统计学习方法-朴素贝叶斯(补充)
目录
前言:
距离度量:
实现代码:
scikit-learn实例
参考资料:
前言:
对于机器学习实战的时候,由于统计学习方法提及到的模型有三种:
模型:
- 高斯模型
- 多项式模型
- 伯努利模型
在这里再补充一个高斯模型的:
距离度量:

实现代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
# data
def create_data():
# 加载测试数据
iris = load_iris()
# 绘制数据表格
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 表格标签
df['label'] = iris.target
# 每一列的名称
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# 取前100个数据
data = np.array(df.iloc[:100, :])
# print(data[:, :-1]) 输入数据X
# print(data[:,-1]) 目标数据y
return data[:, :-1],data[:,-1]
X, y =create_data()
# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_test[0], y_test[0]
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# 标准差(方差)
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x - avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) /
(2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
# 处理X_train
# 关于zip 函数 按列压缩zip(*)解压
# https://blog.csdn.net/qq_39885465/article/details/103798407
def summarize(self, train_data):
# 数学期望和标准差
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分类别求出数学期望和标准差
def fit(self, X, y):
# 注意标签 是一个无序的列表
labels = list(set(y))
# 从数据中获取标签的数值
data = {label: [] for label in labels}
# 压缩后的X,y进行遍历
for f, label in zip(X, y):
# 在label追加X
data[label].append(f)
self.model = {
label:self.summarize(value)
for label, value in data.items()
}
return 'gaussianNB train done!'
# 计算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
for label, value in self.model.items():
# 初始化对应标签的数值为1
probabilities[label] = 1
for i in range(len(value)):
# 由于X_train是已经处理过的所以数据直接可以取得数学期望和方差
mean, stdev = value[i]
# 对应类别的关系是累乘,计算概率密度函数(可能性函数--调整因子)
probabilities[label] *= self.gaussian_probability(
input_data[i], mean, stdev)
return probabilities
# 类别,对每个类别进行降序的排序
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
# # lambda作为一个表达式,定义了一个匿名函数
label = sorted(
self.calculate_probabilities(X_test).items(),
key=lambda x: x[-1])[-1][0]
return label
#实际命中的与测试的概率 计算分数
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))
model = NaiveBayes()
model.fit(X_train, y_train)
print(model.predict([4.4, 3.2, 1.3, 0.2]))
model.score(X_test, y_test) 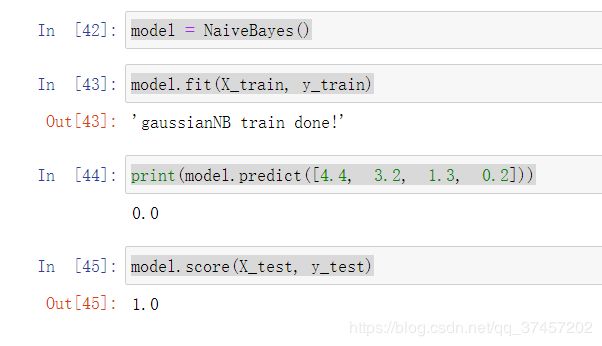
scikit-learn实例
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.predict([[4.4, 3.2, 1.3, 0.2]])
参考资料:
- https://cuijiahua.com/blog/2017/11/ml_5_bayes_2.html
- 统计学习方法-李航
- 统计学习方法-课后练习
- 机器学习实战
笔记会放在我的Github里面