HTTP Content-Length深入实践
转载自(https://www.jianshu.com/p/d606732f2ebc)
引子
HTTP头部Content-Length用于描述HTTP消息实体的传输长度,浏览器对比Content-Length和HTTP请求或者响应body长度判断一次HTTP传输过程,以独立于TCP长连接。但是如果Content-Length与HTTP请求或者响应body长度不一致时,本文深入实践浏览器怎么处理这些异常情况。
Content-Length和Content-Type焦不离孟,关于Content-Type可以参考拙作HTTP Content-Type深入实践。
情况1:HTTP Response头部不显示指定Content-Length
后端Spring boot+Java代码:
package com.demo.web.http;
import com.google.common.collect.Maps;
import com.google.gson.Gson;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Map;
@Controller
@RequestMapping("http")
public class ContentTypeController {
private final static Gson GSON = new Gson();
@RequestMapping("/content-type-response")
public String contentType4Response() {
return "http/content-type-response";
}
@RequestMapping("content-type-response.json")
@ResponseBody
public void json4Response(HttpServletResponse response) throws IOException {
Map map = Maps.newHashMap();
map.put("name", "datou");
response.setContentType("application/json;charset=utf-8");
response.getWriter().write(GSON.toJson(map));
}
} 前端html+css+javascript+jquery代码:
HTTP response Content-Type Demo
Name:
访问图1红色方框的域名,对应图2绿色方框的抓包,点击“show name”按钮,前端发送ajax请求服务端,对应图2蓝色方框的抓包,即使服务端不显示指定HTTP Response头部Content-Length,实际的HTTP Response头部Content-Length: 16,如图1红色方框,对应图2红色方框的seq 712:848,其中136字节不只包含HTTP Response body。

图1 前端页面访问后端

图2 前端页面访问后端tcpdump
情况2:HTTP Response头部显示指定Content-Length等于实际Response body长度
后端Spring boot+Java代码,显示指定Content-Length:response.setContentLength(16);
package com.demo.web.http;
import com.google.common.collect.Maps;
import com.google.gson.Gson;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Map;
@Controller
@RequestMapping("http")
public class ContentTypeController {
private final static Gson GSON = new Gson();
@RequestMapping("/content-type-response")
public String contentType4Response() {
return "http/content-type-response";
}
@RequestMapping("content-type-response.json")
@ResponseBody
public void json4Response(HttpServletResponse response) throws IOException {
Map map = Maps.newHashMap();
map.put("name", "datou");
response.setContentType("application/json;charset=utf-8");
response.setContentLength(16);
response.getWriter().write(GSON.toJson(map));
}
} 访问前端页面与情况1一样,效果如图1和图2所示。
情况3:HTTP Response头部显示指定Content-Length小于实际Response body长度
后端Spring boot+Java代码,显示指定Content-Length:response.setContentLength(15);
访问图3域名,点击“show name”按钮,前端发送ajax请求服务端,服务端返回HTTP Response头部Content-Length: 15,对应图2红色方框的seq 712:847,相比图2的红色方框少一个字节。导致Response body不完整,前端也就不能解码Content-Type:application/json;charset=UTF-8的字符串为json对象,所以图3的Name:为空。

图3 前端页面访问后端
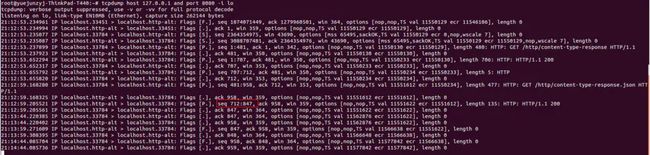
图4 前端页面访问后端tcpdump
情况4:HTTP Response头部显示指定Content-Length大于实际Response body长度
后端Spring boot+Java代码,显示指定Content-Length:response.setContentLength(17);
访问图5域名,点击“show name”按钮,前端发送ajax请求服务端,服务端返回HTTP Response头部Content-Length: 17,但是实际上HTTP Response body长度为16字节,对应图2红色方框的seq 712:848,与图2红色方框一致。
因为HTTP Response头部Content-Length: 17,所以浏览器一直等待第17个字节,不会解析实际上已经接收完服务端发送的HTTP Response body(16字节长度),等待一段时间后浏览器报net::ERR_CONTENT_LENGTH_MISMATCH,同时图5的Name:为空。

图5 前端页面访问后端

图6 前端页面访问后端tcpdump
HTTP首部Content-Length使用场景
当客户端向服务器请求一个静态页面或者一张图片时,服务器可以很清楚的知道内容大小,然后通过Content-length消息首部字段告诉客户端需要接收多少数据。
HTTP首部定义Connection: keep-alive后,客户端、服务端怎么知道本次传输结束呢?静态页面通过Content-Length提前告知对方数据传输大小。
以上就是 手写简单版Tomcat(一) 中关于为什么Content-Length会影响输出的解释,因为我觉得这篇文章写的非常通俗易懂,就把它拷过来了,下面是原文信息:
作者:大头8086
链接:https://www.jianshu.com/p/d606732f2ebc
來源:简书
不过虽然找到了解决的方法,但我还是很好奇

文件不存在的时候,也设置了Content-Length,为什么这个就能一字不落的返回出来呢?
然后我验证了一下,不管文件存不存在,我都输出内容的length长度

控制台输出length是38

抓包后看到响应长度也是38

没有任何毛病,Response头部显示指定Content-Length就是等于实际Response body长度 ,所以能够完全展示出来
下面来看下当我不设置Content-Length长度的时候,Content-Length实际是多少

嗯哼,长度是6,因为不设置长度,所以浏览器能正常显示

下面是抓包结果
 实际长度是14,但是输出的length长度确实6
实际长度是14,但是输出的length长度确实6

整整少了一半多,所以加上
"Content-Length: "+ line.length() +"\r\n" +后会显示不全 。
那这是为什么呢?
我个人目前认为,有几种可能性:
1.String.length()造成的差异,导致String.length()和实际的消息实体长度不一致;
2.String.length()没有错,也许一开始,实际的消息实体长度就是6,在HTTP传输过程中,扩大了至15。
OK,既然有了怀疑,那就一个个排除
先来看第一个
我打个断点看看length()到底是怎样的:


原来length是按多少个char来算的,
这样一想,好像确实没毛病,感觉就不能是String.length()的毛病了,
不过发现个意外的东西,

明明只有“范范范aa”,哪冒出来的'\uFEFF'介个,
老样子,度娘一波,
大概是这样的:
在Windows下用文本编辑器创建的文本文件,如果选择以UTF-8等Unicode格式保存,会在文件头(第一个字符)加入一个BOM标识。
这个标识在Java读取文件的时候,不会被去掉,而且String.trim()也无法删除。如果用readLine()读取第一行存进String里面,这个String的length会比看到的大1,而且第一个字符就是这个BOM。
这种情况会造成一些麻烦,比如在读取ini文件的时候,如果想判断第一行是不是以“[”开头就无法正确判断。
幸好,Java在读取Unicode文件的时候,会统一把BOM变成“\uFEFF”,这样的话,就可以自己手动解决了(判断后,用substring()或replace()去除掉这个BOM)。
原文在:https://blog.csdn.net/ClementAD/article/details/47168573
感兴趣的童鞋可以去看看,我这就不改了,只是个小插曲,不能耽误正事儿。
既然排除了第一个String.length(),那就来看看第二个,
实际的消息实体长度,在HTTP传输过程中,扩大了,
仔细一想,感觉怪怪的,
同样是HTTP传输,404报错为什么就没扩大呢?
除非这两个传输的东西有什么不同。
OK,推翻之前的理论,同样的数据,重新来过。
我把txt里的东西改成跟404报错是一样的

然后重新访问下,

因为没有设置Context-Length,所以能正常返回,
访问1.txt的抓包截图:

不访问文件的抓包截图:
 同样的内容,TXT里读出来的就是多了3长度,于是我尝试直接设置内容,而不从文件里读,看看结果是否一致
同样的内容,TXT里读出来的就是多了3长度,于是我尝试直接设置内容,而不从文件里读,看看结果是否一致

重新运行,抓包如下
 长度一致。。。。。
长度一致。。。。。
结果显而易见了。。。多出来的那个长度就是先前提到的,那个小插曲“\uFEFF”,这个东西占了3个长度
OK,胜利在望,于是我把"\uFEFF"给去掉后代码如下
import java.io.*;
/*
* Response的功能就是找到这个文件,使用Socket的outputStream把文件作为字节流输出给浏览器,就可以将我们的HTML显示给用户啦
*
*/
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String WEB_ROOT ="D:";
private Request request;
private OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//拼接本地目录和浏览器端口号后面的目录
File file = new File(WEB_ROOT, request.getUrL());
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(fis,"UTF-8"); //最后的"GBK"根据文件属性而定,如果不行,改成"UTF-8"试试
BufferedReader br = new BufferedReader(reader);
String line;
while ((line = br.readLine()) != null) {
if(line.startsWith("\uFEFF")){
line = line.replace("\uFEFF", "");
}
System.out.println(line + ":length:" + line.length());
String retMessage = "HTTP/1.1 200 OK\r\n" +
"Content-Type: text/html;charset=utf-8\r\n" +
"Content-Length: "+ line.length() +"\r\n" +
"\r\n" +
line;
output.write(retMessage.getBytes());
System.out.print(retMessage);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = ""+file.getName()+" file or directory not exists
";
System.out.println("length:" + retMessage.length());
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html;charset=utf-8\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
}把txt文字恢复,重新运行,访问,走你!

好的吧,乱码了
先看看抓包
 去除了"\uFEFF"后是11个长度
去除了"\uFEFF"后是11个长度
之前是14个长度

果然,就是"\uFEFF"搞得鬼,在String.length()中"\uFEFF"只占一个长度,但是在HTTP传输中却占了3个长度,所以传输长度小于实体长度,导致页面文字显示不全,
至于为什么乱码,很明显,String.length()是按多少个char来计算的,但是HTTP传输中,中文是比英文占的字节更大的,
范范范aa,String.length()是5个长度,HTTP中确实11个长度,也就是说,HTTP中,中文占3个,英文占2个,
在这里我设置了Context-Length等于String.length()也就是5个长度

客户端在读取的时候也只会读5个长度的内容,也就是 范**
因为2个长度不足以把中文读取出来,所以就是乱码了,
试验一下,我把txt里的文字改下

这个时候它应显示的是 范aa
 结果显示正确!!!!!!!
结果显示正确!!!!!!!
OK,终于搞懂了,丢失的长度是在哪,
虽然不是什么深的技术,但是作为一次教训,以此,写博客留念。
欢迎大家提出建议。