一个Python爬取豆瓣书籍信息的例子
本来工作上用的是Java爬虫,但是感觉Java爬虫太麻烦,耦合度太高,自己想捣鼓一些爬虫demo不太方便。所以想到了Python爬虫,使用Python爬取了一下,发现真的很方便。
一、第三方类库安装
Python的强大之处就在于它拥有丰富的第三方类库,某些功能有人已经写好了的,我们直接使用能大大简化开发过程。
| 第三方库 | 作用 | 安装 |
|---|---|---|
| re | 用来进行正则匹配 | pip3 install re |
| requests | 用来发送HTTP请求 | pip3 install requests |
| requests-html | 用来发送HTTP请求 | pip3 install requests-html |
| BeautifulSoup | 用来从HTML或XML中提取数据 | pip3 install beautifulsoup4 |
| pandas | 生成数据表 | pip3 install pandas |
二、获取书名及其链接
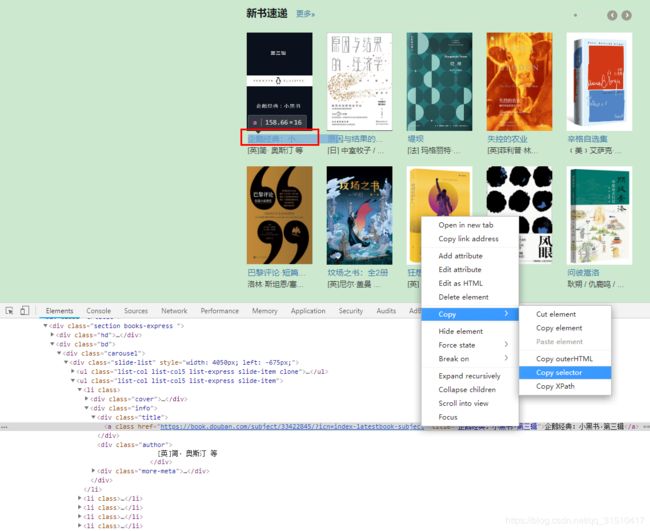
如上图所示,第一步需要获取红色方框里面的书名及其链接地址。先写一个获取页面链接名称和链接地址的方法
from requests_html import HTMLSession
headers = {'User-Agent': 'User-Agent:Mozilla/5.0'}
def get_text_link_from_sel(url, sels=None):
"""
根据选择器返回文字和其对应的链接
:param url: 要爬取的url
:param sels: 多组selector
:return:
"""
if sels is None:
sels = []
session = HTMLSession()
r = session.get(url, headers=headers)
my_list = []
try:
for sel in sels:
the_results = r.html.find(sel)
for result in the_results:
my_text = result.text
my_link = list(result.absolute_links)[0]
my_list.append((my_text, my_link))
return my_list
except:
return None
然后在浏览器上按F12进入开发人员工具,如上图所示拷贝第一本书的selector为
#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li:nth-child(1) > div.info > div.title > a
然后测试一下该方法。在上面代码的下面添加以下代码
url = 'https://book.douban.com'
sels = ['#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li:nth-child(1) > div.info > div.title > a']
print(get_text_link_from_sel(url, sels))
运行代码后输出结果为

注:每次运行的结果都可能会不一样,这是因为每次访问豆瓣首页新书速递都会发生变化。
同理,拷贝第二本书的selector加入到sels里,修改sels如下
sels = ['#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li:nth-child(1) > div.info > div.title > a', '#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li:nth-child(2) > div.info > div.title > a']
再次运行以上代码输出结果

那么,如果我想爬取很多书的话需要在sels里填写很多selector吗?当然不是。我们仔细观察一下第一本书的selector和第二本书的selector,发现它们的区别在li:nth-child(1)和li:nth-child(2),那么我把:nth-child(1)去掉如何,修改sels如下
sels = ['#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li > div.info > div.title > a']
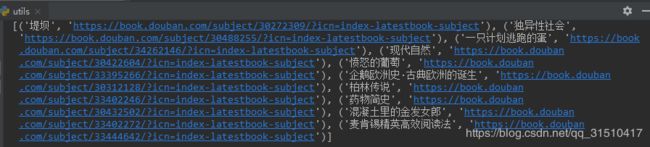
运行代码后发现输出结果就有这十本书名及其链接了
三、获取书籍信息
这里假设我要爬取作者、出版年、定价、序列号、评分、内容简介和作者简介。在之前的代码下方添加以下代码(当然,import的内容可以放到最上方):
import re
import requests
from bs4 import BeautifulSoup
def crawl_book_info(url):
results = []
temp_results = []
author = ''
public_time = ''
price = ''
serial = ''
score = ''
book_desc = ''
author_desc = ''
print("GET " + url)
response = requests.get(url, headers=headers)
content = response.content.decode("utf-8")
soup = BeautifulSoup(content, 'html.parser')
temp = soup.select("#info")
pattern1 = re.compile(r'出版年:([\s\d-]+)')
pattern2 = re.compile(r'定价:([\s\d.]+)')
pattern3 = re.compile(r'ISBN:([\s\d.]+)')
pattern4 = re.compile(r'作者:\s*([\u4E00-\u9FA5/•\[\]\s\w\W]+)出版社')
if temp:
author = re.findall(pattern4, temp[0].text)[0]
public_time = re.findall(pattern1, temp[0].text)[0]
price_temp = re.findall(pattern2, temp[0].text)
if price_temp:
price = price_temp[0]
serial = re.findall(pattern3, temp[0].text)[0]
temp = soup.select("#interest_sectl > div > div.rating_self.clearfix > strong")
if temp:
score = temp[0].text
temp = soup.select("div .intro")
if temp:
author_desc = temp[1].text
book_desc = temp[0].text
temp_results.append(author)
temp_results.append(public_time)
temp_results.append(price)
temp_results.append(serial)
temp_results.append(score)
temp_results.append(book_desc)
temp_results.append(author_desc)
for result in temp_results:
results.append(result.replace("\n", "").replace(" ", ""))
print(results)
return results
接着把上面那三行测试代码换为这行测试代码
crawl_book_info('https://book.douban.com/subject/30422604/?icn=index-latestbook-subject')
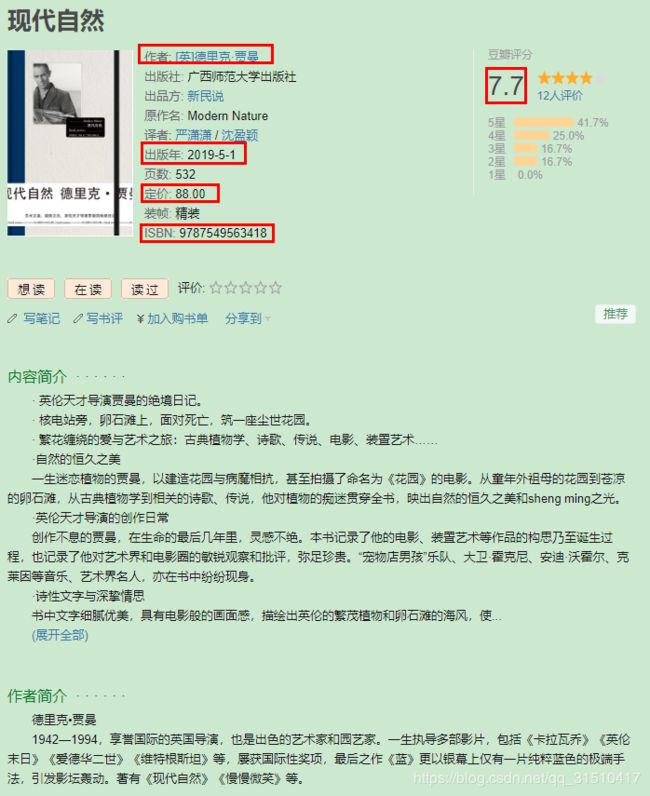
可以看到输出结果

注:有些书籍可能没有评分信息。若没有爬取到数据,有可能是豆瓣书籍信息页面样式发生改变,需要自行修改代码里select方法内容和正则表达式
四、爬取书籍信息并保存到文件
在上面两个方法都成功之后,接下来添加爬虫主方法,用来筛选出书籍名称及其信息页面链接后,进而爬取数据保存到文件。删掉那一行测试代码,在之前的代码下方添加以下方法:
import time
import pandas as pd
def crawl():
url = "https://book.douban.com"
my_sels = ['#content > div > div.article > div.section.books-express > div.bd > div > div > ul:nth-child(2) > li > div.info > div.title > a']
my_list = get_text_link_from_sel(url, my_sels)
results = []
for name_to_url in my_list:
info = crawl_book_info(name_to_url[1])
info.insert(1, name_to_url[0])
results.append(info)
time.sleep(1)
df = pd.DataFrame(results)
df.columns = ['book_name', 'author', 'public_time', 'price', 'serial', 'score', 'book_desc', 'author_desc']
# gbk用Excel打开时才不会乱码
df.to_csv('files/豆瓣图书.csv', encoding='utf-8', index=False)
if __name__ == '__main__':
crawl()
运行代码,待到控制台输出停止时,项目下会被自动创建一个files文件夹,豆瓣图书.csv文件便在该文件夹下,打开文件便能看到书籍信息

在文件夹窗口中,该文件默认会被Excel打开,但是utf-8编码的csv文件Excel打开是乱码的,用导入的方式指定编码方式便能正确打开。
至此,一个爬虫的小demo便完成了。