Python可视化初级(二)上——Python简单图形绘制
2.1 Python最基本图形
1. 饼图
饼图用于实现可视化离散型变量的分布的一种图形
plt.pie(x, explode,labels,colors,autopct=,pctdistance,shadow,startangle,radius, wedgeprops,textprops,center)- labels: 标签
- counterclock: 是否逆时针呈现
- colors:颜色
- wedgeprops: 设置饼图内外边界的属性
- autopct: 百分比
- textprops: 设置饼图中文本属性
- pctdistance: 百分比标签与圆心距离
- center: 设置中心位置
- shadow: 是否添加饼图阴影效果
- labeldistance: 设置各扇形标签与圆心距离
- startangle: 设置饼图的初始摆放角度
- radius: 设置饼图半径大小
kinds = ['简易箱','保温箱','行李箱','密封箱']
soldNums = [0.05,0.45,0.15,0.35]
explodes = [0,0,0,0]
plt.axes(aspect='equal') # 绘制出来的是正圆形
plt.pie(x=soldNums, labels=kinds, explode=explodes, autopct ='%.2f%%',
wedgeprops= { 'linewidth' : 1.0 , 'edgecolor' : 'green'},
startangle=0) #设置百分比格式
plt.title('不同类型箱子的销售数量占比')
plt.show()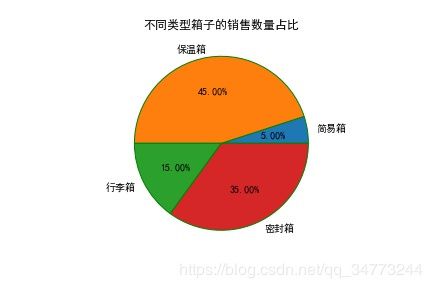
添加修饰的饼图
# 构造数据
edu = [0.2515,0.3724,0.3336,0.0368,0.0057]
labels = ['中专','大专','本科','硕士','其他']
explode = [0,0.1,0,0,0] # 生成数据,用于突出显示大专学历人群
colors=['#9999ff','#ff9999','#7777aa','#2442aa','#dd5555'] # 自定义颜色
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆
plt.axes(aspect='equal')
# 绘制饼图
plt.pie(x = edu, # 绘图数据
explode=explode, # 突出显示大专人群
labels=labels, # 添加教育水平标签
colors=colors, # 设置饼图的自定义填充色
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.5, # 设置百分比标签与圆心的距离
labeldistance = 1.0, # 设置教育水平标签与圆心的距离
startangle = 120, # 设置饼图的初始角度
radius = 1.2, # 设置饼图的半径
counterclock = False, # 是否逆时针,这里设置为顺时针方向
wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'},# 设置饼图内外边界的属性值
textprops = {'fontsize':10, 'color':'black'}, # 设置文本标签的属性值
)
# 添加图标题
plt.title('失信用户的受教育水平分布',pad =30)
# 显示图形
plt.show()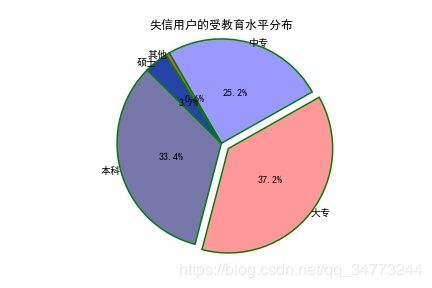
使用pandas的饼图
data1 = pd.Series({'中专':0.2515,'大专':0.3724,'本科':0.3336,'硕士':0.0368,'其他':0.0057})
# 将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data1.name = ''
# 控制饼图为正圆
plt.axes(aspect = 'equal')
# plot方法对序列进行绘图
data1.plot(kind = 'pie', # 选择图形类型
autopct='%.1f%%', # 饼图中添加数值标签
radius = 1, # 设置饼图的半径
startangle = 180, # 设置饼图的初始角度
counterclock = False, # 将饼图的顺序设置为顺时针方向
title = '失信用户的受教育水平分布', # 为饼图添加标题
wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值
textprops = {'fontsize':16, 'color':'black'} # 设置文本标签的属性值
)
# 显示图形
plt.title('失信用户的受教育水平分布',fontsize=16,pad =15)
# fontsize 控制文本字体大小,pad控制距离
plt.show()
2. 条形图
饼图不适合取值过多的分类特征,条形图不仅适合分类水平较多的变量也更加适合对比差异
bar(x, y,width,bottom,color,linewidth,tick_label,align)- x: 指定x轴上数值
- y: 指定y轴上数值
- width: 指定条形图宽度
- color: 条形图的填充色
- edge: 条形图的边框色
- bottom: 百分比标签与圆心距离
- linewidth: 条形图边框宽度
- tick_label: 条形图的刻度标签
- align: 指定x轴上对齐方式
绘制垂直条形图
# 创建简单数据
x =[1,2,3,4,5,6,7,8]
y =[3,1,4,5,8,9,7,2]
labels = ['q','a','c','e','r','j','b','p']
plt.bar(x,y,align='center',color='r',tick_label=labels)
plt.xlabel('箱子编号',labelpad =19) # 控制标签和坐标轴的距离
plt.ylabel('箱子重量(kg)',labelpad =10)
plt.title('不同箱子的重量图')
plt.show()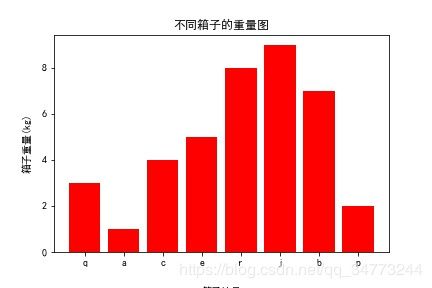
绘制水平条形图
# 创建简单数据
x =[1,2,3,4,5,6,7,8]
y =[3,1,4,5,8,9,7,2]
labels = ['q','a','c','e','r','j','b','p']
plt.barh(x,y,align='center',color='r',tick_label=labels)
plt.xlabel('箱子重量(kg)',fontsize=20,labelpad =19)
plt.ylabel('箱子编号',fontsize=20,labelpad =19)
plt.title('不同箱子的重量图',fontsize=20)
plt.show()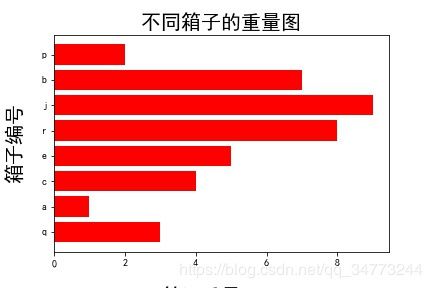
使用pandas绘图
x = ['q','a','c','e','r','j','b','p']
y =[3,1,4,5,8,9,7,2]
df = pd.DataFrame({'x':x,'y':y},index = range(1,9))
df.y.plot(kind = 'bar', width = 0.8, rot = 0, color = 'steelblue', title = '不同箱子的重量图')
# 添加y轴标签
plt.ylabel('箱子重量(kg)')
# 添加x轴刻度标签
plt.xticks(range(len(df.x)), #指定刻度标签的位置
df.x) # 指出具体的刻度标签值
# 为每个条形图添加数值标签
plt.text(1,1.2,'%s' % round(1,1),va='center')
for i,j in enumerate(df.y):
plt.text(i,j+0.2,'%s' % round(j,1) ,va='center')
# 显示图形
plt.show()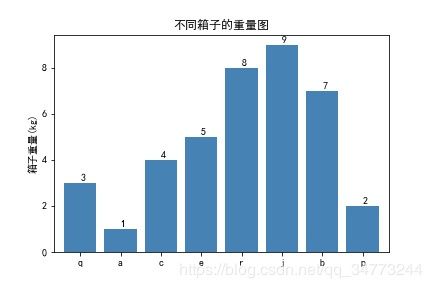
3. 直方图
对于连续型变量,往往需要查看其分布图,直方图就是用来观察数据的分布形态
plt.hist(x,bins,range,normed,cumulative,bottom,align,rwidth,color,edgecolor,label)- x: 数据
- bin: 条形个数
- range: 上下界
- density: 是否将频数转换成频率
- cumulative: 是否计算累计频率
- bottom: 为直方图的每个条形添加基准线,默认为0
- align: 对齐方式
- rwidth: 条形的宽度
- color: 填充色
- edgecolor: 设置直方图边框色
- label: 设置直方图标签
#读取数据
Titanic = pd.read_csv('titanic_train.csv')
#检查年龄是否有缺失
any(Titanic['Age'].isnull())
# 删除缺失值
Titanic['Age'].dropna(inplace=True)
#绘制直方图
plt.hist(x =Titanic.Age,bins=20,color='r',edgecolor='black', rwidth=2)
# plt.xlabel('年龄',fontsize =15,labelpad =20)
# plt.ylabel('频数',fontsize =15,labelpad =20)
plt.title('年龄分布图',fontsize =15)
plt.show()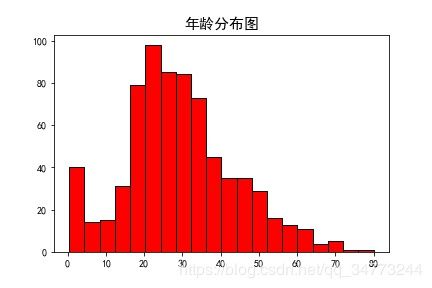
使用pandas绘图
Titanic.Age.plot(kind = 'hist', bins = 20, color = 'steelblue', edgecolor = 'black', label = '直方图',density = True)
# 绘制核密度图
Titanic.Age.plot(kind = 'density', color = 'red',label = '核密度图',xlim=[0,Titanic.Age.max()+5])
# 添加x轴和y轴标签
plt.xlabel('年龄')
plt.ylabel('核密度值')
# 添加标题
plt.title('乘客年龄分布')
# 显示图例
plt.legend()
# 显示图形
plt.show()
4. 散点图
散点图一般用来展示2个连续型变量的的关系,可以通过散点图来判断两个变量之间是否存在某种关系,例如线性还是非线性关系
plt.scatter(x,y,s,c,marker,cmap,norm,alpha,linewidths,edgecolorsl)- x: x数据
- y: y轴数据
- s: 散点大小
- c: 散点颜色
- marker: 散点图形状
- cmap: 指定某个colormap值,该参数一般不用,用默认值
- norm: 设置数据亮度
- alpha: 散点的透明度
- linewidths: 散点边界线的宽度
- edgecolors: 设置散点边界线的颜色
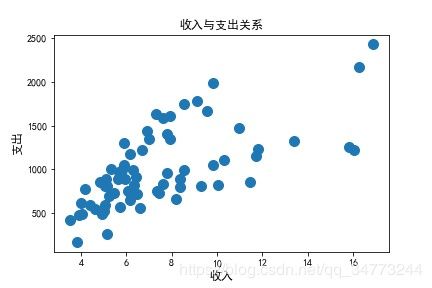
# 读取数据
creditcard_exp = pd.read_csv('creditcard_exp.csv',skipinitialspace = True)
creditcard_exp.dropna(subset=['Income','avg_exp'],inplace=True)
# 画图
plt.scatter(x = creditcard_exp.Income,y=creditcard_exp.avg_exp,color= 'steelblue',marker='o',
s=100,edgecolors='red')
plt.xlabel('收入',fontsize=12) # 坐标轴标签大小
plt.ylabel('支出',fontsize=12)
plt.title('收入与支出关系')
plt.show()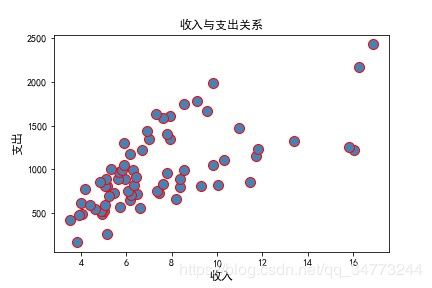
使用pandas绘图
creditcard_exp.plot(x= 'Income',y='avg_exp',kind='scatter',marker='o',s=100,title='收入与支出散点图')
plt.xlabel('收入',fontsize=12) #坐标轴标签大小
plt.ylabel('支出',fontsize=12)
plt.title('收入与支出关系')
plt.show()