创建爬虫项目,名称:example。在命令行输入以下命令:
scrapy startproject example
创建一个爬虫,名称:books。在命令行输入以下命令:
scrapy crawl genspider book_spider books "books.toscrape.com/"
创建好的爬虫,目录结构如下:
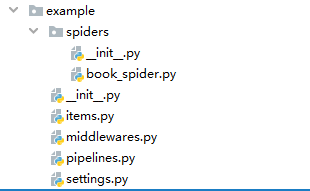
编写爬虫文件 book_spider.py
# _*_ coding:utf-8 _*_
import scrapy
#注意是scrapy.Spider不是scrapy.spider
#用 scrapy crawl -o books.csv 命令运行该爬虫
class BookSpider(scrapy.Spider):
# 每个爬虫的唯一标志
name = "books"
# 定义爬虫爬取的起始点,起始点可以是多个,这里只有一个
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
# 提取数据
# 每一本书的信息在 中
# css()方法找到所有这样的article元素,并以此迭代
for book in response.css('article.product_pod'):
# 书名信息在 article>h3>a元素的title属性里
# 例如: A Light
name = book.xpath('./h3/a/@title').extract_first()
# 书价信息在 的TEXT中
# 例如:
51.77
price = book.css('p.price_color::text').extract_first()
yield {
'name': name,
'price': price
}
# 提取链接
# 下一页的url在ul.pager>li.next>a里面
# 例如:next
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
# 如果找到下一页的url,得到绝对路径,构造新的Request对象
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(next_url)
编写pipelines.py文件
# -*- coding: utf-8 -*-
from scrapy.exceptions import DropItem
from scrapy.item import Item
import pymongo
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#class ExamplePipeline(object):
# def process_item(self, item, spider):
# return item
#处理数据
class PriceConverterPipeline(object):
#英镑兑换人民币汇率
exchange_rate=8.5309
def process_item(self,item,spider):
#提取item的price字段
#去掉前面的英镑符号,转换为float类型,乘以汇率
price =float(item['price'][1:])*self.exchange_rate
#保留两位小数,赋值回item的price字段
item['price']='Y%.2f'%price
return item
#去重复数据
class DuplicatesPipeline(object):
def __init__(self):
self.book_set=set()
def process_item(self,item,spider):
name =item['name']
if name in self.book_set:
raise DropItem("Duplicate book found :%s"%item)
self.book_set.add(name)
return item
#将数据存入MongoDB
class MongoDBPipeline(object):
#改变这种硬编码方式
#DB_URI='mongodb://localhost:27017'
#DB_URI='localhost'
#DB_NAME='scrapy_data'
#替换硬编码方式
@classmethod
def from_crawler(cls,crawler):
cls.DB_URI=crawler.settings.get('MONGO_DB_URI')
cls.DB_NAME=crawler.settings.get('MONGO_DB_NAME')
return cls()
def open_spider(self,spider):
#连接MongoDB
self.client = pymongo.MongoClient(self.DB_URI)
self.db=self.client[self.DB_NAME] #此处用中括号
def close_spider(self,spider):
#关闭MongoDB
self.client.close()
def process_item(self,item,spider):
collection = self.db[spider.name] #设置MongoBD的Collection名
post=dict(item) if isinstance(item,Item) else item #以dictde形式存入MongoDB
collection.insert_one(post) #将dict数据插入MongoDB
return item
编写settings.py配置文件
# -*- coding: utf-8 -*-
# Scrapy settings for example project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'example'
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'example (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'example.middlewares.ExampleSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'example.middlewares.ExampleDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'example.pipelines.PriceConverterPipeline': 300,
'example.pipelines.DuplicatesPipeline': 350,
'example.pipelines.MongoDBPipeline':400,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#将MongoDB数据库的连接信息存到配置文件中
MONGO_DB_URI='mongodb://localhost:27017/'
MONGO_DB_NAME='lhf_jlu_scrapy_data'
运行爬虫
#books是爬虫名字,-o books.csv是以csv文件的方式存储到本地
scrapy crawl books -o books.csv
运行结果
books.csv
name,price,_id
A Light in the Attic,Y441.64,5d5a4dfbc21f74f56708e8ef
Tipping the Velvet,Y458.45,5d5a4dfbc21f74f56708e8f0
Soumission,Y427.40,5d5a4dfbc21f74f56708e8f1
Sharp Objects,Y407.95,5d5a4dfbc21f74f56708e8f2
Sapiens: A Brief History of Humankind,Y462.63,5d5a4dfbc21f74f56708e8f3
The Requiem Red,Y193.22,5d5a4dfbc21f74f56708e8f4
The Dirty Little Secrets of Getting Your Dream Job,Y284.42,5d5a4dfbc21f74f56708e8f5
"The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull",Y152.96,5d5a4dfbc21f74f56708e8f6
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics,Y192.80,5d5a4dfbc21f74f56708e8f7
The Black Maria,Y444.89,5d5a4dfbc21f74f56708e8f8
"Starving Hearts (Triangular Trade Trilogy, #1)",Y119.35,5d5a4dfbc21f74f56708e8f9
Shakespeare's Sonnets,Y176.25,5d5a4dfbc21f74f56708e8fa
Set Me Free,Y148.95,5d5a4dfbc21f74f56708e8fb
Scott Pilgrim's Precious Little Life (Scott Pilgrim #1),Y446.08,5d5a4dfbc21f74f56708e8fc
Rip it Up and Start Again,Y298.75,5d5a4dfbc21f74f56708e8fd
"Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991",Y488.39,5d5a4dfbc21f74f56708e8fe
Olio,Y203.72,5d5a4dfbc21f74f56708e8ff