Camunda(一)框架的性能和可伸缩性以及处理高吞吐量
本文重点探讨一下camunda框架,主要从camunda工作流框架的性能和可伸缩性,以及camunda框架如何处理高吞吐两个维度来说明。
持久化策略
Camunda框架可以运行在许多不同的关系数据库上(请参考:)。
Camunda使用这些数据库尽可能高效的执行sql,大概有如下几个概念:
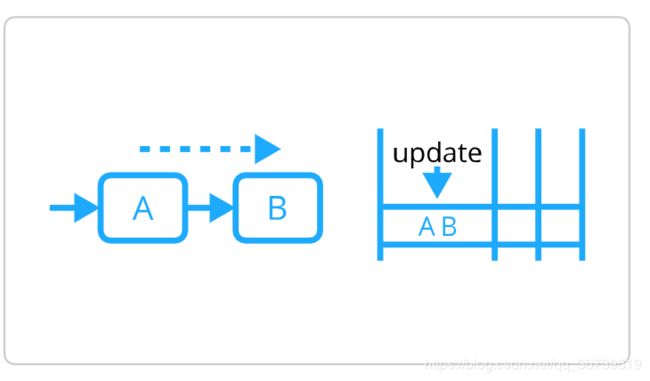

紧凑型表格
Camunda使用紧凑的数据模型和复杂的算法,从而使数据库中存储流程实例状态所需的行数达到最小化。 这通过减少需要存储的行数来加快执行速度。 在最好的情况下,当流程实例从一个活动前进到下一个活动时,只需要更新一行。而不是activiti、Flowable等框架使用的n行。
死锁避免
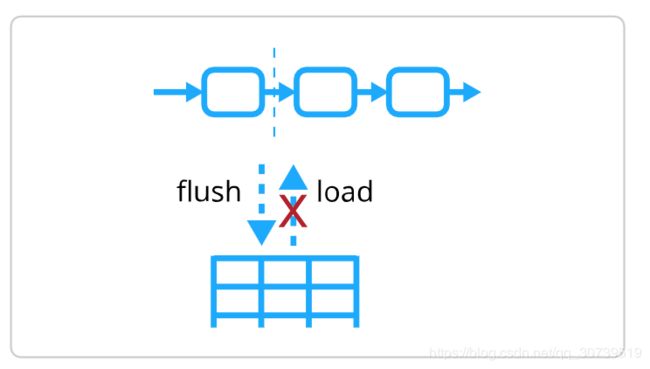
Camunda使用 乐观并发控制 来支持高级别的并发性,同时最大限度地降低死锁的风险。 在用户思考期间,锁永远不会被保留。 对数据库状态的所有修改都是在事务结束时批量刷新,同时使用智能SQL语句排序来避免循环等待。关于批量刷新也就是会话缓存,可以参考Activiti权威指南章节。
控制保存点
到实例到达保存点时,内存状态与数据库需要同步以确保容错。 Camunda提供了对保存点放置的精细控制,因此可以更好地平衡容错和性能。 例如,您可以在单个事务中批量执行多个活动,这样可以减少数据库同步点的数量。camunda框架提供了一些阈值设置参数可以让用户决定当一个会话缓存的容量达到一定的体量之后,自动刷新到数据库表并释放内存。
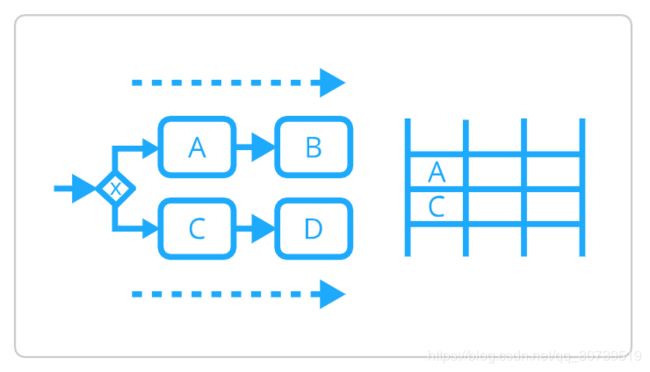
智能缓存
通过在后续事务中重用第一级缓存来支持只写保存点。 这大大减少了使用中间保存点执行活动序列所需的SELECT语句数。 这在实现JSON或XML有效负载转换等数据繁重的流程时最有效。
并发
并发令牌表示为数据库中的各个行。 此模型允许真正的进程内实例并发,因为可以同时更新单独的行。
集群
我们可以在集群中运行Camunda,以实现负载平衡和/或高可用性。
多个节点,共享数据库
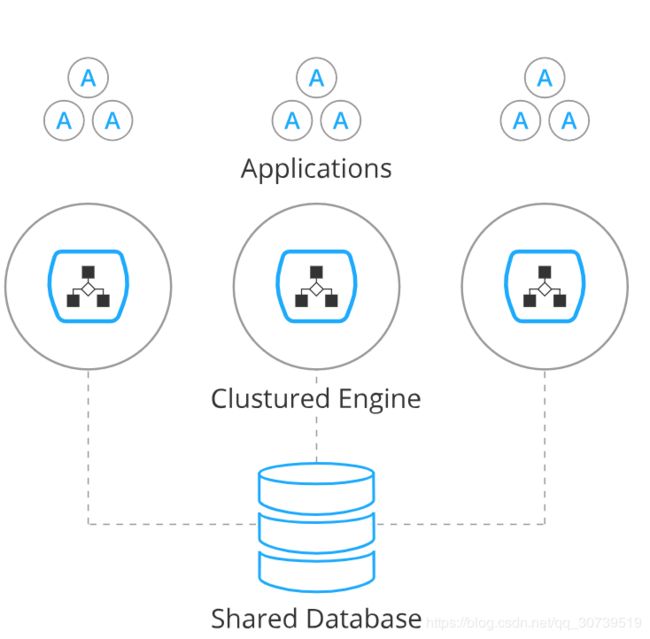
为了提供负载平衡或故障转移功能,可以将流程引擎分发到集群中的不同节点。 然后,每个流程引擎实例将连接到共享数据库。
各个流程引擎实例不会跨事务维护会话状态。 只要流程引擎运行事务,就会将完整状态刷新到共享数据库。 这使得可以将在同一流程实例中工作的后续请求路由到不同的群集节点。 此模型非常简单易懂,在部署群集安装时可能会受到限制。 就流程引擎而言,负载平衡设置和故障转移设置之间也没有区别(因为流程引擎在事务之间不保持会话状态)。
流程引擎作业执行程序也是群集的,并在每个节点上运行。 对流程引擎而言没有单点故障的问题。 作业执行者可以在两者中运行。
资源分配最少原则
由于流程引擎是无状态的,因此每个节点分配最少量的RAM内存(通常小于10 MB)。 基本上,您可以在数据库中保留数十亿个流程实例,而不会对每个节点的资源分配产生必要的影响。 这也意味着您可以为每个节点运行许多流程引擎实例。
运行时与历史设计
运行时数据是Camunda流程引擎为了进行异步而需要持久保存的最小数据量 。
-例如 当流程引擎等待用户交互(用户任务),传入消息(消息事件)或时间跨度(计时器事件)时,存在异步服务交互(服务任务)时等场景。
历史数据不是执行所必需的,但可以为了审计,报告等而记录。 它们允许您检查运行和已完成流程实例的完整审计跟踪,包括其有效负载。
Camunda将运行时数据与历史数据分离,这是一种非常强大的性能优化架构概念。
架构图如下:
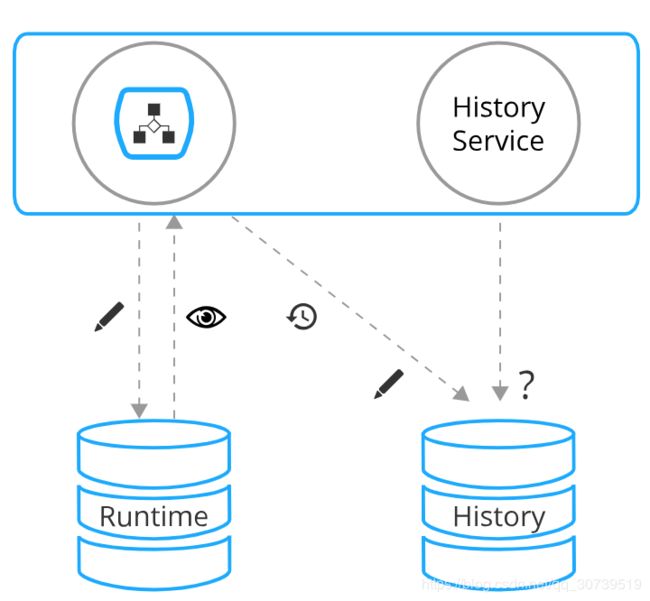
历史事件流
除了维护运行时状态之外,流程引擎还会创建一个审计日志,提供有关已执行流程实例的审计信息。 我们将此事件流称为历史事件流。 组成此事件流的各个子事件称为历史事件,包含有关已执行流程实例,活动实例,已更改流程变量等的数据。 在默认配置中,流程引擎将简单地将此事件流写入Camunda历史数据库。camunda提供了 HistoryService API查询此数据。
可配置的日志级别
流程引擎通过历史级别控制,进而对历史事件流提供数据量进行精细控制。 许多设置都是开箱即用的,比如"full" 或者"none".当然这个级别我们也可以自定义。
大数据
用户可以将历史事件流重新路由到自己喜欢的任何目标,包括队列以及您想要使用的大数据解决方案。 这是可能的,因为Camunda Process Engine组件不会从历史数据库中读取任何状态。常用的目标有es等。