【Python】基于sklearn构建并评价分类模型(SVM、绘制ROC曲线等)
本博客主要代码基于:
《Python数据分析与应用》第6章使用sklearn构建模型
【 黄红梅、张良均主编 中国工信出版集团和人民邮电出版社,侵请删】
相关网站链接
一、构建SVM分类模型
1、SVC分类,SVR回归
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
具体理论知识这里不细究,但这块知识点真的很重要!
2、书上源代码
# 代码 6-17
## 加载所需的函数,
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer()
cancer_data = cancer['data']
cancer_target = cancer['target']
cancer_names = cancer['feature_names']
## 将数据划分为训练集测试集
cancer_data_train,cancer_data_test, \
cancer_target_train,cancer_target_test = \
train_test_split(cancer_data,cancer_target,
test_size = 0.2,random_state = 2)
## 数据标准化
stdScaler = StandardScaler().fit(cancer_data_train)
cancer_trainStd = stdScaler.transform(cancer_data_train)
cancer_testStd = stdScaler.transform(cancer_data_test)
## 建立SVM模型
svm = SVC().fit(cancer_trainStd,cancer_target_train)
print('建立的SVM模型为:\n',svm)
## 预测训练集结果
cancer_target_pred = svm.predict(cancer_testStd)
print('预测前20个结果为:\n',cancer_target_pred[:20])
3、对应运行结果

二、评价分类结果
1、分类模型评价方法简介
我最早了解到分类评价方法的一篇博客:分类-MNIST(手写数字识别)

2、分类模型评价报告函数:classification_report
机器学习笔记--classification_report&精确度/召回率/F1值
3、源代码
# 代码 6-18
## 求出预测和真实一样的数目
true = np.sum(cancer_target_pred == cancer_target_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', cancer_target_test.shape[0]-true)
print('预测结果准确率为:', true/cancer_target_test.shape[0])
# 代码 6-19
from sklearn.metrics import accuracy_score,precision_score, \
recall_score,f1_score,cohen_kappa_score
print('使用SVM预测breast_cancer数据的准确率为:',
accuracy_score(cancer_target_test,cancer_target_pred))
print('使用SVM预测breast_cancer数据的精确率为:',
precision_score(cancer_target_test,cancer_target_pred))
print('使用SVM预测breast_cancer数据的召回率为:',
recall_score(cancer_target_test,cancer_target_pred))
print('使用SVM预测breast_cancer数据的F1值为:',
f1_score(cancer_target_test,cancer_target_pred))
print('使用SVM预测breast_cancer数据的Cohen’s Kappa系数为:',
cohen_kappa_score(cancer_target_test,cancer_target_pred))
# 代码 6-20
from sklearn.metrics import classification_report
print('使用SVM预测iris数据的分类报告为:','\n',
classification_report(cancer_target_test,
cancer_target_pred))
4、代码运行结果

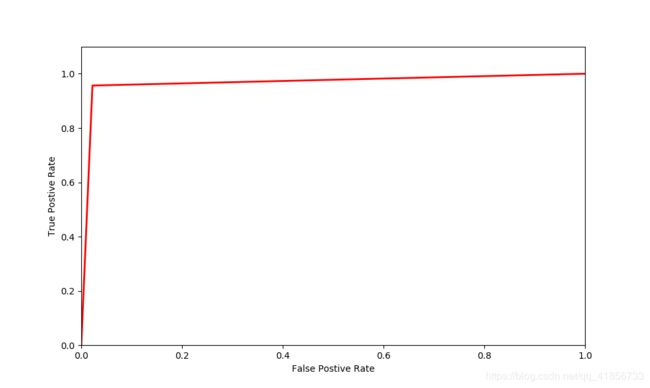
三、绘制ROC曲线
1、这里就不解释了,直接上代码绘图代码
# 代码 6-21
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
## 求出ROC曲线的x轴和y轴
fpr, tpr, thresholds = \
roc_curve(cancer_target_test,cancer_target_pred)
plt.figure(figsize=(10,6))
plt.xlim(0,1) ##设定x轴的范围
plt.ylim(0.0,1.1) ## 设定y轴的范围
plt.xlabel('False Postive Rate')
plt.ylabel('True Postive Rate')
plt.plot(fpr,tpr,linewidth=2, linestyle="-",color='red')
plt.show()
2、绘图效果
3、想到个有意思的
Ipad上notability中的笔记:对比PR曲线和ROC曲线
