模型的偏差和方差
一、偏差与方差
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error。Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
generalization error又可以细分为Bias和Variance两个部分。而bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能变化,即刻画了数据扰动所造成的影响。
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
Bias:偏差描述的是根据样本拟合出的模型的预测结果与样本真实结果的差距,就是预测结果与真实结果的误差。Low Bias,就是增加模型的参数,复杂化模型,但容易过拟合overfiting,对于图中high variance,点分散。
Variance:方差描述的是根据样本训练出来的模型在测试集上的表现。low variance 减少模型参数,简化模型,但容易欠拟合,对应于图纸high bias,点偏离中心。
偏差方差窘境
在下图中,给出了偏差方差和总体的泛化误差的示意图(图片引自Understanding the Bias-Variance Tradeoff ):
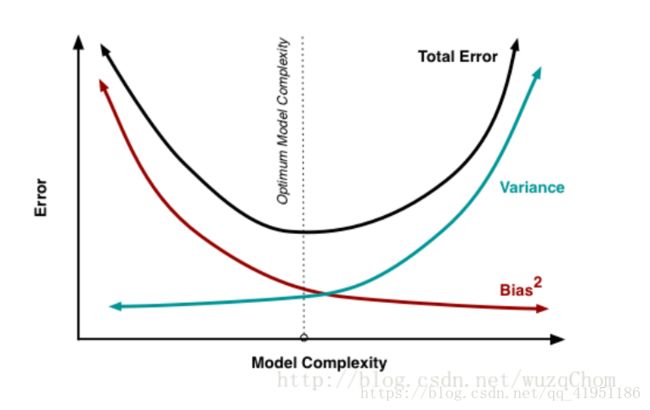
从图中我们可以看出,偏差和方差两者是有冲突的,称之为变差方差窘境(bias-variance dilemma)。
假如学习算法训练不足时,此时学习器的拟合能力不够强,此时数据的扰动不会对结果产生很大的影响(可以想象成由于训练的程度不够,此时学习器指学习到了一些所有的数据都有的一些特征),这个时候偏差主导了算法的泛化能力。随着训练的进行,学习器的拟合能力逐渐增强,变差逐渐减小,但此时不同通过数据学习得到的学习器就可能会有较大的偏差,即此时的方差会主导模型的泛化能力。若学习进一步进行,学习器就可能学到数据集所独有的特征,而这些特征对于其它的数据是不适用的,这个时候就是发生了过拟合的想象。
针对偏差和方差的思路:
偏差:实际上也可以称为避免欠拟合。
1、寻找更好的特征 -- 具有代表性。
2、用更多的特征 -- 增大输入向量的维度。(增加模型复杂度)
方差:避免过拟合
1、增大数据集合 -- 使用更多的数据,噪声点比减少(减少数据扰动所造成的影响(紧扣定义))
2、减少数据特征 -- 减少数据维度,高维空间密度小(减少模型复杂度)
3、正则化方法
4、交叉验证法
2、Bias、Variance和K-fold的关系
K-fold Cross Validation的思想:将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。
通过它的思想,交叉验证相当于增大了数据集合,减少了训练集的变动所导致的学习性能变化,所以解决了方差的问题(数据扰动所造成的影响)。交叉验证后,模型的预测是所有数据训练结果的平均值,这就解决了偏差的问题。
3、Bagging与Boosting与偏差、方差的关系


Bagging和Boosting是集成学习当中比较常用的两种方法,刚好分别对应了降低模型方差和偏差。
Bagging是通过重采样的方法来得到不同的模型,假设模型独立则有:
E(∑iE(Xi)n)=E(Xi)E(∑iE(Xi)n)=E(Xi)
Var(∑iVar(Xi)n)=1nVar(Xi)Var(∑iVar(Xi)n)=1nVar(Xi)
所以从这里我们可以看出Bagging主要可以降低的是方差。
而Boosting每一次都关注使得整理的loss减少,很显然可以降低bias。这里的模型之间并不独立,所以不能显著减少variance,而Bagging假设模型独立所以可以减少variance。
更多内容请参考知乎问题:为什么说bagging是减少variance,而boosting是减少bias? 回答很精彩。
参考资料:
1. 周志华《机器学习》p44-p46
2. Hsuan-Tien Lin. “Learning From Data”. Chapter 2.3
3. Christopher M. Bishop. “Pattern Recognition and Machine Learning” Chapter 3.1
https://www.zhihu.com/question/27068705
https://blog.csdn.net/shenxiaoming77/article/details/53894973
http://www.cnblogs.com/jasonfreak/p/5720137.html
http://www.cnblogs.com/jasonfreak/p/5657196.html