优化算法分析:从q群智能优化到优化技巧
- 4. 群智能算法简介
- 4.1 遗传算法
- 4.2 模拟退火算法
- 5.优化技巧
- 5.1 正则化
- 5.2 集成模型
- 5.3 Dropout随机失活
- 6.优化算法分析
- 6.1 基于梯度的优化
- 6.2 基于二阶近似的优化
- 6.3 群智能优化
- 6.4 集成优化思想
4. 群智能算法简介
“认识世界,建设世界”是人类的一切活动的根本。认识世界靠的是建立模型,建设世界靠的是优化模型。特别是在大数据时代,模型越来越复杂,数据越来越多,优化模型就变得更加重要了。
前面我么说了很多种优化模型的算法以及对应的优化思想,但它们都存在这一些本质上的局限性,单点的计算使得效率很难提高,向改进的方向迭代很容易就会陷入局部最优,而且对目标函数的各种约束大大限制了优化算法的使用范围。所以,在大规模,分布式的情况下,为了取得更好的训练效果,我们必须对多个模型进行优化,这就用到群智能算法了。
群智能的算法有很多种,但大多数都有一个共性,那就是模仿。比如遗传算法的思想来源于生物进化,粒子群算法来源于鸟群,鱼群或者蜂群的运动规律,模拟退火算法来源于物理学,等等。本文并不能穷尽所有群智能算法,所以挑选比较常用且典型的智能优化算法来讨论。
4.1 遗传算法
前面说到的梯度下降法是在单点下进行计算的,但现在计算的数据量非常大,单点计算使得效率很难提高,当梯度下降时,很容易就陷入了局部最优里去,因为梯度下降法是针对凸目标函数的,所以就需要一些更好的算法,在不同的应用场景中使用,而遗传算法属于群智能算法中的一种,针对大规模数据和模型有非常好的效果,且操作和实现都比较简单。因此,本文将着重讲解遗传算法。
遗传算法的思想主要借鉴于达尔文的自然选择进化论和有性生殖的过程。物种进化主要通过遗传变异和生存竞争,在繁殖过程中,染色体交叉重组,或者基因变异带来了形形色色的不同个体。基于此,可以模仿得到遗传算法的计算步骤如下:
- 首先随机化地产生一个初始种群
- 然后根据优化问题的目标函数确定一个适应度函数,计算个体的适应值,适应值代表群体中个体的生存机会
- 根据适应值的大小决定的概率分布来进行选择,适应值越大,该个体遗传到下一代的概率就越大
- 根据特定的交叉概率和交叉方法,生成新的个体
- 根据变异概率和变异方法,生成新的个体
- 由4,5步产生新的种群,返回到2
为了实现算法,我们需对适应度进行计算,一般可以对适应值按比例来分配,也就是按照各个个体适应值的概率来选择,假设每个个体i的适应值为,则它被选取的概率计算公式如下:
父代:00000000001111111111
母代:00011100001100011100
子代:00000000001101011100
如上,便是完成了一次交叉组合及突变。笔者对算法进行了Python代码实现,为了便于可视化,把二进制转换成十进制,如下图代表不同的DNA片段,纵轴表示适应值,对迭代的过程进行可视化,如图4为迭代终止图:
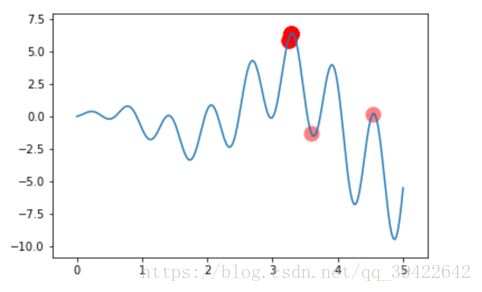
图4
可得该遗传算法能得到的最优解确实为适应值最高的那个点。
4.2 模拟退火算法
在一般的优化问题中,防止算法陷入局部最优解一直是某些算法的难点,对于基于梯度的算法,如果优化的目标函数不是一个凸函数,那它的表现就会很差,因为它非常地容易陷入局部的最优解。如果能在算法达到最优解之后,仍然有一定的概率能在最优解附近选择,继续寻找最优解,就有可能发现目前的解只是局部的最优解,这也是模拟退火算法的一个优点。
模拟退火算法是模仿物理学中的退火现象的。在热力学中,如果一块金属物体被加热到一定程度,撤去外部热源,物体的温度就比日常温度高,热量是从高温物体转向低温物体的,所以金属物体的温度会逐渐降低,这个过程就成为退火。

如图所示,模拟退火算法在找到局部最低点后,并没有停止迭代,而是以一定的概率继续向前走,这个概率根据退火的原理,是越来越小的,由此可以跳出局部最优,进而找到全局最优解。接下来的问题是我们该如何确定这样的概率呢?
温度为 Tk T k 时,在系统退火过程的n个状态中,处于状态 i i 的概率为:
该方程被称为Boltzmann方程。对于两个状态 i,i+1 i , i + 1 :
- 如果对应的能量状态 Ei>Ei+1 E i > E i + 1 ,则接受能量状态从 i i 转到 i+1 i + 1
- 否则,以概率 PI=exp(−(Ei+1−Ei)kt) P I = e x p ( − ( E i + 1 − E i ) k t ) 来接受能量状态从 i i 转到 i+1 i + 1
其中的k为常数。该概率表达的意思是温度越高,出现温度差为 Ei+1−Ei E i + 1 − E i 的降温概率就越大,所以说随着温度越来越低,相应的概率也会越来越大,这也是退火的原理。
5.优化技巧
在一般的机器学习,深度学习中,使用优化算法是非常重要的一步,但每种优化算法都有一定的适用范围,且每种算法有时候的表现也不是很好,这就需要我们在训练模型的时候能做出一些相应地调整,以满足现实问题的需要。所以在本章中,将会介绍一些在工业界非常常用的优化技巧,使我们能训练处更好的模型。而且会着重介绍机器学习,深度学习领域的优化技巧,比如正则化,早停,随机失活等,这些技巧目前都是应用最广泛的技巧。
5.1 正则化
在训练模型时,我们经常会遇到因为数据太少,或者无用的特征太多,使得我们训练出来的模型过于复杂,不能用于正常的业务使用。针对这种的问题,从根源出发,我们大致有两种解决方案:
- 通过让部分特征的权重参数等于零,以模型的复杂度,产生稀疏模型
- 通过让大部分特征的权重参数趋近于零,以降低每个特征的对结果的影响能力
其实这两种思路分别对应L1正则化和L2正则化。一般情况下,在把数据用于模型训练之前,我们已经人工的选择丢弃了一些对分类结果没什么用的数据,剩下的特征都是我们觉得有用的。如果此时训练出的模型依然表现出过拟合,也就是模型太复杂了,该怎么办呢?这时候我们可以试图去除一些特征,也就是让特征对应的权重参数为0.所以,可以在优化的目标函数 L(x) L ( x ) 后面加一个正则化项:
这里的 α α 称为惩罚因子, ||w||1 | | w | | 1 表示L1范数,即权重参数的绝对值,相当于为每一个权重参数都设置了一个惩罚项,来让模型自动选择对分类结果其较大作用的特征,很多人也称这种现象为稀疏化权重参数,即权重参数减少了。
另外一种做法就是削弱每个特征对结果的影响能力,即让大部分特征趋近于零,这个是可以实现的。以梯度下降法为例, θ θ 相当于权重参数 w w ,假设目标函数为:
代入先前我们说的迭代公式,可得梯度下降法的迭代公式为:
学习率为 α α ,如果在目标函数后面再加上一个L2范数(对所有参数求平方和,然后再开根号),惩罚参数为 λ λ 可以表示为:
那么,梯度下降的迭代公式就会变成:
再化简,可得:
化简可见,每一次迭代,相应的权重参数都会先乘以一个小于1的数,如此不断迭代,几乎所有的参数都会趋向于0,这样每个特征对结果的影响都会变小。在训练模型时,就不会因为某个权重参数相对较大,同时,它对应的特征是噪声数据,使得拟合函数产生剧烈的振动。
5.2 集成模型
集成模型主要指的是机器学习中的Bagging和Boosting。它们分别对应两种不同的思想。
俗话说,三个臭皮匠,顶一个诸葛亮,集成模型也是这个想法。在一大堆数据集面前,肯定有一些特征是对模型预测其干扰作用的,且人工很难排除,如何能减弱它们的干扰呢?在一个模型中全部加入所有数据,其中就包含了很多噪声数据,所以我们可以把数据分开,用不同的数据训练不同的模型,然后把所有模型的预测结果汇总起来,得到最终更好的模型,这就是集成模型的思想。
对于Bagging来说, 它是随机抽取k个样本组成训练集,然后再取m个分类能力强的特征训练一个分类模型,决策树模型与决策树模型之间没有互相依赖的关系,最后的分类结果通过线性加权平均或者投票决定。
而对于Boosting来说,它会进行多轮迭代,每次迭代都会增大分类错误的样本权值,让模型更加注重分类错误的样本,使得这些样本在下次迭代中能被正确分类,所以Boosting是树间强依赖的。最终结果也是通过线性加权平均或投票决定,这是集成模型的两种思想。
5.3 Dropout随机失活
Dropout可以认为是集成模型思想在神经网络中的应用。对于深度神经网络,如果隐藏层很多的话,相应的深度学习模型会表现地非常复杂,因此,我们可以为每个神经元节点设定一定概率,决定在该轮迭代中该神经元节点是处于打开还是关闭的状态,如果是打开的话,就与其他打开的节点全连接,如果关闭的话,相当于在该层上这个神经元节点不存在,形成如右图所示的深度学习模型,这也是为什么Dropout被称为随机失活的缘故。

在一定程度上,随机失活为模型带来了很大的随机性,相当于Bagging中,采用不同的数据集训练不同的模型一样。为了最后的集成,神经网络采用的方式和Bagging这种简单投票的方式不同,因为我们引入了一个随机失活的概率,所以和一般的神经网络相比,我们还要多计算一步。对于一般的神经网络,也就是不使用随机失活的神经网络(如下左图)
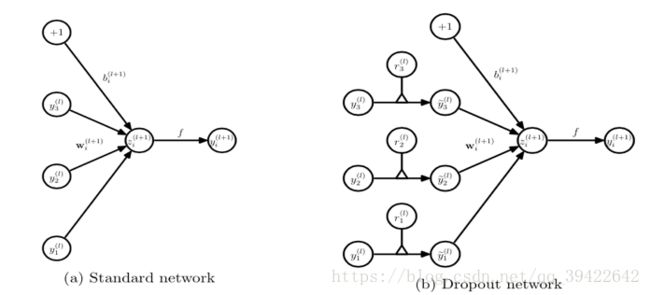
它的组合方式为:
然后再经过激活函数进行激活:
对于加了随机失活的神经网络,每一层的神经元节点还要乘以一个概率,决定改节点是否被激活使用,这个概率一般取自伯努利分布,有
对于上一层的每一个输出 y(l)i y i ( l ) ,乘以一个概率可得:
然后再乘以这个节点对应的权重参数:
最后同普通神经网络一样经过激活函数激活得到该节点对应的输出:
同时,预测的时候也要乘以训练时相同的概率,否则模型的参数就无法被保留下来了。
6.优化算法分析
经过前面五章,相信你已经了解优化算法的思想和基本的一些实现方式了,本章就来讨论一下各种优化算法的思想,和相应的优势和劣势,以此看一下它们未来的发展方向将会如何。
6.1 基于梯度的优化
基于梯度的优化算法是目前在机器学习,深度学习应用最广泛的一类算法,主要原因是此类算法具有严密的数学推导,同时小批量梯度下降法能被用于大数据集上的应用。
其算法的基本思想就是梯度给算法指明方向,迭代逼近最优解的方向。就像一个企业做一个产品一样,用户的体验指导了产品的迭代方向,而基于梯度算法的迭代方向则是梯度,也正因如此,基于梯度的优化算法很容易取得局部最优解。而迭代,就像一个产品的一个个版本一样,所以,基于梯度的迭代算法思想既简单又深刻,在未来人工智能领域的应用相信也不会少。
6.2 基于二阶近似的优化
基于二阶的近似算法,比如牛顿法最大的劣势就是计算量。如果优化的问题是n维的,一阶的梯度下降法计算复杂度为 O(n) O ( n ) ,但牛顿法的计算复杂度为 O(n3) O ( n 3 ) ,要知道,如果用在深度学习的神经网络中,n可是神经元节点的数量,即使是一般的神经网络,大概也有 104 10 4 左右,面对这么大的缺陷,牛顿法即使求解的精度再高,也很难弥补计算复杂度的劣势。因此,在深度学习领域,基于二阶的近似优化算法暂且不太实用。
但随着计算能力的提升,如果将来基于二阶近似的优化算法能一定程度的降低复杂度,因其具有非常高的精度,仍然是一个非常值得研究的领域。
6.3 群智能优化
群智能优化算法的主要思想就是模仿自然界的各种现象,而且是跨学科,跨领域的模仿,然后将产生各种现象的关键指标量化,形成数学模型,用于优化。比如生物学的自然选择,遗传和进化,物理学的模拟退火,还有自然界的鱼群,蚁群活动。
群智能优化的最大特点就是多。只能在很多模型的时候,使用群智能优化算法才能真正地体现它的优势。而未来的发展趋势,数据一定会越来越大,人工智能一定会越来越智能,需要各种各样的模型一起来实现各种功能,所以却只能优化在未来的发展空间一定非常可观。而且随着人工智能,大数据的普及,目前相关的研究也越来越多,相信它的应用一定会越来越广泛。
6.4 集成优化思想
正则化的机器学习和深度学习的广泛应用,集成模型的的思想在机器学习的成功应用,都说明了一个道理:群体力量的伟大。而Dropout则可以认为是正则化和集成模型的结合,并在深度学习模型中成功应用,并取得了非常好的效果。
它们都有两个特点,那就是随机性和集体智慧。正则化相当于让模型自己选择了一部分特征,让其他特征在分类中几乎不起作用,相当于对特征进行了一定程度的约束;而集成模型选择的子数据集是随机的,选择的特征也是随机的,最后把各个子模型的结果汇总起来,是相当于黑帮老大听取了各个小弟的汇报之后才开始做决策;而Dropout则对它们的两种思想进行整合,利用概率对神经元节点随机选择,一个神经元对应一个参数,也就相当于对特征进行了随机选择,然后通过神经网络模型的连接功能,把各个小弟的意见汇总到一起,进行决策,使得其能成功应用于神经网络的训练。
事实上,Dropout的思想和生物学的有性繁殖有着异曲同工之妙。在遗传算法中,我们曾说在繁殖过程中,伴随着染色体的分离与交叉重组,显然,基因只有在随机组合时,才给人类各种各样的惊喜。Dropout不就是强迫神经元之间随机组合,产生各色各样的神经网络,然后组合起来就可以达到非常好的效果。
在这里,是不是找到了优化算法的某些共通之处呢?是的,优化思想在底层上为人们解决优化问题提供了非常多的思路,而且在不同的领域相互借鉴,相互学习,产生了现在的优化领域。