DDR:利用RGBD的基于维度分解残差网络的3D语义场景重建方法
目录
- 论文下载地址
- 论文作者
- 模型讲解
- [背景介绍]
- [论文解读]
- [总体结构]
- [DDR维度分解残差模块]
- [基础DDR]
- [深层DDR]
- [特征提取模块]
- [2D特征提取器]
- [2D转3D投影层]
- [3D特征提取器]
- [多级特征融合]
- [轻量级ASPP模型]
- [训练及损失]
- [结果分析]
- [数据集]
- [与其他方法的对比]
- [利用不同数据的对比]
- [利用不同ASPP结构的对比]
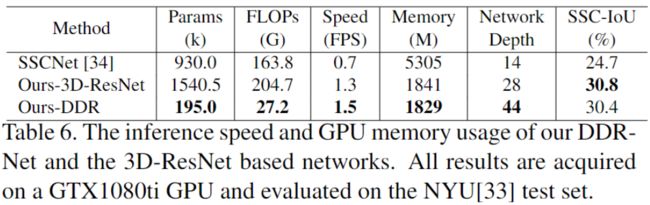
- [速度上的对比]
论文下载地址
[论文地址]
论文作者
模型讲解
[背景介绍]
RGB-D就是RGB和Depth图像的总称。RGB就是普通的可见光图像。Depth是深度图,每一个像素代表的是距离像素的距离,如下图所示:
上图中第一张是RGB图像。第二张是Depth图像,图中距离远的像素会更白,距离近的像素会更黑。
Semantic Scene Completion简称SSC,译为语义场景重建。SSC是3D场景理解的重要领域,SSC完成对三维空间的语义分割。对于传统语义分割任务,针对RGB图像进行语义分割,但是没有深度距离信息。所以对于SSC更加接近人类视觉感知。
常规方法通常利用手工制作的特征来表示3D对象形状例如体素特征,并利用图形模型来推断场景类别和语义。近几年深度学习的方法取得很好的效果,但是大多数都是为了获取速度而减少输入的分辨率大小。
对于单独的RGB图像,可以通过颜色或纹理信息轻松区分不同种类的物体。对于RGB-D图像,Depth和RGB图像是不同传感器获取的,都提供了场景信息。前者对物体的形状和距离有更多的信息,而后者则传递了有关物体纹理和显着性的更多信息。
如下图的NYUv2数据集所示,左边是RGB图像,中间是处理好的Depth图像,右边是3D语义分割结果。

[论文解读]
作者提出了一种维度分解残差(DDR)的模块,设计SSC的轻量级网络。
[总体结构]
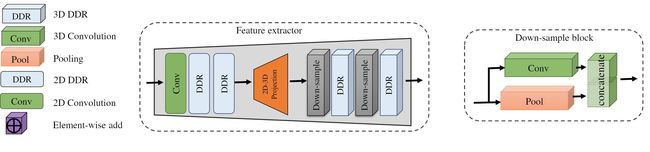
首先网络的输入为对齐的深度图和彩色图像,两者通过两个特征提取器获得对应的特征图。之后输入到多个DDR模块中,完成2D到3D的转化,融合多级特征。之后输入ASPP结构,ASPP是在DeepLabv3中首次提出目的是聚合多尺度的特征图。最后经过三个点卷积层预测最终的体素标签。

[DDR维度分解残差模块]
[基础DDR]
残差模块的公式是:
x t = F d ( x t − 1 , { W i } ) + x t − 1 x_t=\mathcal F^d(x_{t-1},\{W_i\})+x_{t-1} xt=Fd(xt−1,{Wi})+xt−1
其中, x t − 1 x_{t-1} xt−1是输入, x t x_t xt是输出, F d ( x t − 1 , { W i } ) \mathcal F^d(x_{t-1},\{W_i\}) Fd(xt−1,{Wi})是学习的残差映射,并具有 d d d的空洞。这种结构对梯度消失有很大的缓解。
将2D残差快应用于3D任务中,如下图(a),将其中的卷积块设计为两个3×3×3的三维卷积。以及(c)中的瓶颈结构:
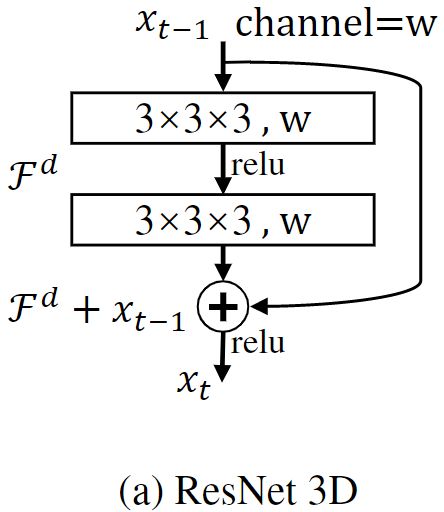
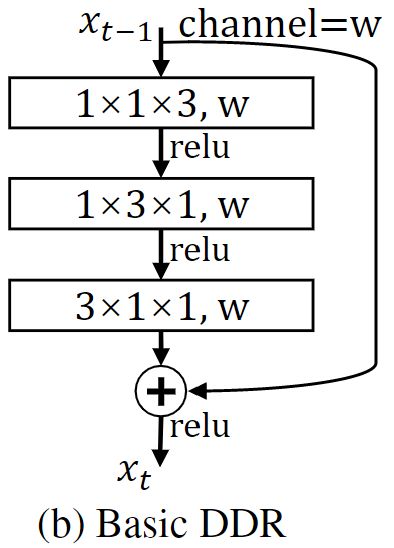
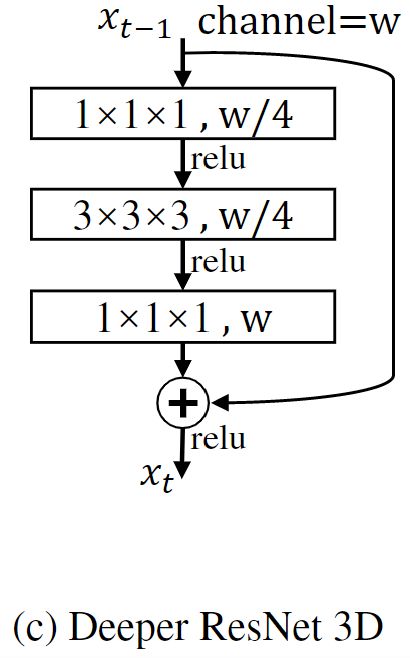

对于(a)(c)的改进,一种是减少计算量的(b)基础DDR结构。另一个(d)下一节讲解。
关于基础DDR结构较少计算量的有效性:假设输入通道数 c i n c_{in} cin,输出通道数 c o u t c_{out} cout,3D卷积核尺寸是 k x × k y × k z k^x×k^y×k^z kx×ky×kz,可以假设 k x = k y = k z = k k^x=k^y=k^z=k kx=ky=kz=k。那么对于基础DDR结构中,三次3D卷积核分别是 1 × 1 × k 1×1×k 1×1×k、 1 × k × 1 1×k×1 1×k×1、 k × 1 × 1 k×1×1 k×1×1。原始块与 c i n × c o u t × k × k × k c_{in}×c_{out}×k×k×k cin×cout×k×k×k成正比,基础DDR块与 c i n × c o u t × ( k + k + k ) c_{in}×c_{out}×(k+k+k) cin×cout×(k+k+k)成正比。
[深层DDR]
相对于基础DDR,一开始和最后加入 1 × 1 × 1 1×1×1 1×1×1的3D卷积层。另外其中还有一些直连结构,将对应层的输入直连到指定层的输入,类似于Dense块。
[特征提取模块]
网络中有两个平行的分支用于对彩色图像和深度图提取特征。特征提取模块主要包括3个组件:2D特征提取器,3D特征提取器和一个2D映射为3D的投影层。
[2D特征提取器]
首先使用点卷积提升通道数,之后接两个2D DDR模块,输出特征图与输入特征图保持一致。
[2D转3D投影层]
由于深度图中的每个像素对应于特征图中的张量,因此每个特征张量都可以投影到三维中具有相同深度值的位置。这样会对每个体素分配相应的特征张量。
对于未被任何深度值占用的体素,其特征向量将设置为零。其他整正常的像素位置 ( u , v ) (u,v) (u,v)的 T ( u , v ) T_{(u,v)} T(u,v)可以通过深度图 ( u , v ) (u,v) (u,v)的像素值和相机参数 C C C得到。
由于三维体积特征图的分辨率比二维特征图的分辨率要低,所以可能有重合的二维特征投影到相邻的体素中,这里使用最大池化模拟。
[3D特征提取器]
在投影层之后,获取3D特征图。使用两个3D DDR块提取特征。在每个DDR块的前面添加了一个下采样块,以减小特征图的大小并增加其通道的尺寸。下采样块的结构包含并行的一个池化层和一个逐点卷积层,以增加下采样块输出特征图的通道。
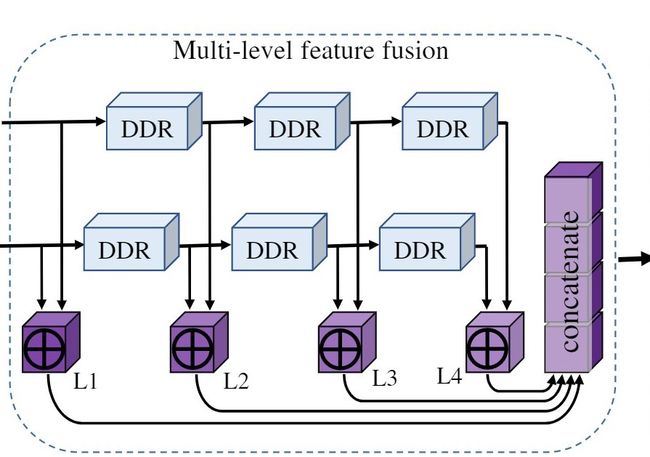
[多级特征融合]
通过多个DDR模块提取不同级别的特征,然后通过逐个元素添加将这些特征合并在一起。使用逐元素相法而不是其他操作的原因是因为可以简单地融合特征,而计算成本却很小。
通过级联的DDR块,既捕获了低级特征又捕获了高级特征,这增强了网络的表达能力,有利于语义场景完成任务。
[轻量级ASPP模型]
在室内场景中,不同的对象类别具有各种物理3D大小。这就要求网络捕获不同规模的信息,以便可靠地识别对象。ASPP通过使用具有不同空洞的多个并行滤波器来利用多尺度特征。
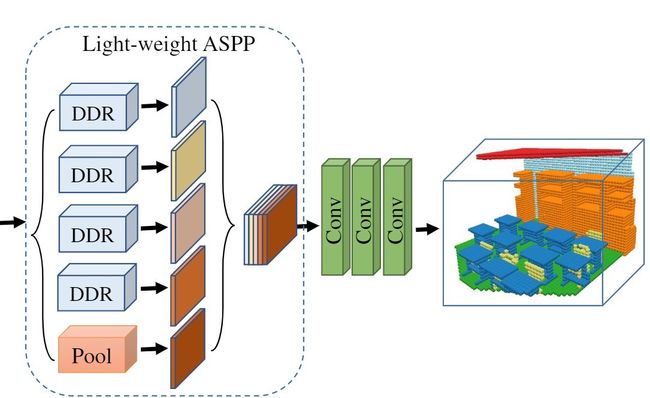
作者提出了一种轻量级的ASPP(LW-ASPP),能够处理规模可变性,同时需要较少的计算。LW-ASPP使用多个不同空洞的并行DDR块。从不同空洞提取的特征进一步级联进行融合,经过输出层生成最终结果,该输出层由三个3D点卷积层构成。
[训练及损失]
所有实验都是在GPU上使用PyTorch框架进行的。使用SGD优化器对模型进行了训练,该动量为0.9,衰减为10-4,批次大小为2,初始学习率为0.01,并且当训练损失在连续5个epoch内变化小于1e-4时,学习率除以10。
在未归一化的网络输出 y y y上使用softmax交叉熵损失:
L = − ∑ c = 1 N w c y ^ i , c log ( e y i , c ∑ c ′ N e y i , c ′ ) \mathcal L=-\sum_{c=1}^Nw_c\hat y_{i,c}\log(\frac{e^{y_{i,c}}}{\sum^N_{c'}e^{y_{i,c'}}}) L=−c=1∑Nwcy^i,clog(∑c′Neyi,c′eyi,c)
其中 y ^ i , c \hat y_{i,c} y^i,c是GT,体素 i i i被分为类别 c c c的话 y ^ i , c = 1 \hat y_{i,c}=1 y^i,c=1,否则 y ^ i , c = 0 \hat y_{i,c}=0 y^i,c=0。 N N N是总的类别数, w c w_c wc是损失权重。
[结果分析]
[数据集]
作者在NYUv2数据集上评估提出的方法。NYU包含1449个通过Kinect传感器捕获的室内场景。 按照SSCNet,使用提供的3D标签完成语义场景完成任务。另一个数据集是NYUCAD数据集。
[与其他方法的对比]


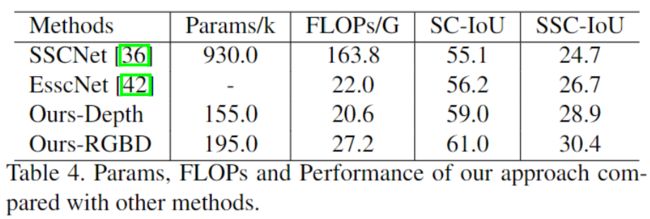
[利用不同数据的对比]

[利用不同ASPP结构的对比]
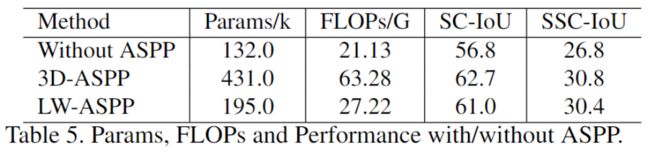
[速度上的对比]