计算智能——基于Kmeans算法与模糊C均值算法实现种子的聚类分析
种子的聚类分析
- 数据来源
https://archive.ics.uci.edu/ml/datasets/seeds
- 问题介绍
本次实验共选取了510条记录,通过整合筛选掉无效记录。将样本种子划分为7个维度进行考量种子的几何特性,分别为
1.种子面积A
2.种子周长P
3.种子紧密度C = 4 * pi * A / P ^ 2,4
4.籽粒长度
5.籽粒宽度
6.不对称系数
7.籽粒槽的长度
如何理解模糊聚类
事物间的界线,有些是明确的,有些则是模糊的。当聚类涉及到事物之间的模糊界线时,需要运用模糊聚类分析方法。
如何理解模糊聚类的“模糊”呢:假设有两个集合分别是A、B,有一成员a,传统的分类概念a要么属于A要么属于B,在模糊聚类的概念中a可以0.3属于A,0.7属于B,这就是其中的“模糊”概念。
模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
系统聚类法个人理解类似于密度聚类算法,逐步聚类法类是中心点聚类法。
逐步聚类法是一种基于模糊划分的模糊聚类分析法。它是预先确定好待分类的样本应分成几类,然后按照最优原则进行在分类,经多次迭代直到分类比较合理为止。在分类过程中可认为某个样本以某一隶属度隶属某一类,又以某一隶属度隶属于另一类。这样,样本就不是明确的属于或不属于某一类。若样本集有n个样本要分成c类,则他的模糊划分矩阵为c×n。
该矩阵有如下特性:
①. 每一样本属于各类的隶属度之和为1。
②. 每一类模糊子集都不是空集。
FCM算法原理

FCM 算法步骤
给定聚类类别数C,设定迭代收敛条件,初始化各个聚类中心;
(1)重复下面的运算,直到各个样本的隶属度值稳定:
(2)用当前的聚类中心根据公式(6) 计算隶属度函数;
A.用当前的隶属度函数根据公式(5) 重新计算各个聚类的中心。
B.当算法收敛时,就得到了各类的聚类中心和各个样本对于各类的隶属度值,从而完成了模糊聚类划分。
实验过程
输入: data: 待聚类数据,n行s列,n为数据个数,s为每个数据的特征数
c : 聚类中心个数
m : 模糊系数
输出: U : 隶属度矩阵,c行n列,元素uij表示第j个数据隶属于第i类的程度
V : 聚类中心向量,c行s列,有c个中心,每个中心有s维特征
T :迭代次数
epsm :收敛精度
m :模糊系数
实验代码
T=50;
c=8;
m=2;
data=seedsdataset;
[U, V]=myfcm(data, c, T, m, epsm);
function [U, V,objFcn] = myfcm(data, c, T, m, epsm)
if nargin < 3
T = 100;
end
if nargin < 5
epsm = 1.0e-6;
end
if nargin < 4
m = 2;
end
[n, s] = size(data);
U0 = rand(c, n);
temp = sum(U0,1);
for i=1:n
U0(:,i) = U0(:,i)./temp(i);
end
iter = 0;
V(c,s) = 0; U(c,n) = 0; distance(c,n) = 0;
while( iter实验结果

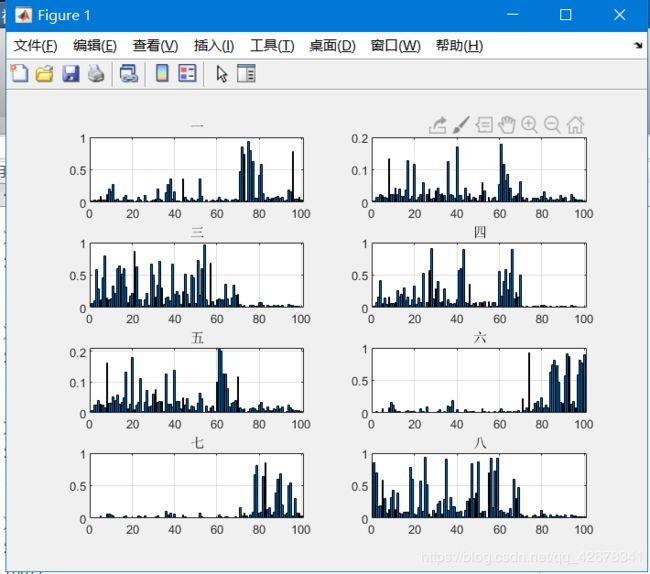
将种子划分为8个类别,其中横坐标为样本数,纵坐标为隶属度矩阵值




Kmeans算法
算法原理
K-means聚类算法 也称K均值聚类算法 是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
实验过程
由于matlab中含有自带的kmeans函数,所以只要进行调用即可
X=seedsdataset;
[x,y]=size(X);
opts = statset('Display','final');
K=6;
repN=50;
[Idx,Ctrs,SumD,D] = kmeans(X,K,'Replicates',repN,'Options',opts);
fprintf('将种子的种类划分成%d类:\n',K)
for i=1:K
tm=find(Idx==i);
tm=reshape(tm,1,length(tm));
fprintf('种子%d类 (共%d个)\n[%s]\n',i,length(tm),int2str(tm));
end
实验结果
-
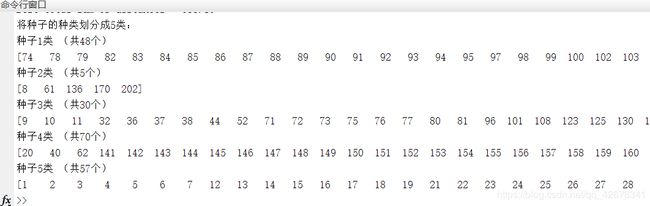
将种子划分为5类,实验5次



-
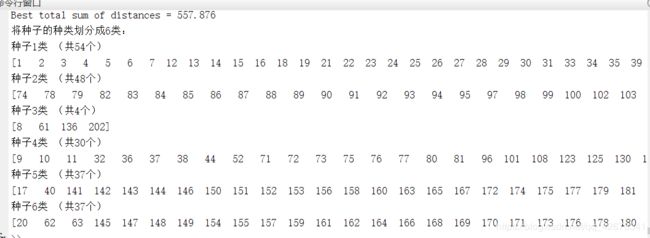
将种子划分为6类,实验5次




结果分析
K-Means聚类算法的优点主要集中在:
1.算法快速、简单;
2.对大数据集有较高的效率并且是可伸缩性的;
3.时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
K-Means聚类算法的缺点:
① 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是 K-means 算法的一个不足。
② 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
③ 从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。