称为元数据)为我们在代码中添加信息提供了一种形式化的方法 使我们可以在稍后某个时刻非常方便地使用这些数据
基本语法
在下面的例子中 使用@Test对testExecute()方法进行注解 该注解本身并不做任何事情 但是编译器要确保在其构造路径上必须有@Test注解的定义 程序员可以创建一个通过反射机制来运行testExecute()方法的工具

定义注解
下面就是前例中用到的注解@Test的定义 可以看到 注解的定义看起来很像接口的定义 事实上 与其他任何Java接口一样 注解也将会编译成class文件

除了@符号以外 @Test的定义很像一个空的接口 定义注解时 会需要一些元注解(meta annotation) 如@Target和Retention @Target用来定义你的注解将应用于什么地方(例如是一个方法或者一个域) @Rectetion用来定义该注解在哪一个级别可用 在源代码中(SOURCE) 类文件中(CLASS)或者运行时(RUNTIME)
在注解中 一般都会包含一些元素以表示某些值 当分析处理注解时 程序或工具可以利用这些值 注解的元素看起来就像接口的方法 唯一的区别是你可以为其指定默认值
没有元素的注解称为标记注解(meta annotation) 例如上例中的@Test
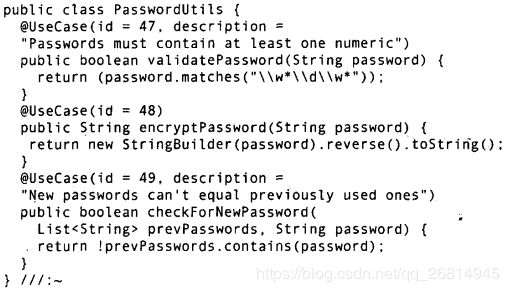
下面是一个简单的注解 我们可以用它来跟踪一个项目中的用例 如果一个方法或一组方法实现了某个用例的需求 那么程序员可以为此方法加上该注解 于是 项目经理通过计算已经实现的用例 就可以很好地掌控项目的进展 而如果要更新或修改系统的业务逻辑 则维护该项目的开发人员也可以很容易地在代码中找到对应的用例

在下面的类中 有三个方法被注解为用例
元注解
Java目前只内置了三种标准注解 以及四种元注解 元注解专职负责注解其他的注解

编写注解处理器
如果没有用来读取注解的工具 那注解也不会比注释更有用 使用注解的过程中 很重要的一个部分就是创建与使用注解处理器 Java SE5扩展了反射机制的API 以帮助程序员构造这类工具 同时 它还提供了一个外部工具apt帮助程序员解析带有注解的Java源代码
下面是一个非常简单的注解处理器 我们将用它来读取PasswordUtils类 并使用反射机制查找@UseCase标记 我们为其提供了一组id值 然后它会列出在PasswordUtils中找到的用例 以及缺失的用例

注解元素
标签@UseCase由UseCase.java定义 其中包含int元素id 以及一个String元素description 注解元素可用的类型如下所示
- 所有基本类型(int float boolean等)
- String
- Class
- enum
- Annotation
- 以上类型的数组
如果你使用了其他类型 那编译器就会报错 注意 也不允许使用任何包装类型 不过由于自动打包的存在 这算不是什么限制 注解也可以作为元素的类型 也就是说注解可以嵌套 这是一个很有用的技巧
默认值限制
编译器对元素的默认值有些过分挑剔 首先 元素不能有不确定的值 也就是说 元素必须要么具有默认值 要么在使用注解时提供元素的值
其次 对于非基本类型的元素 无论是在源代码中声明时 或是在注解接口中定义默认值时 都不能以null作为其值 这个约束使得处理器很难表现一个元素的存在或缺失的状态 因为在每个注解的声明中 所有的元素都存在 并且都具有相应的值 为了绕开这个约束 我们只能自己定义一些特殊的值 例如空字符串或负数 以此表示某个元素不存在

生成外部文件
假设你希望提供一些基本的对象/关系映射功能 能够自动生成数据库表 用以存储JavaBean对象 你可以选择使用XML描述文件 指明类的名字 每个成员以及数据库映射的相关信息 然而 如果使用注解的话 你可以将所有信息都保存在JavaBean源文件中 为此 我们需要一些新的注解 用以定义与Bean关联的数据库表的名字 以及与Bean属性关联的列的名字和SQL类型
以下是一个注解的定义 它告诉注解处理器 你需要为我生成一个数据库表

注意 @DBTable有一个name()元素 该注解通过这个元素为处理器创建数据库表提供表的名字 接下来是为修饰JavaBean域准备的注解

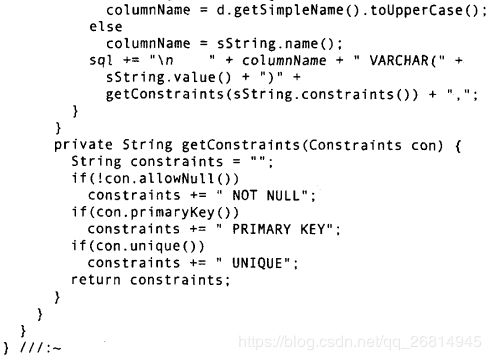
注解处理器通过@Constraints注解提取出数据库表的元数据 虽然对于数据库所能提供的所有约束而言 @Constraints注解只表示了它的一个很小的子集 不过它所要表达的思想已经很清楚了 primaryKey() allowNull()和unique()元素明智地提供了默认值 从而在大多数情况下 使用该注解的程序员无需输入太多东西
另外两个@interface定义的是SQL类型 如果希望这个framework更有价值的话 我们就应该为每种SQL类型都定义相应的注解 不过作为示例 两个类型足够了
这些SQL类型具有name()元素和constraints()元素 后者利用了嵌套注解的功能 将column类型的数据库约束信息嵌入其中 注意constraints()元素的默认值是@Constraints 由于在@Constraints注解类型之后 没有在括号中指明@Constraints中的元素的值 因此 constraints()元素的默认值实际上就是一个所有元素都为默认值的@Constraints 注解 如果要令嵌入的@Constraints注解中的unique()元素为true 并以此作为constraints()元素的默认值 则需要如下定义该元素

下面是一个简单的Bean定义 我们在其中应用了以上这些注解

默认值的语法虽然很灵巧 但它很快就变得复杂起来 以handle域的注解为例 这是一个@SQLString注解 同时该域将成为表的主键 因此在嵌入的@Constraints注解中 必须对primaryKey元素进行设定 这时事情就变得麻烦了 现在 你不得不使用很长的名 值对形式 重新写出元素名和@interface的名字 与此同时 由于有特殊命名的value元素已经不再是唯一需要赋值的元素了 所以你也不能再使用快捷方式为其赋值了 如你所见 最终的结果算不上清晰易懂
变通之道
可以使用多种不同的方式来定义自己的注解 以实现上例中的功能 例如 你可以使用一个单一的注解类@TableColumn 它带有一个enum元素 该枚举类定义了STRING INTEGER以及FLOAT等枚举实例 这就消除了每个SQL类型都需要一个@interface定义的负担 不过也使得以额外的信息修饰SQL类型的需求变得不可能 而这些额外的信息 例如长度或精度等 可能是非常有必要的需求
我们也可以使用String元素来描述实际的SQL类型 比如VARCHAR(30)或INTEGER 这使得程序员可以修饰SQL类型 但是 它同时也将Java类型到SQL类型的映射绑在了一起 这可不是一个好的设计 我们可不希望更换数据库导致代码必须修改并重新编译 如果我们只需告诉注解处理器 我们正在使用的是什么 口味 的SQL 然后由处理器为我们处理SQL类型的细节 那将是一个优雅的设计
第三种可行的方案是同时使用两个注解类型来注解一个域 @Constraints和相应的SQL类型(例如@SQLIntege) 这种方式可能会使代码有点乱 不过编译器允许程序员对一个目标同时使用多个注解 注意 使用多个注解的时候 同一个注解不能重复使用
注解不支持继承
不能使用关键字extends来继承某个@interface 这真是一个遗憾 如果可以定义一个@TableColumn注解(参考前面的建议) 同时在其中嵌套一个@SQLType类型的注解 那么这将成为一个优雅的设计 按照这种方式 程序员可以继承@SQLType 从而创建出各种SQL类型 例如@SQLInteger和@SQLString等 如果注解允许继承的话 这将大大减少打字的工作量 并且使语法更整洁 在Java未来的版本中 似乎没有任何关于让注解支持继承的提案 所以 在当前状况下 上例中的解决方案可能已经是最佳方法了
实现处理器
下面是一个注解处理器的例子 它将读取一个类文件 检查其上的数据库注解 并生成用来创建数据库的SQL命令



使用apt处理注解
与javac一样 apt被设计为操作Java源文件 而不是编译后的类 默认情况下 apt会在处理完源文件后编译它们 如果在系统构建的过程中会自动创建一些新的源文件 那么这个特性非常有用 事实上 apt会检查新生成的源文件中注解 然后将所有文件一同编译
当注解处理器生成一个新的源文件时 该文件会在新一轮(round Sun文档中这样称呼它)的注解处理中接受检查 该工具会一轮一轮地处理 直到不再有新的源文件产生为止 然后再编译所有的源文件
程序员自定义的每一个注解都需要自己的处理器 而apt工具能够很容易地将多个注解处理器组合在一起 有了它 程序员就可以指定多个要处理的类 这比程序员自己遍历所有的类文件简单多了 此外还可以添加监听器 并在一轮注解处理过程结束的时候收到通知信息
下面是一个自定义的注解 使用它可以把一个类中的public方法提取出来 构造一个新的接口

RetentionPolicy是SOURCE 因为当我们从一个使用了该注解的类中抽取出接口之后 没有必要再保留这些注解信息 下面的类有一个公共方法 我们将会把它抽取到一个有用接口中

在Multiplier类中(它只对正整数起作用) 有一个multiply()方法 该方法多次调用一个私有的add()方法以实现乘法操作 add()方法不是公共的 因此不将其作为接口的一部分 注解给出了值IMultiplier 这就是将要生成的接口的名字


apt工具需要一个工厂类来为其指明正确的处理器 然后它才能调用处理器上的process()方法

以上例子中的处理器与工厂类都在annotations包中 在InterfaceExtractorProcessor.java开头的注释文字中 根据anotations的目录结构 在Exec标记处给出了需要从命令行输入的命令 它将告诉apt工具 使用上面的工厂类来处理Multiplier.java文件 参数-s说明任何新产生的文件都必须放在annotations目录中 通过处理器中的println()语句 估计你已经能猜到最终生成的IMultiplier.java会是什么样子了

apt也会编译这个新产生的文件 因此你将在相同的目录中看到IMultiplier.class文件
将观察者模式用于apt
上面的例子是一个相当简单的注解处理器 只需对一个注解进行分析 但我们仍然要做大量复杂的工作 因此 处理注解的真实过程可能会非常复杂 当我们有更多的注解和更多的处理器时 为了防止这种复杂性迅速攀升 mirror API提供了对访问者设计模式的支持
一个访问者会遍历某个数据结构或一个对象的集合 对其中的每一个对象执行一个操作 该数据结构无需有序 而你对每个对象执行的操作 都是特定于此对象的类型 这就将操作与对象解耦 也就是说 你可以添加新的操作 而无需向类的定义中添加方法
这个技巧在处理注解时非常有用 因为一个Java类可以看作是一系列对象的集合 例如TypeDeclaration对象 FieldDeclaration对象以及MethodDeclaration对象等 当你配合访问者模式使用apt工具时 需要提供一个Visitor类 它具有一个能够处理你要访问的各种声明的方法 然后 你就可以为方法 类以及域上的注解实现相应的处理行为
下面仍然是SQL表生成器的例子 不过这次我们使用访问者模式来创建工厂和注解处理器


看起来这个例子使用的方式似乎更复杂 但是它确实是一种具备扩展能力的解决方案 当你的注解处理器的复杂性越来越高的时候 如果还按前面例子中的方式编写自己独立的处理器 那么很快你的处理器就将变得非常复杂
基于注解的单元测试
单元测试是对类中的每个方法提供一个或多个测试的一种实践 其目的是为了有规律地测试一个类的各个部分是否具备正确的行为 在Java中 最著名的单元测试工具就是JUnit 对于注解出现之前的JUnit而言 有一个主要的问题 即为了设置并运行JUnit测试需要做大量的形式上的工作 随着其渐渐的发展 这种负担已经减轻了一些 但注解的出现能够使其更贴近 最简单的单元测试系统
使用注解出现之前的JUnit 程序员必须创建一个独立的类来保存其单元测试 有了注解 我们可以直接在要验证的类里面编写测试 这将大大减少单元测试所需的时间和麻烦之外 采用这种方式还有一个额外的好处 就是能够像测试public方法一样很容易地测试private方法
这个基于注解的测试框架叫做@Unit 其最基本的测试形式 可能也是你用的最多的一个注解是@Test 我们用@Test来标记测试方法 测试方法不带参数 并返回boolean结果来说明测试成功或失败 程序员可以任意命名他的测试方法 同时 @Unit测试方法可以是任意你喜欢的访问修饰方式 包括private
要使用@Unit 程序员必须引入net.mindview.atunit 用@Unit的测试标记为合适的方法和域打上标记 然后让你的构建系统对编译后的类运行@Unit 下面是一个简单的例子
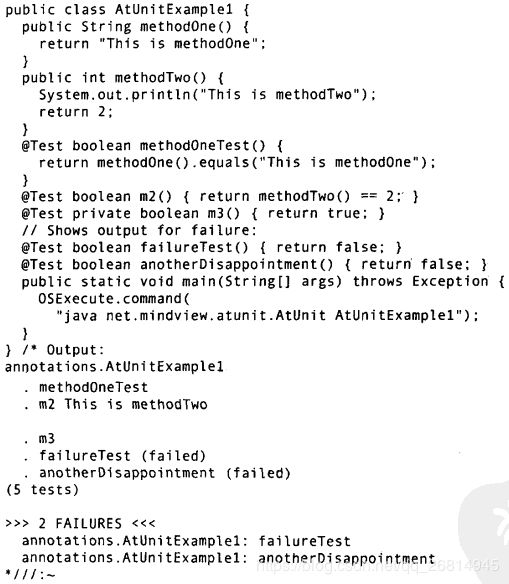
程序员并非必须将测试方法嵌入到原本的类中 因为有时候这根本做不到 要生成一个非嵌入式的测试 最简单的办法就是继承

或者你还可以使用组合的方式创建非嵌入式的测试

@Unit中并没有JUnit里的特殊的assert方法 不过@Test方法仍然允许程序员返回void(如果你还是想用true或false的话 你仍然可以用boolean作为方法返回值类型) 这是@Test方法的第二种形式 在这种情况下 要表示测试成功 可以使用Java的assert语句 Java的断言机制一般要求程序员在java命令行中加上-ea标志 不过@Unit已经自动打开了该功能 而要表示测试失败的话 你甚至可以使用异常 @Unit的设计目标之一就是尽可能少地添加额外的语法 而Java的assert和异常对于报告错误而言 已经足够了 一个失败的assert或从测试方法中抛出异常 都将被看作一个失败的测试 但是@Unit并不会就在这个失败的测试上打住 它会继续运行 直到所有的测试都运行完毕 下面是一个示例程序

下面的例子使用非嵌入式的测试 并且用到了断言 它将对java.util.HashSet执行一些简单的测试

对每一个单元测试而言 @Unit都会用默认的构造器 为该测试所属的类创建出一个新的实例 并在此新创建的对象上运行测试 然后丢弃该对象 以避免对其他测试产生副作用 如此创建对象导致我们依赖于类的默认构造器 如果你的类没有默认构造器 或者新对象需要复杂的构造过程 那么你可以创建一个static方法专门负责构造对象 然后用@TestObjectCreaet注解将该方法标记出来 就像这样


有的时候 我们需要向单元测试中添加一些额外的域 这时可以使用@TestProperty注解 由它注解的域表示只在单元测试中使用(因此 在我们将产品发布给客户之前 他们应该被删除掉) 在下面的例子中 一个String通过String.split()方法被拆散了 从其中读取一个值 这个值将被用来生成测试对象


如果你的测试对象需要执行某些初始化工作 并且使用完毕后还需要进行某些清理工作 那么可以选择使用static @TestObjectCleanup方法 当测试对象使用结束后 该方法会为你执行清理工作 在下面的例子中 @TestObjectCreate为每个测试对象打开了一个文件 因此必须在丢弃测试对象的时候关闭该文件


将@Unit用于泛型
泛型为@Unit出了一个难题 因为我们不可能 泛泛地测试 我们必须针对某个特定类型的参数或参数集才能进行测试 解决的办法很简单 让测试类继承自泛型类的一个特定版本即可
下面是一个堆栈的例子

要测试String版的堆栈 就让测试类继承自StackL


不需要任何 套件
与JUnit相比 @Unit有一个比较大的优点 就是@Unit不需要 套件(suites) 在JUnit中 程序员必须告诉测试工具你打算测试什么 这就要求用套件来组织测试 以便JUnit能够找到它们 并运行其中包含的测试
实现@Unit
首先 我们需要定义所有的注解类型 这些都是简单的标签 并且没有属性 @Test标签在本节开头已经定义过了 这里是其他所需的注解


所有测试的保留属性必须是RUNTIME 因为@Unit系统必须在编译后的代码中查询这些注解
要实现该系统 并运行测试 我们还需使用反射机制来抽取注解 下面这个程序通过注解中的信息 决定如何构造测试对象 并在测试对象上运行测试 正是由于注解的帮助 这个程序才如此短小而直接




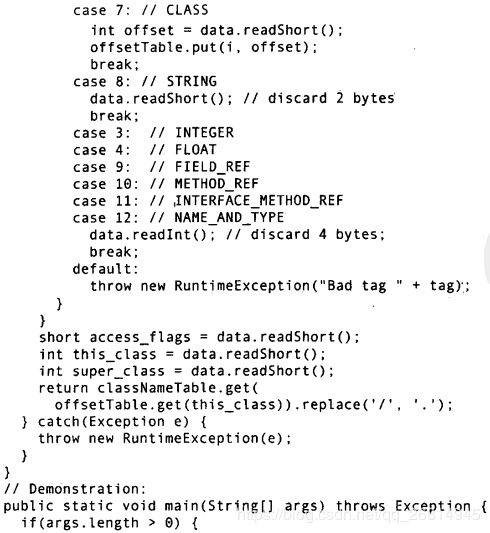
AtUnit.java必须要解决一个问题 就是当它找到类文件时 实际引用的类名(含有包)并非一定就是类文件的名字 为了从中解读信息 我们必须分析该类文件 这很重要 因为这种名字不一致的情况确实可能出现 所以 当找到一个.class文件时 第一件事情就是打开该文件 读取其二进制数据 然后将其交给ClassNameFinder.thisClass() 从这里开始 我们将进入 字节码工程 的领域 因为我们实际上是在分析一个类文件的内容


移除测试代码
对许多项目而言 在发布的代码中是否保留测试代码并没什么区别(特别是在如果你将所有的测试方法都声明为private的情况下 如果你喜欢就可以这么做) 但是在有的情况下 我们确实希望将测试代码清除掉 精简发布的程序 或者就是不希望测试代码暴露给客户
与自己动手删除测试代码相比 这需要更复杂的字节码工程 不过开源的Javassist工具类库将字节码工程带入了一个可行的领域 下面的程序接受一个-r标志作为其第一个参数 如果你提供了该标志 那么它就会删除所有的@Test注解 如果你没有提供该标记 那它则只会打印出@Test注解 这里同样使用ProcessFiles来遍历你选择的文件和目录

