Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求
一位高人曾经说过,想爬取数据,要先分析网站
今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了。
这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽的音乐,贪玩蓝月?
通过python,我们可以避免广告,直接拿到我们要的东西
我用的是火狐浏览器,按F12打开开发者工具,选择网络
按照正常的操作顺序,其实python就是在模拟人进行一些网页操作,我们只不过通过python解放自己的双手
在搜索框输入“傲骨贤妻”,当然你输入其他的电视剧名称也可以,查看开发者工具
聪明的你肯定一下就看出来了,对,就是第一个请求,点开
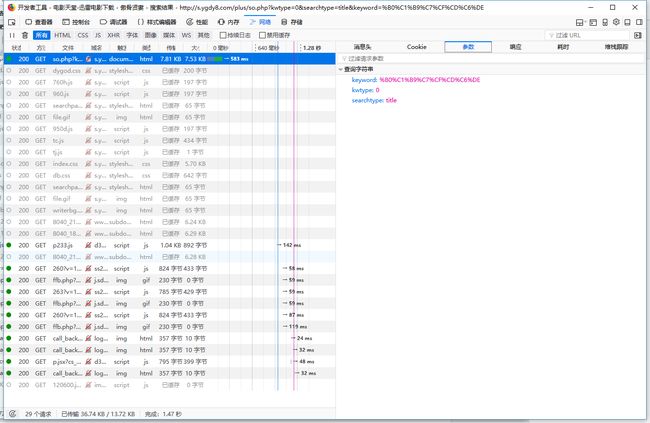
查看参数,keyword中文意思是关键字,我们可以得知,“傲骨贤妻”被encode成了这种看不懂的东西 ,参数kwtype和searchtype感觉没什么用,具体我也不知道干啥的,我们模拟请求的时候,把它俩加上,防止出问题
好了,我们现在可以打开开发工具开始玩耍了,我用的是IntelliJ IDEA,我安装了python插件,和pycharm不会差太多,挺好用的。因为我平时用Java开发比较多,我就懒得再下载其他开发工具。当然你用记事本
我也不反对。我先建立一个film.py,用来放置电视剧名。这是一个好习惯,有些时候安全性比较高的数据专门放在一个文件里,进行加密,或者github忽略不提交,可以避免不必要的麻烦
# coding=utf-8 filmName = '傲骨贤妻'
2.用python模拟搜索请求
建立_init_.py
导入所需要的包 urlib2,re,film,注释已经很清楚了,我来解释下%(film.filmName).decode("utf-8").encode('gb2312'),%是取出我存在film.py里面的值,为什么要用decode在encode呢?右键查看页面源代码,你会发现,电影天堂
并不是utf-8编码,而是gb2312,所以我们要encode呀,刚才我们看到keyword是看不懂的火星文,我们现在知道了,它其实是gb2312编码,所以这里我们把filmName先解码成utf-8,变成能看懂的“傲骨贤妻“,再编码成gb2312
电影天堂后台所能看懂的“傲骨贤妻”,ok,这样so.php就可以执行我们的查询操作,kwtype=0&searchtype=titile带上吧,反正也不累。
关于正则语法,是python基础,可以去慕课网学习,我就不解释了。我们目的是看到html里面超链接的特点,进行正则匹配
# coding=utf-8 import urllib2 import film import re opener = urllib2.build_opener()#构建一个handler对象 def search(): req = urllib2.Request('http://s.ygdy8.com/plus/so.php') #so.php请求参数将中文进行了Url.encode(),所以需要将中文encode('gb2312')处理 req.add_data('kwtype=0&searchtype=title&keyword=%s' %(film.filmName).decode("utf-8").encode('gb2312')) html = opener.open(req).read().decode('gb2312') reg = r'/html/tv/oumeitv/[0-9]{8}/[0-9a-zA-Z.]{9,10}' return re.findall(reg,html) search()
3.分析下载地址
我们接着对网站进行分析 ,我们刚才搜索完成
现在界面是这样,我们暂时只取第一个,也就是“2014主打美剧《傲骨贤妻》第六季”
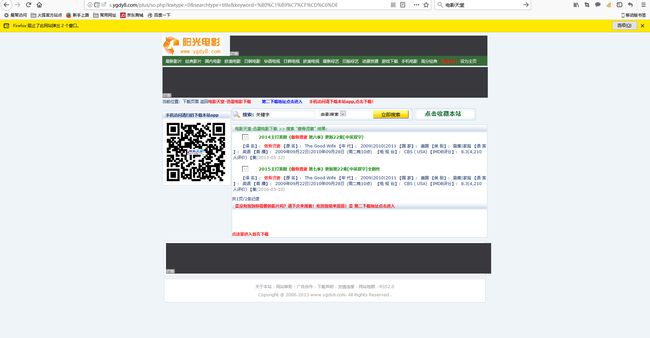
点开第一个连接,进入熟悉的界面,终于找到我们想要的了,对,就是下载地址
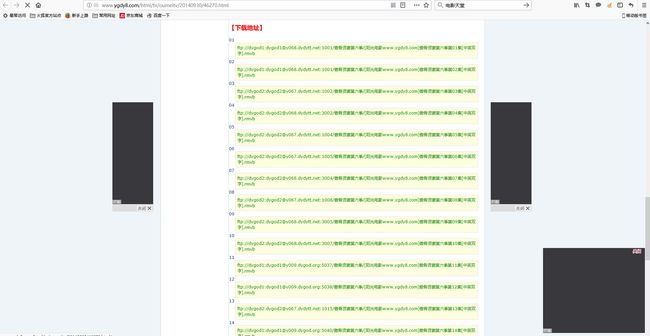
4.获取下载链接
广告出奇的多。。。还好我禁用了flash
这时候打开idea,写入代码。list获取到search结果,因为search是两个,为了看到效果,我没有遍历,只取第一个搜索结果,即2014主打剧...,这里正则用u是指Unicode string,因为我们这里存在中文
html解码,正则匹配电影天堂下载格式
def openSearchResult(): list = search() req = urllib2.Request('http://www.ygdy8.com'+list[0]) html = opener.open(req).read().decode('gb2312','ignore') reg = u'ftp://[a-z0-9]+:[a-z0-9]+@[a-z0-9]+.[a-z]{1,8}.[a-z]{3}:[\d]{4}/[\u4e00-\u9fa5]{0,10}[\W]*\[阳光电影www.ygdy8.com\][\u4e00-\u9fa5]*[\d]+[\u4e00-\u9fa5]\[[\u4e00-\u9fa5]+\].rmvb' return re.findall(reg,html) openSearchResult()
然后再用list把openSearchResult遍历出来,Unicode string必须遍历才能看到中文
def getList(): for i in openSearchResult(): print i getList()
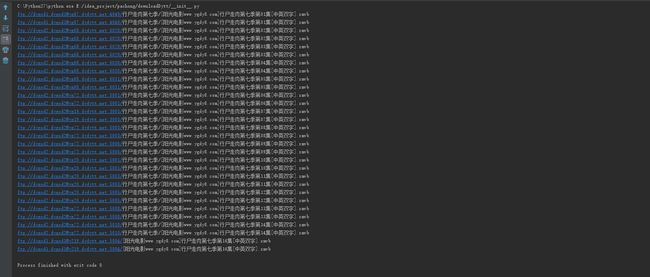
结果如下,复制下来到迅雷就可以下载啦
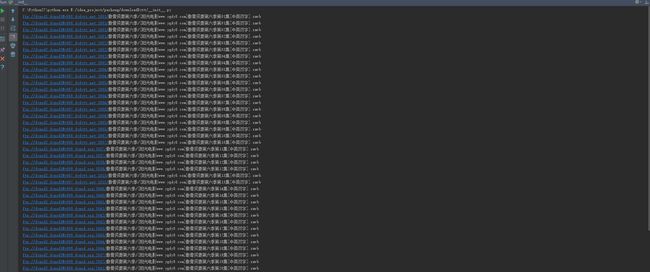
我把fileName换成行尸走肉
5.源码
这个是正则基本语法https://github.com/cjy513203427/pachong/tree/master/regularExpression
这个是该博客的源码:https://github.com/cjy513203427/pachong/tree/master/downloadDytt