教科书式爬虫:由浅入深爬取丁香园
前言
X先生最近太忙了,昨天刚刚完成数学建模比赛(过程很复杂,很辛酸),明天或后天给大家分享数学建模掉头发的故事,马上上课,天天几乎满课,时间真的滴滴答答的在走,恐慌和抱怨是没什么用了,X先生后面会更加努力,写出更多好的原创,清华大学出版社小姐姐送的数据挖掘十大算法可能是后面学习的重点,另外定个小目标:边学边敲边记这周至少更新两篇,这几天就转发分享给大家一些比较好的大佬的原创啦~(我也有偷偷在学他们敲代码的思想哦)
今天给大家分享的是一位研一学长写的爬取丁香园用户信息由浅入深的博文,认真读完本文需要30分钟左右,分为两部分:浅+深,大家可以收藏,分时间段阅读。
第一部分 : 浅
目录
0.写在前面
1.分析页面
2.获取页面源码
3.解析数据
4.数据存储及导出
4.1 数据存储
4.2 数据导出
5.pandas实现导出
6.面向对象封装
0.写在前面
(1)目标页面
http://i.dxy.cn/profile/yilizhongzi
(2)目的
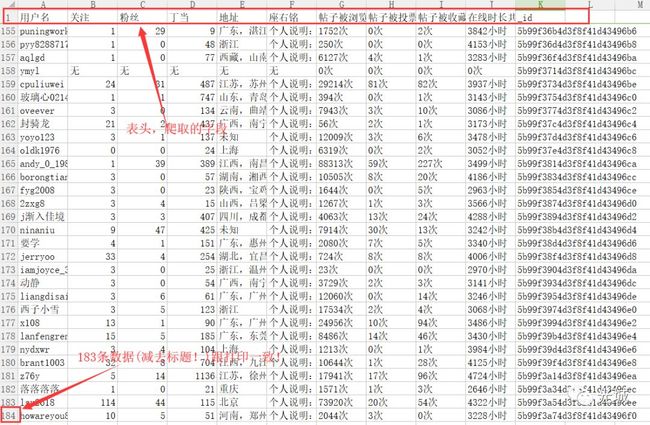
爬取丁香园用户主页的信息,这些信息如下图字段:

爬取字段图
也就是从用户主页提取这些数据,那么我们开始实战!
1.分析页面
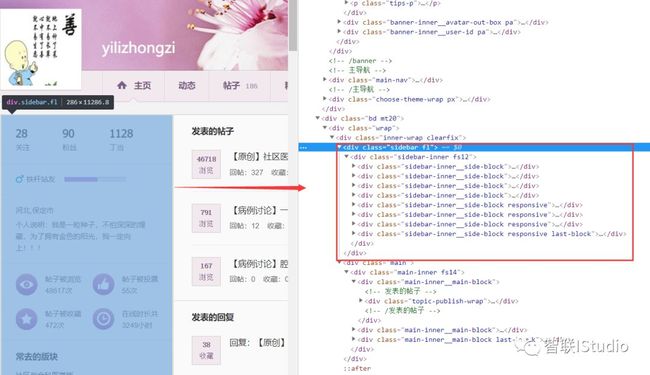
分析页面图
我们需要爬取的信息就是上述图中侧边栏信息,它对应的源码如图中红色方框所示!
思路
第一步:获取页面源码
第二步:通过xpath解析对应数据,并存储为字典格式
第三步:存储至MongoDB数据库,并利用可视化工具导出csv文件
第四步:存储至excel中(或csv文件)中
2.获取页面源码
def get_html(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
req = requests.get(self.url, headers=headers).text
# print(req)
return req
3.解析数据
xpath解析方法
以下面实际例子为例:
谷歌浏览器右键检查,页面分析源码,找到如下图的div,然后会发现class="follows-fans clearfix"里面包含这三个关注、粉丝、丁当相关信息。
那么通过xpath解析即可获取到相应的数据。具体的xpath语法,请参看网上资料,此处不做详细解释。只对相应语句添加相应注释。认真看注释!!!

元素提取图
'''
满足class值的div下面的所有p标签的text()属性,因为上述第一个p标签下面还有a标签,所有这里直接取的就是关注/粉丝/丁当这些字符串,每个对应的值28/90/1128,通过进一步定位到a标签进行解析。参看第二行代码。
'''
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')
下面对获取用户信息进行封装
import requests
from lxml import etree
def get_UserInfo(self):
raw_html = self.get_html()
selector = etree.HTML(raw_html)
key_list = []
value_list = []
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')
for each in force_fan_dd_key:
key_list.append(each)
for each in force_fan_dd_value:
value_list.append(each)
UserInfo_dict = dict(zip(key_list, value_list)) # 两个list合并为dict
# print(UserInfo_dict) # {'关注': '28', '粉丝': '90', '丁当': '1128'}
user_home = selector.xpath('//p[@class="details-wrap__items"]/text()')[0]
user_home = user_home.replace(',', '') # 去掉逗号,否则使用MongoDB可视化工具导出csv文件报错!
# print(user_home)
UserInfo_dict['地址'] = user_home
user_profile = selector.xpath('//p[@class="details-wrap__items details-wrap__last-item"]/text()')[0]
UserInfo_dict['座右铭'] = user_profile
# print(UserInfo_dict)
# 帖子被浏览
article_browser = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-topic fl"]/p/text()')
UserInfo_dict[article_browser[0]] = article_browser[1]
# 帖子被投票
article_vote = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-vote fl"]/p/text()')
UserInfo_dict[article_vote[0]] = article_vote[1]
# 帖子被收藏
article_collect = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-fav fl"]/p/text()')
UserInfo_dict[article_collect[0]] = article_collect[1]
# 在线时长共
onlie_time = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-time fl"]/p/text()')
UserInfo_dict[onlie_time[0]] = onlie_time[1]
# print(UserInfo_dict)
return UserInfo_dict
4.数据存储及导出
4.1 数据存储
import pymongo
MONGO_URI = 'localhost'
MONGO_DB = 'test' # 定义数据库
MONGO_COLLECTION = 'dxy' # 定义数据库表
def __init__(self, user_id, mongo_uri, mongo_db):
self.url = base_url + user_id # 这行代码与数据存储无关
self.client = pymongo.MongoClient(mongo_uri)
self.db = self.client[mongo_db]
def Save_MongoDB(self, userinfo):
self.db[MONGO_COLLECTION].insert(userinfo)
self.client.close()
MongoDB可视化工具:MongoDB Compass Community

MongoDB可视化工具图
安装好后,每次打开会提示连接数据库,这里就是不变动任何信息,直接点CONNECT即可!
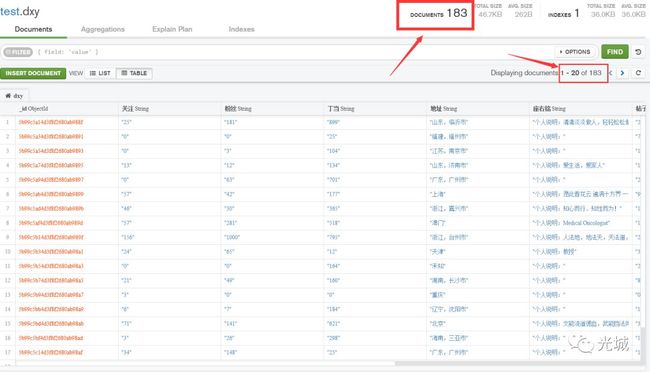
注意一个区别:Collection就是数据库的表!如下图就是test数据库中的dxy表。
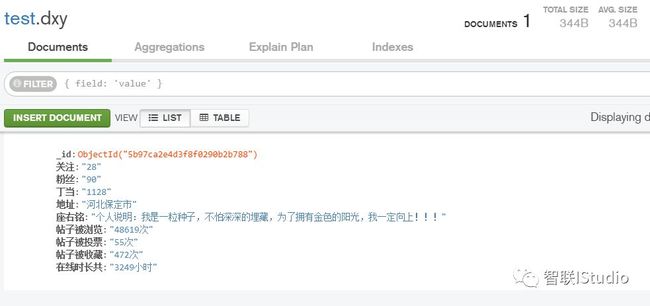
MongoDB存储结果图
4.2 数据导出
选择左上角的Collection->Export Collection,然后弹出如下图的框,选择导出格式及存储文件路径,保存即可!

导出结果
MongoDB导出结果图
5.pandas实现导出
import pandas as pd
def Sava_Excel(self, userinfo):
key_list = []
value_list = []
for key, value in userinfo.items():
key_list.append(key)
value_list.append(value)
key_list.insert(0, '用户名') # 增加用户名列
value_list.insert(0, user) # 增加用户名
# 利用pandas进行导出
data = pd.DataFrame(data=[value_list], columns=key_list)
print(data)
'''
表示以用户名命名csv文件,并去掉DataFame序列化后的index列(这就是index=False的意思),并以utf-8编码,
防止中文乱码。
注意:一定要先用pandas的DataFrame序列化后,方可使用to_csv方法导出csv文件!
'''
data.to_csv('./' + user + '.csv', encoding='utf-8', index=False)
6.面向对象封装
最后,采用面向对象思想对上述代码进行封装,什么是面向对象?问问你的对象吧,想查看源代码的可以在本公众号内回复:丁香园。
第二部分 :深
目录
0.写在前面
1.原理分析
2.代码实现
2.1 爬取bbs
2.2 用户个人主页
2.3 bbs与用户主页联合使用
0.写在前面
【高能预警】本节你可以学会什么?
第一:lxml及xpath使用
第二:模拟登陆处理
第三:多页面处理
第四:MongoDB存储
第五:使用pandas存储数据到csv
第六:数据下载
第七:列表、字典处理
第八:面相对象思想
第九:正则啊等等。。。。
【异常处理】
对于上一节的爬虫,只是做了个简单的数据爬取及存储,但是当遇见不同的个人主页时,代码就会报错,数据就会错落,为了更好的解决这个问题,本节即对上节代码进行优化及异常处理。
【bbs数据提取】
除了对代码异常处理之外,还需要使得我们的代码更加智能化,我们本次实现的功能是:随便传入一个类似的bbs链接,即可获取到当前bbs里面的所有的回复用户的用户数据,从这个需求中我们提取中两个关键点。
第一:爬取bbs里面的回复用户;
第二:爬取用户数据;
第二点上节基本上已经实现,那么重点放在第一点的讲解及异常处理等。好了,废话不多说,开始实战!
【项目目录】
├─data
这里面存放每个用户的头像
├─each
这里面存放每个用户的csv数据
├─raw_demo
dxy_raw_profile.py # 上一节的爬取用户主页代码
all.csv # 这个是生成的文件,代码运行后才有,是对each里面的所有csv文件的集合
bbs_genspider.py # bbs论坛代码
dxy_profile.py # 用户主页代码 最后运行只需运行这个即可,记得替换raw_id = '3927842'
【项目使用】
根据上述项目目录修改raw_id,除此之外,需要本地安装mongodb,并创建数据库名为test,collection为dxy,记得运行前修改bbs_genspider.py里面的cookie,最后运行dxy_profile.py即可。
1.原理分析
先来看一下我们爬取的网站长什么样子?
bbs论坛

bbs论坛图
用户个人主页

用户个人主页图
以上就是我们要爬取的目标站点。
对于第一张图,红色框图标注出来都就是我们想要爬取的目标用户,除了我标注的,bbs还有其他人的回复,由于上图的楼主回复的太多,图片截不出后面其他回复用户,大家可以根据图一中的url进行检验。
【第一个问题】
那么现在问题来了,是不是我直接爬取那个bbs(如图1)的url,定位到左侧边栏的每一个用户,找到对应的用户名就可以了?
答:答案是对的,确实如此解决,我们上一节知道如图2所示,用户主页为http://i.dxy.cn/profile/用户名,那么只要替换不同的用户名,便可以实现多个用户的爬取,哈哈,终于有数据了~~~
现在是时候轮到bbs发话了,那么问题又来了,如何从bbs中爬取相应的用户名呢?不着急,我们看图说话!

爬取用户名图
【第二个问题】
看出什么端倪了?
答:只要我们利用xpth定位到a标签的text()值,便可以迎刃而解了~~~
【第三个问题】
最后代码爬取完,发现怎么数据这么少呢?
答:结果发现是用户未登陆,那么你只能爬到几个数据,可是我要做研究啊,没数据,怎么搞,接下来就是模拟登陆上场了,这里的模拟登陆没有那种高大上的selenuim,也没有Session(), 而是采用了最为低调的requests添加cookie方式。
【第四个问题】
最后会发现还是觉得数据少啊,发现这个bbs有多页面,这个又该如何处理呢?
答:那么我们不妨尝试一下,点击下一页,看有什么规律嘛,果不其然,被我瞄到了~~~我们看图说话
注意:下图中的链接为bbs链接!
bbs链接图
每变动一页,会发现在id后面多了个?ppg=6,我们会发现此处的6正是页数,我们再来看一张图:
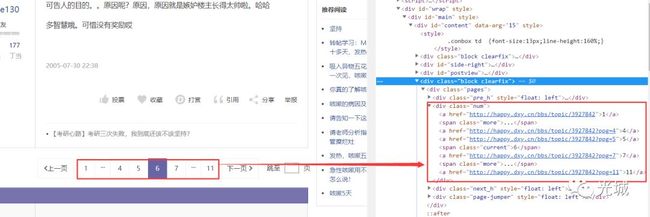
多页面分析图
那么只需要通过xpath定位到 【第五个问题】 但是当单页面时候,它就不会有这个 答:直接做个异常处理,然后设置page为1即可解决! bbs的url前缀 base_url = 'http://www.dxy.cn/bbs/topic/' # 在类外面 封装成类 class bbs_genspider(object): 获取html页面(注意填写自己的cookie!) def get_html(self): 注意事项:填写自己的cookie,填写的是登陆成功后的cookie! import requests 注意事项:此处返回的数据为当前bbs的所有回复用户,那么问题来了,既然是回复用户,当然有些用户回复了很多次,相当于此处获得的是最原始的所有回复用户数据,那么如何去重呢?请往下看! 获取所有页面的Url # 获取所有页面的Url bbs用户数据去重 # 删除重复的用户 注意事项: 为什么获取了头像地址呢,原因很简单,想下载到本地以供往后头像的选择! 【说在最后】 上述所有方法全部封装在类里面即可。 测试 raw_id = '12345' 测试结果图 上述测试的是单页面,然后打 用户个人主页功能在上一节做了详细解释,这一节主要侧重于异常的处理及如何调用bbs代码,将bbs代码与个人主页代码结合使用。 上一节保持不变代码如下: 【基本框架】 import requests 注意:与上节相比,唯一变动的是 大改动如下: 【异常处理】 语法: try: 实战: def get_UserInfo(self): 【解释】 这里采用异常处理原因如下: 异常结果图 上图我们发现壹刀的数据乱了,那么我们现在进入这个人的主页来看。浏览器输入 壹刀主页图 会发现这个已经不是我们想要的用户页面图了。。。所以自然那些数据爬取不到,就会报错。。这样就得加异常处理!如下图所示为加异常处理后的结果,会发现已经对齐! 正常结果图 异常处理前,数据不对齐,还有另外一种就是这个人的用户主页没了。。。对,没错就是404。。。 如:浏览器打开 404页面图 【下载头像】 def DownLoadUserAvater(self, bbs_avater, bbs_id): 【程序调用】 if __name__ == '__main__': 【效果呈现】 终端log 用户名结果图 头像链接结果图 数据库 本地 MongoDB数据存储结果图 本地头像数据图 本地单个用户数据图 最后的最后,如果您觉得这篇文章对您的有帮助,请点赞转发留言支持一下。 后言 本文作者是本公号第一个投稿作者,也是第一个签约长期作者。 作者简介:Light-City(光城),自学编程,最近致力于学习Python,知识图谱,网络爬虫等,个人博客:http://light-city.me,个人公众号:光城,id:guangcity。 本文最终解释权归原作者所有,转载联系原作者。 本公众号内回复:丁香园,获取两部分源码,记得给作者一个Star哦~ 往期精彩 进学习交流群 扫码加X先生微信进学习交流群 温馨提示 欢迎大家转载,转发,留言,点赞支持X先生。 文末广告点一下也是对X先生莫大的支持。a标签即可,这个规律为从打开多个bbs链接中发现的!
2.代码实现
2.1 爬取bbs
def __init__(self, id):
self.url = base_url + id # 与base_url拼接成真实地址
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '填写自己的cookie',
'Host': 'www.dxy.cn',
'Referer': 'https://auth.dxy.cn/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
req = requests.get(self.url, headers=headers).text
return req
xpath解析
from lxml import etree
def get_BbsInfo(self):
raw_html = self.get_html()
selector = etree.HTML(raw_html)
# 提取bbs标题
bbs_title = selector.xpath('//table[@class="title tbfixed"]/tbody/tr/th/h1/text()')[0]
bbs_title = bbs_title.strip() # 去除字符串左右的空格
print(bbs_title)
# 头像
bbs_other_avater = selector.xpath('//td[@class="tbs"]//div[@class="avatar"]/div/span/a/img/@src')
print(bbs_other_avater)
# 用户名
bbs_other_id = selector.xpath('//td[@class="tbs"]//div[@class="auth"]//a/text()')
print(bbs_other_id)
# 处理单页面异常!
try:
page = selector.xpath('//div[@class="pages"]/div[@class="num"]/a[last()]/text()')[0]
print(page)
except IndexError as e:
page = 1
'''
到这里,我们得到了当前bbs的所有回复用户的信息
bbs_other_avater 用户的头像地址
bbs_other_id 用户的用户名
page 页面数量
'''
return bbs_other_id,bbs_other_avater,page
def get_AllPageUrl(self, raw_id):
bbs = bbs_genspider(raw_id)
bbs_other_id, bbs_other_avater, page = bbs.get_BbsInfo()
page_list = []
for i in range(1, int(page) + 1):
page_url = raw_id + '?ppg=' + str(i)
page_list.append(page_url)
return page_list
def del_common(self, raw_id):
page_list = self.get_AllPageUrl(raw_id)
data_bbs = {}
for url in page_list:
bbs = bbs_genspider(url)
bbs_id, bbs_avater, page = bbs.get_BbsInfo()
bbs_data = dict(zip(bbs_id, bbs_avater)) # 两列表合并成字典
for key in bbs_data:
if key not in data_bbs:
data_bbs[key] = bbs_data[key]
bbs_id = []
bbs_avater = []
for key in data_bbs:
bbs_id.append(key)
bbs_avater.append(data_bbs[key])
return bbs_id, bbs_avaterget_BbsInfo()返回的id及avater都是列表,那么此处的去重就是解决上述问题的去重,也就是说list去重操作。这里采用的算法思想是通过zip()函数将两个list合并成字典,key为id,value为avater,那么现在问题就变为了字典去重,先定义一个新的字典,如果当前添加的数据不在新的字典里面,就往里面加,最后就得到了一个去重后的字典,对字典进行拆分为两个列表即可,返回后的两个列表就是我们最后所需要的数据。
bbs = bbs_genspider(raw_id)
bbs_id,bbs_avater = bbs.del_common(raw_id)
print("----------------------------------")
print(bbs_id)
print(len(bbs_id))
print(bbs_avater)
print(len(bbs_avater))
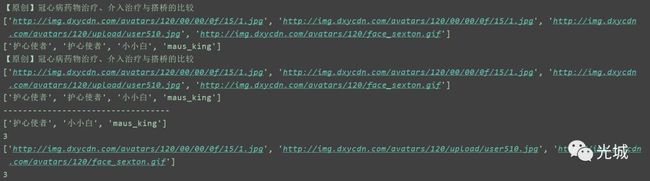
www.dxy.cn/bbs/thread/12345,自己数一下(记得去重),便跟上述打印的结果数量3一样!到这里便测试成功了!2.2 用户个人主页
from lxml import etree
import pymongo
import pandas as pd
from urllib.request import urlretrieve
from bbs_genspider import bbs_genspider
base_url = 'http://i.dxy.cn/profile/'
MONGO_URI = 'localhost'
MONGO_DB = 'test' # 定义数据库
MONGO_COLLECTION = 'dxy' # 定义数据库表
class dxy_spider(object):
# 初始化
def __init__(self, user_id, mongo_uri, mongo_db):
self.url = base_url + user_id
self.client = pymongo.MongoClient(mongo_uri)
self.db = self.client[mongo_db]
# 获取html
def get_html(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
req = requests.get(self.url, headers=headers).text
# print(req)
return req
def Save_MongoDB(self,userinfo):
self.db[MONGO_COLLECTION].insert(userinfo)
self.client.close()
# 每个用户信息存储至csv文件
def Sava_Excel(self, userinfo):
key_list = []
value_list = []
for key, value in userinfo.items():
key_list.append(key)
value_list.append(value)
key_list.insert(0, '用户名') # 增加用户名列
value_list.insert(0, user) # 增加用户名
data = pd.DataFrame(data=[value_list],columns=key_list)
print(data)
'''
表示以用户名命名csv文件,并去掉DataFame序列化后的index列(这就是index=False的意思),并以utf_8_sig编码,
防止中文乱码。
注意:一定要先用pandas的DataFrame序列化后,方可使用to_csv方法导出csv文件!
'''
data.to_csv('./each/' + user + '.csv', encoding='utf_8_sig', index=False)data.to_csv('./' + user + '.csv', encoding='utf-8', index=False),修改为data.to_csv('./each/' + user + '.csv', encoding='utf_8_sig', index=False),防止有些电脑打开csv文件乱码!
xxxx
except Exception as e:
xxx
raw_html = self.get_html()
selector = etree.HTML(raw_html)
key_list = []
value_list = []
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')
if '关注' in force_fan_dd_key:
for each in force_fan_dd_key:
key_list.append(each)
for each in force_fan_dd_value:
value_list.append(each)
else:
key_list = ['关注', '粉丝', '丁当']
value_list = ['无', '无', '无']
UserInfo_dict = dict(zip(key_list, value_list)) # 两个list合并为dict
# print(UserInfo_dict) # {'关注': '28', '粉丝': '90', '丁当': '1128'}
try:
user_home = selector.xpath('//p[@class="details-wrap__items"]/text()')[0]
# user_home = user_home.replace(',','') # 去掉逗号,否则使用MongoDB可视化工具导出csv文件报错!
user_home = user_home.replace(',', ',') # 改变英文逗号为中文逗号,否则使用MongoDB可视化工具导出csv文件报错!
print(user_home)
UserInfo_dict['地址'] = user_home
except IndexError as e:
UserInfo_dict['地址'] = '无'
print('地址缺少,报错!')
try:
user_profile = selector.xpath('//p[@class="details-wrap__items details-wrap__last-item"]/text()')[0]
user_profile = user_profile.replace(',', ',') # 改变英文逗号为中文逗号,否则使用MongoDB可视化工具导出csv文件报错!
UserInfo_dict['座右铭'] = user_profile
except IndexError as e:
UserInfo_dict['座右铭'] = '无'
print('座右铭缺少,报错!')
# 帖子被浏览
try:
article_browser = selector.xpath(
'//li[@class="statistics-wrap__items statistics-wrap__item-topic fl"]/p/text()')
UserInfo_dict[article_browser[0]] = article_browser[1]
except IndexError as e:
UserInfo_dict['帖子被浏览'] = '0次'
print('帖子被浏览缺少,报错!')
# 帖子被投票
try:
article_vote = selector.xpath(
'//li[@class="statistics-wrap__items statistics-wrap__item-vote fl"]/p/text()')
UserInfo_dict[article_vote[0]] = article_vote[1]
except IndexError as e:
UserInfo_dict['帖子被投票'] = '0次'
print('帖子被投票缺少,报错!')
# 帖子被收藏
try:
article_collect = selector.xpath(
'//li[@class="statistics-wrap__items statistics-wrap__item-fav fl"]/p/text()')
UserInfo_dict[article_collect[0]] = article_collect[1]
except IndexError as e:
UserInfo_dict['帖子被收藏'] = '0次'
print('帖子被收藏缺少,报错!')
# 在线时长共
try:
onlie_time = selector.xpath(
'//li[@class="statistics-wrap__items statistics-wrap__item-time fl"]/p/text()')
UserInfo_dict[onlie_time[0]] = onlie_time[1]
except IndexError as e:
UserInfo_dict['在线时长共'] = '0次'
print('在线时长共缺少,报错!')
return UserInfo_dict![]()
http://i.dxy.cn/profile/壹刀,会发现重定向进入http://i.dxy.cn/lizhanqiang这个页面,如下图所示: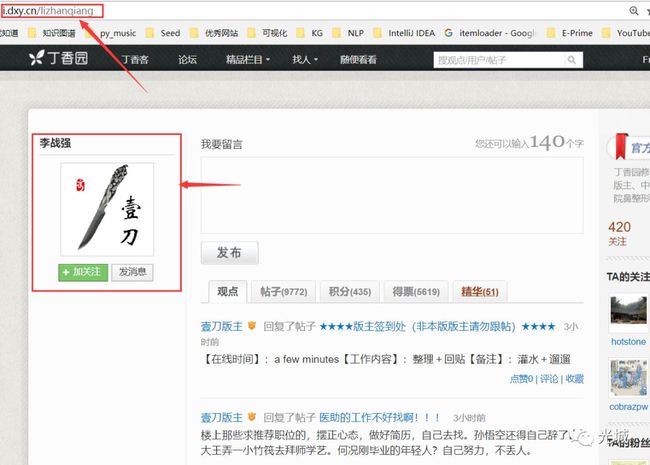
![]()
http://i.dxy.cn/ymyl,会看到下图所示页面,直接404了,自然没数据,没数据,自然报错,这就是异常处理的作用!
2.3 bbs与用户主页联合使用
urlretrieve(bbs_avater, './data/{0}.jpg'.format(bbs_id))
raw_id = '3927842'
bbs = bbs_genspider(raw_id)
bbs_id,bbs_avater = bbs.del_common(raw_id)
print("----------------------------------")
print(bbs_id)
print(len(bbs_id))
print(bbs_avater)
print(len(bbs_avater))
i = 0
for user in bbs_id:
dxy = dxy_spider(user, MONGO_URI, MONGO_DB)
userinfo = dxy.get_UserInfo()
print('-----------')
print(userinfo)
dxy.Save_MongoDB(userinfo)
dxy.DownLoadUserAvater(bbs_avater[i], user)
dxy.Sava_Excel(userinfo)
# 合并each里面所有的单个用户数据,并存储至all.csv
df = pd.read_csv('./each/' + user + '.csv', engine='python', encoding='utf_8_sig')
if i == 0:
df.to_csv('all.csv', encoding="utf_8_sig", index=False, mode='a+', header=True)
else:
df.to_csv('all.csv', encoding="utf_8_sig", index=False, mode='a+', header=False)
i += 1